 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealistic Data Generation for 6D Pose Estimation of Surgical Instruments
Jun 11, 2024



Automation in surgical robotics has the potential to improve patient safety and surgical efficiency, but it is difficult to achieve due to the need for robust perception algorithms. In particular, 6D pose estimation of surgical instruments is critical to enable the automatic execution of surgical maneuvers based on visual feedback. In recent years, supervised deep learning algorithms have shown increasingly better performance at 6D pose estimation tasks; yet, their success depends on the availability of large amounts of annotated data. In household and industrial settings, synthetic data, generated with 3D computer graphics software, has been shown as an alternative to minimize annotation costs of 6D pose datasets. However, this strategy does not translate well to surgical domains as commercial graphics software have limited tools to generate images depicting realistic instrument-tissue interactions. To address these limitations, we propose an improved simulation environment for surgical robotics that enables the automatic generation of large and diverse datasets for 6D pose estimation of surgical instruments. Among the improvements, we developed an automated data generation pipeline and an improved surgical scene. To show the applicability of our system, we generated a dataset of 7.5k images with pose annotations of a surgical needle that was used to evaluate a state-of-the-art pose estimation network. The trained model obtained a mean translational error of 2.59mm on a challenging dataset that presented varying levels of occlusion. These results highlight our pipeline's success in training and evaluating novel vision algorithms for surgical robotics applications.
* 6 pages
CaRTS: Causality-driven Robot Tool Segmentation from Vision and Kinematics Data
Apr 06, 2022

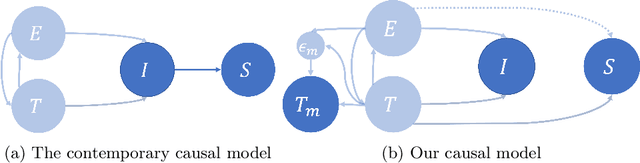

Vision-based segmentation of the robotic tool during robot-assisted surgery enables downstream applications, such as augmented reality feedback, while allowing for inaccuracies in robot kinematics. With the introduction of deep learning, many methods were presented to solve instrument segmentation directly and solely from images. While these approaches made remarkable progress on benchmark datasets, fundamental challenges pertaining to their robustness remain. We present CaRTS, a causality-driven robot tool segmentation algorithm, that is designed based on a complementary causal model of the robot tool segmentation task. Rather than directly inferring segmentation masks from observed images, CaRTS iteratively aligns tool models with image observations by updating the initially incorrect robot kinematic parameters through forward kinematics and differentiable rendering to optimize image feature similarity end-to-end. We benchmark CaRTS with competing techniques on both synthetic as well as real data from the dVRK, generated in precisely controlled scenarios to allow for counterfactual synthesis. On training-domain test data, CaRTS achieves a Dice score of 93.4 that is preserved well (Dice score of 91.8) when tested on counterfactual altered test data, exhibiting low brightness, smoke, blood, and altered background patterns. This compares favorably to Dice scores of 95.0 and 62.8, respectively, of a purely image-based method trained and tested on the same data. Future work will involve accelerating CaRTS to achieve video framerate and estimating the impact occlusion has in practice. Despite these limitations, our results are promising: In addition to achieving high segmentation accuracy, CaRTS provides estimates of the true robot kinematics, which may benefit applications such as force estimation.