 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinite-Agent Stochastic Differential Games on Large Graphs: II. Graph-Based Architectures
Sep 15, 2025We propose a novel neural network architecture, called Non-Trainable Modification (NTM), for computing Nash equilibria in stochastic differential games (SDGs) on graphs. These games model a broad class of graph-structured multi-agent systems arising in finance, robotics, energy, and social dynamics, where agents interact locally under uncertainty. The NTM architecture imposes a graph-guided sparsification on feedforward neural networks, embedding fixed, non-trainable components aligned with the underlying graph topology. This design enhances interpretability and stability, while significantly reducing the number of trainable parameters in large-scale, sparse settings. We theoretically establish a universal approximation property for NTM in static games on graphs and numerically validate its expressivity and robustness through supervised learning tasks. Building on this foundation, we incorporate NTM into two state-of-the-art game solvers, Direct Parameterization and Deep BSDE, yielding their sparse variants (NTM-DP and NTM-DBSDE). Numerical experiments on three SDGs across various graph structures demonstrate that NTM-based methods achieve performance comparable to their fully trainable counterparts, while offering improved computational efficiency.
A Duality Analysis of Kernel Ridge Regression in the Noiseless Regime
Feb 24, 2024In this paper, we conduct a comprehensive analysis of generalization properties of Kernel Ridge Regression (KRR) in the noiseless regime, a scenario crucial to scientific computing, where data are often generated via computer simulations. We prove that KRR can attain the minimax optimal rate, which depends on both the eigenvalue decay of the associated kernel and the relative smoothness of target functions. Particularly, when the eigenvalue decays exponentially fast, KRR achieves the spectral accuracy, i.e., a convergence rate faster than any polynomial. Moreover, the numerical experiments well corroborate our theoretical findings. Our proof leverages a novel extension of the duality framework introduced by Chen et al. (2023), which could be useful in analyzing kernel-based methods beyond the scope of this work.
Learning Free Terminal Time Optimal Closed-loop Control of Manipulators
Nov 29, 2023



This paper presents a novel approach to learning free terminal time closed-loop control for robotic manipulation tasks, enabling dynamic adjustment of task duration and control inputs to enhance performance. We extend the supervised learning approach, namely solving selected optimal open-loop problems and utilizing them as training data for a policy network, to the free terminal time scenario. Three main challenges are addressed in this extension. First, we introduce a marching scheme that enhances the solution quality and increases the success rate of the open-loop solver by gradually refining time discretization. Second, we extend the QRnet in Nakamura-Zimmerer et al. (2021b) to the free terminal time setting to address discontinuity and improve stability at the terminal state. Third, we present a more automated version of the initial value problem (IVP) enhanced sampling method from previous work (Zhang et al., 2022) to adaptively update the training dataset, significantly improving its quality. By integrating these techniques, we develop a closed-loop policy that operates effectively over a broad domain with varying optimal time durations, achieving near globally optimal total costs.
The $L^\infty$ Learnability of Reproducing Kernel Hilbert Spaces
Jun 05, 2023In this work, we analyze the learnability of reproducing kernel Hilbert spaces (RKHS) under the $L^\infty$ norm, which is critical for understanding the performance of kernel methods and random feature models in safety- and security-critical applications. Specifically, we relate the $L^\infty$ learnability of a RKHS to the spectrum decay of the associate kernel and both lower bounds and upper bounds of the sample complexity are established. In particular, for dot-product kernels on the sphere, we identify conditions when the $L^\infty$ learning can be achieved with polynomial samples. Let $d$ denote the input dimension and assume the kernel spectrum roughly decays as $\lambda_k\sim k^{-1-\beta}$ with $\beta>0$. We prove that if $\beta$ is independent of the input dimension $d$, then functions in the RKHS can be learned efficiently under the $L^\infty$ norm, i.e., the sample complexity depends polynomially on $d$. In contrast, if $\beta=1/\mathrm{poly}(d)$, then the $L^\infty$ learning requires exponentially many samples.
A duality framework for generalization analysis of random feature models and two-layer neural networks
May 09, 2023We consider the problem of learning functions in the $\mathcal{F}_{p,\pi}$ and Barron spaces, which are natural function spaces that arise in the high-dimensional analysis of random feature models (RFMs) and two-layer neural networks. Through a duality analysis, we reveal that the approximation and estimation of these spaces can be considered equivalent in a certain sense. This enables us to focus on the easier problem of approximation and estimation when studying the generalization of both models. The dual equivalence is established by defining an information-based complexity that can effectively control estimation errors. Additionally, we demonstrate the flexibility of our duality framework through comprehensive analyses of two concrete applications. The first application is to study learning functions in $\mathcal{F}_{p,\pi}$ with RFMs. We prove that the learning does not suffer from the curse of dimensionality as long as $p>1$, implying RFMs can work beyond the kernel regime. Our analysis extends existing results [CMM21] to the noisy case and removes the requirement of overparameterization. The second application is to investigate the learnability of reproducing kernel Hilbert space (RKHS) under the $L^\infty$ metric. We derive both lower and upper bounds of the minimax estimation error by using the spectrum of the associated kernel. We then apply these bounds to dot-product kernels and analyze how they scale with the input dimension. Our results suggest that learning with ReLU (random) features is generally intractable in terms of reaching high uniform accuracy.
Reinforcement Learning with Function Approximation: From Linear to Nonlinear
Feb 20, 2023Function approximation has been an indispensable component in modern reinforcement learning algorithms designed to tackle problems with large state space in high dimensions. This paper reviews the recent results on the error analysis of those reinforcement learning algorithms in the settings of linear or nonlinear approximation, with an emphasis on the approximation error and the estimation error/sample complexity. We discuss different properties related to the approximation error and concrete conditions on the transition probability and reward function under which these properties hold true. The sample complexity in reinforcement learning is more complicated for analysis compared to supervised learning, mainly due to the distribution mismatch phenomenon. With assumptions on the linear structure of the problem, there are various algorithms in the literature that can achieve polynomial sample complexity with respect to the number of features, episode length, and accuracy, although the minimax rate has not been achieved yet. These results rely on the $L^\infty$ and UCB estimation of estimation error, which can handle the distribution mismatch phenomenon. The problem and analysis become much more challenging in the setting of nonlinear function approximation since both $L^\infty$ and UCB estimation are inadequate to help bound the error with a good rate in high dimensions. We discuss different additional assumptions needed to handle the distribution mismatch and derive meaningful results for nonlinear RL problems.
Learning High-Dimensional McKean-Vlasov Forward-Backward Stochastic Differential Equations with General Distribution Dependence
Apr 25, 2022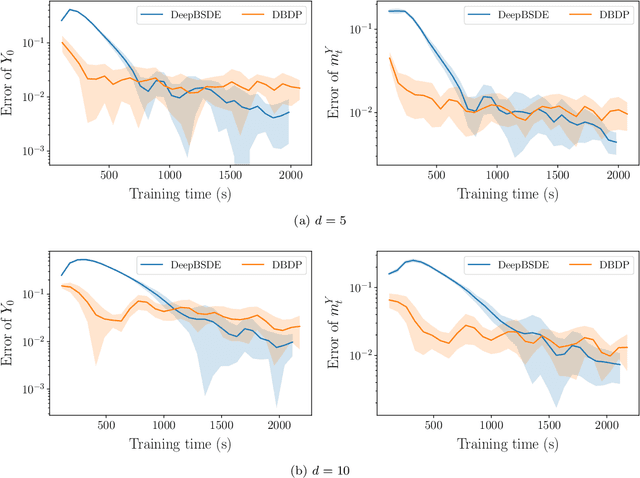
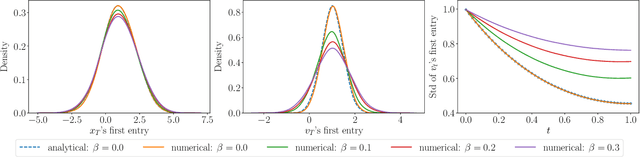
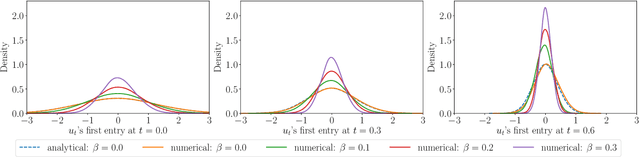
One of the core problems in mean-field control and mean-field games is to solve the corresponding McKean-Vlasov forward-backward stochastic differential equations (MV-FBSDEs). Most existing methods are tailored to special cases in which the mean-field interaction only depends on expectation or other moments and thus inadequate to solve problems when the mean-field interaction has full distribution dependence. In this paper, we propose a novel deep learning method for computing MV-FBSDEs with a general form of mean-field interactions. Specifically, built on fictitious play, we recast the problem into repeatedly solving standard FBSDEs with explicit coefficient functions. These coefficient functions are used to approximate the MV-FBSDEs' model coefficients with full distribution dependence, and are updated by solving another supervising learning problem using training data simulated from the last iteration's FBSDE solutions. We use deep neural networks to solve standard BSDEs and approximate coefficient functions in order to solve high-dimensional MV-FBSDEs. Under proper assumptions on the learned functions, we prove that the convergence of the proposed method is free of the curse of dimensionality (CoD) by using the generalized maximum mean discrepancy metric previously developed in [Han, Hu and Long, arXiv:2104.12036]. The proved theorem shows the advantage of the method in high dimensions. We present the numerical performance in high-dimensional MV-FBSDE problems, including a mean-field game example of the well-known Cucker-Smale model whose cost depends on the full distribution of the forward process.
Perturbational Complexity by Distribution Mismatch: A Systematic Analysis of Reinforcement Learning in Reproducing Kernel Hilbert Space
Nov 05, 2021Most existing theoretical analysis of reinforcement learning (RL) is limited to the tabular setting or linear models due to the difficulty in dealing with function approximation in high dimensional space with an uncertain environment. This work offers a fresh perspective into this challenge by analyzing RL in a general reproducing kernel Hilbert space (RKHS). We consider a family of Markov decision processes $\mathcal{M}$ of which the reward functions lie in the unit ball of an RKHS and transition probabilities lie in a given arbitrary set. We define a quantity called perturbational complexity by distribution mismatch $\Delta_{\mathcal{M}}(\epsilon)$ to characterize the complexity of the admissible state-action distribution space in response to a perturbation in the RKHS with scale $\epsilon$. We show that $\Delta_{\mathcal{M}}(\epsilon)$ gives both the lower bound of the error of all possible algorithms and the upper bound of two specific algorithms (fitted reward and fitted Q-iteration) for the RL problem. Hence, the decay of $\Delta_\mathcal{M}(\epsilon)$ with respect to $\epsilon$ measures the difficulty of the RL problem on $\mathcal{M}$. We further provide some concrete examples and discuss whether $\Delta_{\mathcal{M}}(\epsilon)$ decays fast or not in these examples. As a byproduct, we show that when the reward functions lie in a high dimensional RKHS, even if the transition probability is known and the action space is finite, it is still possible for RL problems to suffer from the curse of dimensionality.
Linear approximability of two-layer neural networks: A comprehensive analysis based on spectral decay
Aug 10, 2021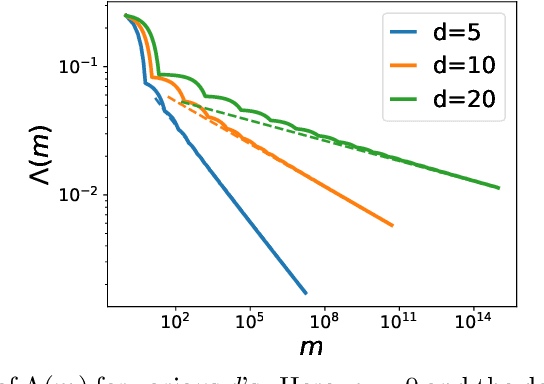
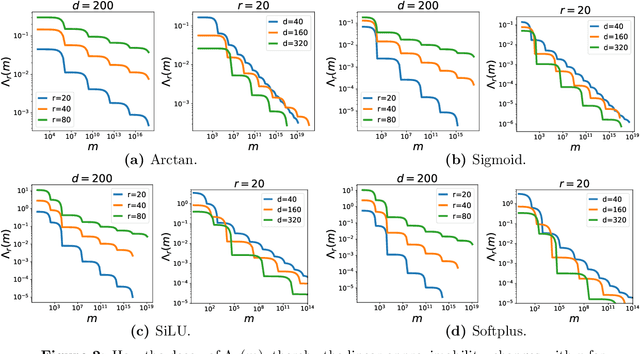
In this paper, we present a spectral-based approach to study the linear approximation of two-layer neural networks. We first consider the case of single neuron and show that the linear approximability, quantified by the Kolmogorov width, is controlled by the eigenvalue decay of an associate kernel. Then, we show that similar results also hold for two-layer neural networks. This spectral-based approach allows us to obtain upper bounds, lower bounds, and explicit hard examples in a united manner. In particular, these bounds imply that for networks activated by smooth functions, restricting the norms of inner-layer weights may significantly impair the expressiveness. By contrast, for non-smooth activation functions, such as ReLU, the network expressiveness is independent of the inner-layer weight norms. In addition, we prove that for a family of non-smooth activation functions, including ReLU, approximating any single neuron with random features suffers from the \emph{curse of dimensionality}. This provides an explicit separation of expressiveness between neural networks and random feature models.
A Class of Dimensionality-free Metrics for the Convergence of Empirical Measures
Apr 27, 2021This paper concerns the convergence of empirical measures in high dimensions. We propose a new class of metrics and show that under such metrics, the convergence is free of the curse of dimensionality (CoD). Such a feature is critical for high-dimensional analysis and stands in contrast to classical metrics ({\it e.g.}, the Wasserstein distance). The proposed metrics originate from the maximum mean discrepancy, which we generalize by proposing specific criteria for selecting test function spaces to guarantee the property of being free of CoD. Therefore, we call this class of metrics the generalized maximum mean discrepancy (GMMD). Examples of the selected test function spaces include the reproducing kernel Hilbert space, Barron space, and flow-induced function spaces. Three applications of the proposed metrics are presented: 1. The convergence of empirical measure in the case of random variables; 2. The convergence of $n$-particle system to the solution to McKean-Vlasov stochastic differential equation; 3. The construction of an $\varepsilon$-Nash equilibrium for a homogeneous $n$-player game by its mean-field limit. As a byproduct, we prove that, given a distribution close to the target distribution measured by GMMD and a certain representation of the target distribution, we can generate a distribution close to the target one in terms of the Wasserstein distance and relative entropy. Overall, we show that the proposed class of metrics is a powerful tool to analyze the convergence of empirical measures in high dimensions without CoD.