 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoRA: Geometry-Aware Low-Rank Adaptation for RLVR
Jan 14, 2026Reinforcement Learning with Verifiable Rewards (RLVR) is crucial for advancing large-scale reasoning models. However, existing parameter-efficient methods, such as PiSSA and MiLoRA, are designed for Supervised Fine-Tuning (SFT) and do not account for the distinct optimization dynamics and geometric structures of RLVR. Applying these methods directly leads to spectral collapse and optimization instability, which severely limit model performance. Meanwhile, alternative approaches that leverage update sparsity encounter significant efficiency bottlenecks on modern hardware due to unstructured computations. To address these challenges, we propose GeoRA (Geometry-Aware Low-Rank Adaptation), which exploits the anisotropic and compressible nature of RL update subspaces. GeoRA initializes adapters by extracting principal directions via Singular Value Decomposition (SVD) within a geometrically constrained subspace while freezing the residual components. This method preserves the pre-trained geometric structure and enables efficient GPU computation through dense operators. Experiments on Qwen and Llama demonstrate that GeoRA mitigates optimization bottlenecks caused by geometric misalignment. It consistently outperforms established low-rank baselines on key mathematical benchmarks, achieving state-of-the-art (SOTA) results. Moreover, GeoRA shows superior generalization and resilience to catastrophic forgetting in out-of-domain tasks.
Long-term Task-oriented Agent: Proactive Long-term Intent Maintenance in Dynamic Environments
Jan 14, 2026Current large language model agents predominantly operate under a reactive paradigm, responding only to immediate user queries within short-term sessions. This limitation hinders their ability to maintain long-term user's intents and dynamically adapt to evolving external environments. In this paper, we propose a novel interaction paradigm for proactive Task-oriented Agents capable of bridging the gap between relatively static user's needs and a dynamic environment. We formalize proactivity through two key capabilities, (i) Intent-Conditioned Monitoring: The agent autonomously formulates trigger conditions based on dialog history; (ii) Event-Triggered Follow-up: The agent actively engages the user upon detecting useful environmental updates. We introduce a high-quality data synthesis pipeline to construct complex, multi-turn dialog data in a dynamic environment. Furthermore, we attempt to address the lack of evaluation criteria of task-oriented interaction in a dynamic environment by proposing a new benchmark, namely ChronosBench. We evaluated some leading close-source and open-source models at present and revealed their flaws in long-term task-oriented interaction. Furthermore, our fine-tuned model trained using synthetic data for supervised learning achieves a task completion rate of 85.19% for complex tasks including shifts in user intent, outperforming other models under test. And the result validated the effectiveness of our data-driven strategy.
Factor Decomposed Generative Adversarial Networks for Text-to-Image Synthesis
Mar 24, 2023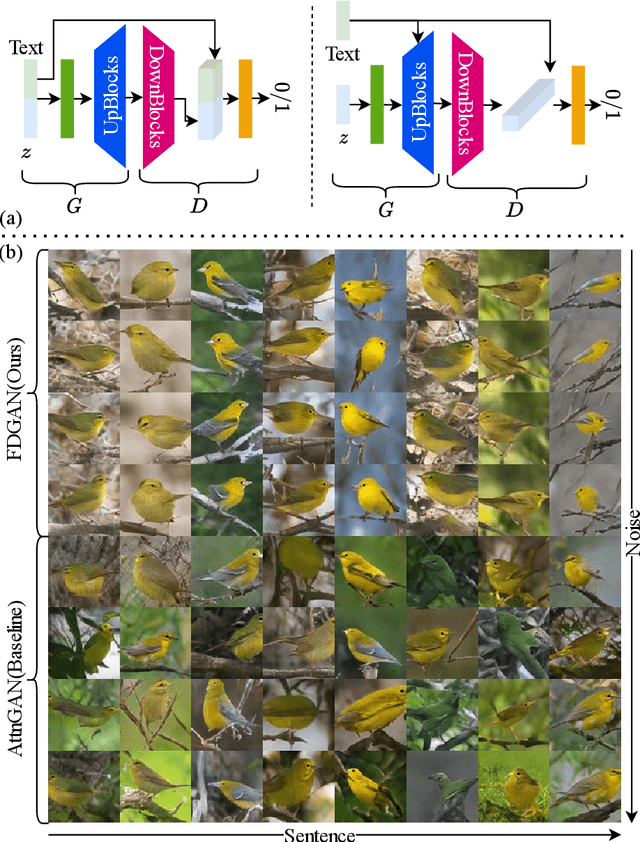

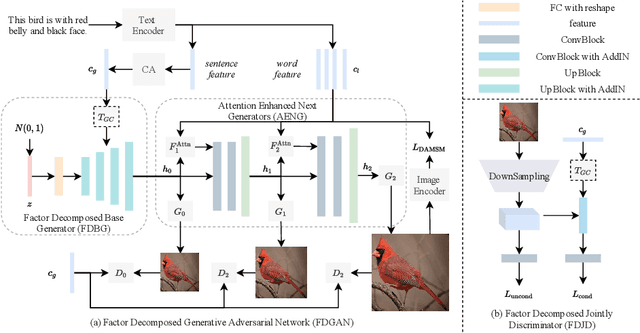

Prior works about text-to-image synthesis typically concatenated the sentence embedding with the noise vector, while the sentence embedding and the noise vector are two different factors, which control the different aspects of the generation. Simply concatenating them will entangle the latent factors and encumber the generative model. In this paper, we attempt to decompose these two factors and propose Factor Decomposed Generative Adversarial Networks~(FDGAN). To achieve this, we firstly generate images from the noise vector and then apply the sentence embedding in the normalization layer for both generator and discriminators. We also design an additive norm layer to align and fuse the text-image features. The experimental results show that decomposing the noise and the sentence embedding can disentangle latent factors in text-to-image synthesis, and make the generative model more efficient. Compared with the baseline, FDGAN can achieve better performance, while fewer parameters are used.
Time-frequency Network for Robust Speaker Recognition
Mar 07, 2023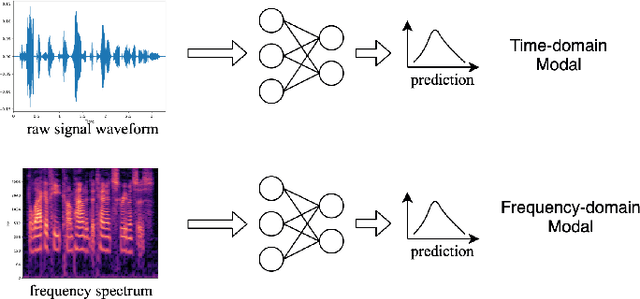
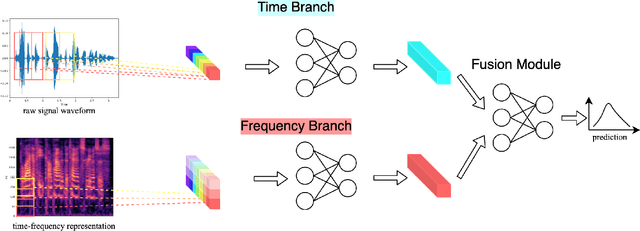
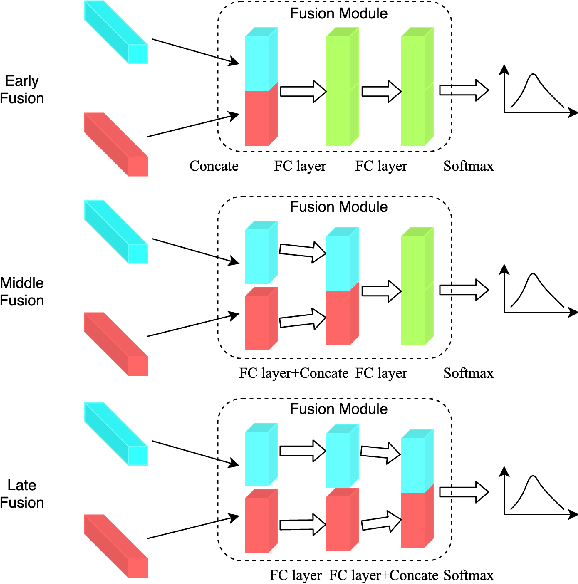
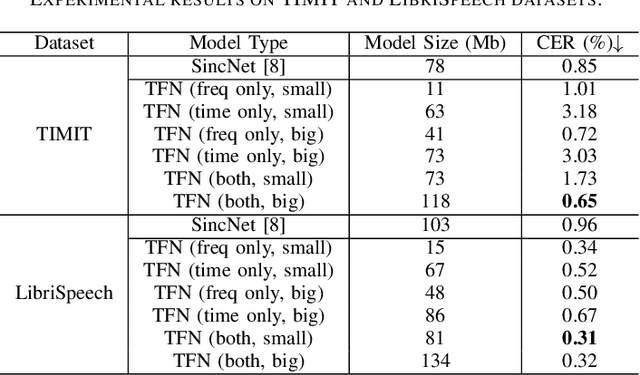
The wide deployment of speech-based biometric systems usually demands high-performance speaker recognition algorithms. However, most of the prior works for speaker recognition either process the speech in the frequency domain or time domain, which may produce suboptimal results because both time and frequency domains are important for speaker recognition. In this paper, we attempt to analyze the speech signal in both time and frequency domains and propose the time-frequency network~(TFN) for speaker recognition by extracting and fusing the features in the two domains. Based on the recent advance of deep neural networks, we propose a convolution neural network to encode the raw speech waveform and the frequency spectrum into domain-specific features, which are then fused and transformed into a classification feature space for speaker recognition. Experimental results on the publicly available datasets TIMIT and LibriSpeech show that our framework is effective to combine the information in the two domains and performs better than the state-of-the-art methods for speaker recognition.
Cross Modal Compression: Towards Human-comprehensible Semantic Compression
Sep 06, 2022



Traditional image/video compression aims to reduce the transmission/storage cost with signal fidelity as high as possible. However, with the increasing demand for machine analysis and semantic monitoring in recent years, semantic fidelity rather than signal fidelity is becoming another emerging concern in image/video compression. With the recent advances in cross modal translation and generation, in this paper, we propose the cross modal compression~(CMC), a semantic compression framework for visual data, to transform the high redundant visual data~(such as image, video, etc.) into a compact, human-comprehensible domain~(such as text, sketch, semantic map, attributions, etc.), while preserving the semantic. Specifically, we first formulate the CMC problem as a rate-distortion optimization problem. Secondly, we investigate the relationship with the traditional image/video compression and the recent feature compression frameworks, showing the difference between our CMC and these prior frameworks. Then we propose a novel paradigm for CMC to demonstrate its effectiveness. The qualitative and quantitative results show that our proposed CMC can achieve encouraging reconstructed results with an ultrahigh compression ratio, showing better compression performance than the widely used JPEG baseline.