 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed multi-agent target search and tracking with Gaussian process and reinforcement learning
Aug 29, 2023Deploying multiple robots for target search and tracking has many practical applications, yet the challenge of planning over unknown or partially known targets remains difficult to address. With recent advances in deep learning, intelligent control techniques such as reinforcement learning have enabled agents to learn autonomously from environment interactions with little to no prior knowledge. Such methods can address the exploration-exploitation tradeoff of planning over unknown targets in a data-driven manner, eliminating the reliance on heuristics typical of traditional approaches and streamlining the decision-making pipeline with end-to-end training. In this paper, we propose a multi-agent reinforcement learning technique with target map building based on distributed Gaussian process. We leverage the distributed Gaussian process to encode belief over the target locations and efficiently plan over unknown targets. We evaluate the performance and transferability of the trained policy in simulation and demonstrate the method on a swarm of micro unmanned aerial vehicles with hardware experiments.
* 10 pages, 6 figures; preprint submitted to IJCAS; first two authors contributed equally
Demonstration-free Autonomous Reinforcement Learning via Implicit and Bidirectional Curriculum
May 17, 2023While reinforcement learning (RL) has achieved great success in acquiring complex skills solely from environmental interactions, it assumes that resets to the initial state are readily available at the end of each episode. Such an assumption hinders the autonomous learning of embodied agents due to the time-consuming and cumbersome workarounds for resetting in the physical world. Hence, there has been a growing interest in autonomous RL (ARL) methods that are capable of learning from non-episodic interactions. However, existing works on ARL are limited by their reliance on prior data and are unable to learn in environments where task-relevant interactions are sparse. In contrast, we propose a demonstration-free ARL algorithm via Implicit and Bi-directional Curriculum (IBC). With an auxiliary agent that is conditionally activated upon learning progress and a bidirectional goal curriculum based on optimal transport, our method outperforms previous methods, even the ones that leverage demonstrations.
DHRL: A Graph-Based Approach for Long-Horizon and Sparse Hierarchical Reinforcement Learning
Oct 11, 2022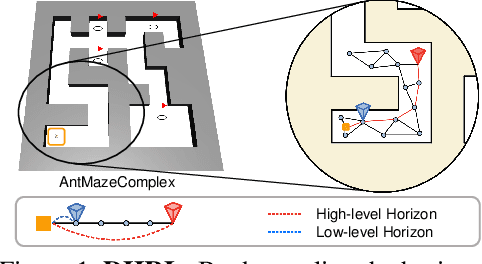

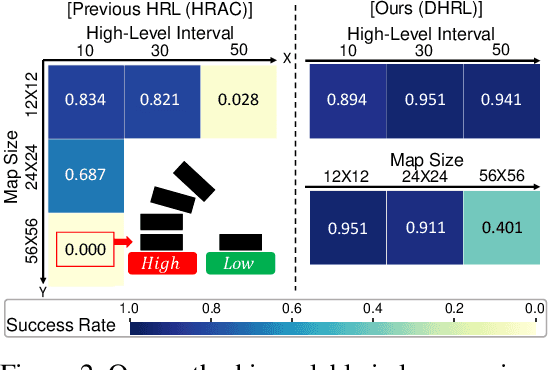

Hierarchical Reinforcement Learning (HRL) has made notable progress in complex control tasks by leveraging temporal abstraction. However, previous HRL algorithms often suffer from serious data inefficiency as environments get large. The extended components, $i.e.$, goal space and length of episodes, impose a burden on either one or both high-level and low-level policies since both levels share the total horizon of the episode. In this paper, we present a method of Decoupling Horizons Using a Graph in Hierarchical Reinforcement Learning (DHRL) which can alleviate this problem by decoupling the horizons of high-level and low-level policies and bridging the gap between the length of both horizons using a graph. DHRL provides a freely stretchable high-level action interval, which facilitates longer temporal abstraction and faster training in complex tasks. Our method outperforms state-of-the-art HRL algorithms in typical HRL environments. Moreover, DHRL achieves long and complex locomotion and manipulation tasks.
Unsupervised Reinforcement Learning for Transferable Manipulation Skill Discovery
Apr 29, 2022
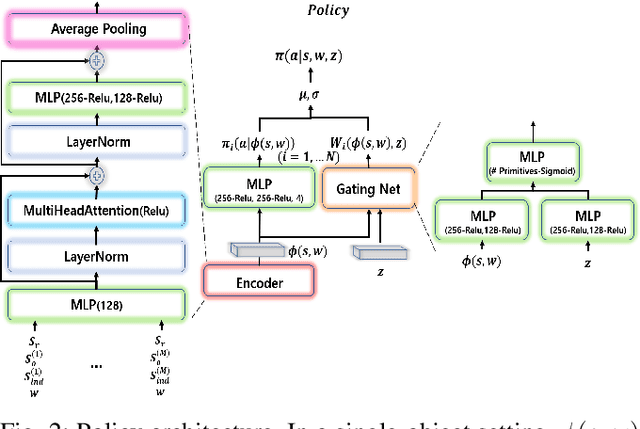
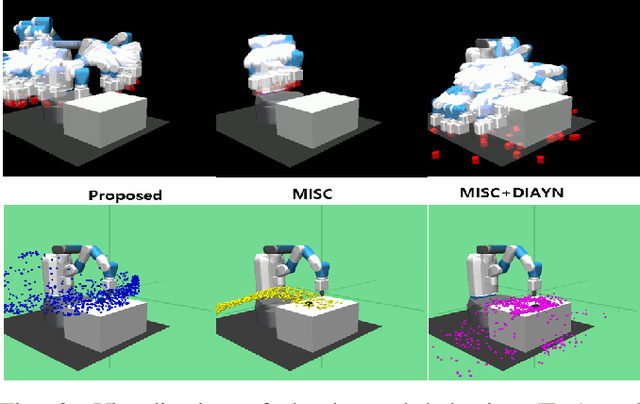
Current reinforcement learning (RL) in robotics often experiences difficulty in generalizing to new downstream tasks due to the innate task-specific training paradigm. To alleviate it, unsupervised RL, a framework that pre-trains the agent in a task-agnostic manner without access to the task-specific reward, leverages active exploration for distilling diverse experience into essential skills or reusable knowledge. For exploiting such benefits also in robotic manipulation, we propose an unsupervised method for transferable manipulation skill discovery that ties structured exploration toward interacting behavior and transferable skill learning. It not only enables the agent to learn interaction behavior, the key aspect of the robotic manipulation learning, without access to the environment reward, but also to generalize to arbitrary downstream manipulation tasks with the learned task-agnostic skills. Through comparative experiments, we show that our approach achieves the most diverse interacting behavior and significantly improves sample efficiency in downstream tasks including the extension to multi-object, multitask problems.
Automating Reinforcement Learning with Example-based Resets
Apr 06, 2022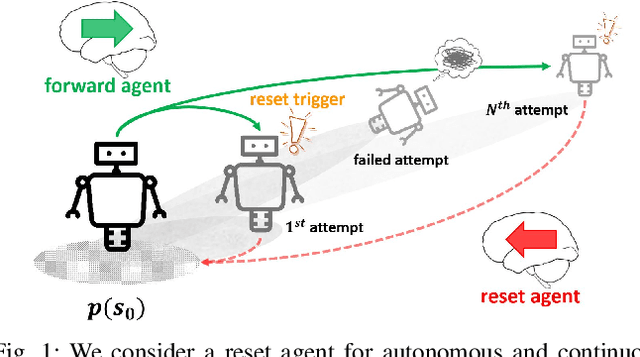
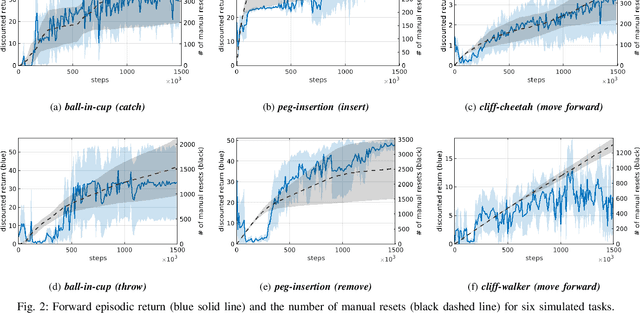
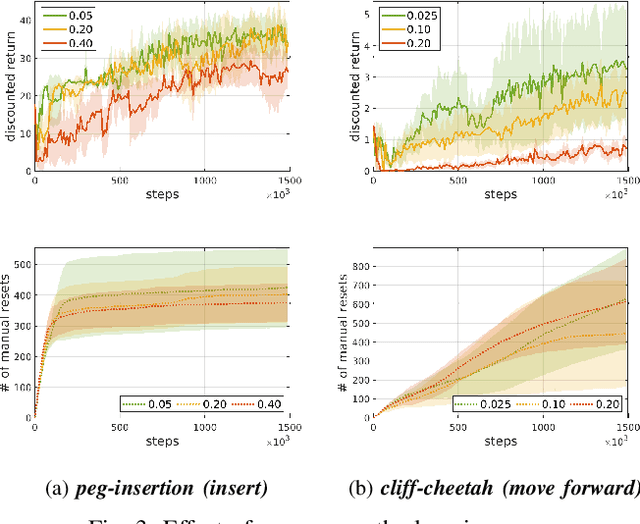
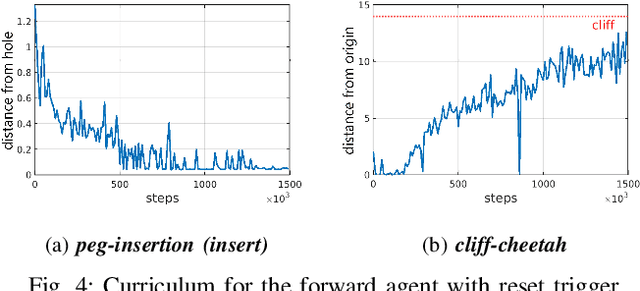
Deep reinforcement learning has enabled robots to learn motor skills from environmental interactions with minimal to no prior knowledge. However, existing reinforcement learning algorithms assume an episodic setting, in which the agent resets to a fixed initial state distribution at the end of each episode, to successfully train the agents from repeated trials. Such reset mechanism, while trivial for simulated tasks, can be challenging to provide for real-world robotics tasks. Resets in robotic systems often require extensive human supervision and task-specific workarounds, which contradicts the goal of autonomous robot learning. In this paper, we propose an extension to conventional reinforcement learning towards greater autonomy by introducing an additional agent that learns to reset in a self-supervised manner. The reset agent preemptively triggers a reset to prevent manual resets and implicitly imposes a curriculum for the forward agent. We apply our method to learn from scratch on a suite of simulated and real-world continuous control tasks and demonstrate that the reset agent successfully learns to reduce manual resets whilst also allowing the forward policy to improve gradually over time.