 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating Reinforcement Learning with Example-based Resets
Apr 06, 2022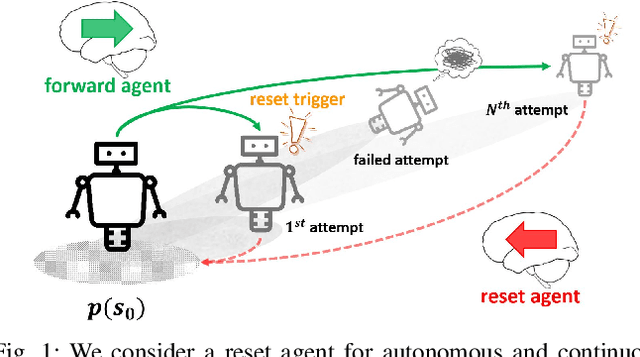
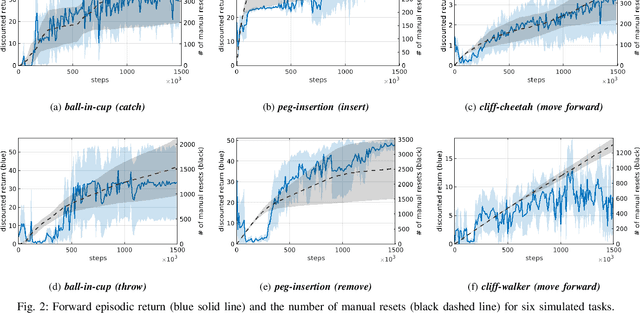
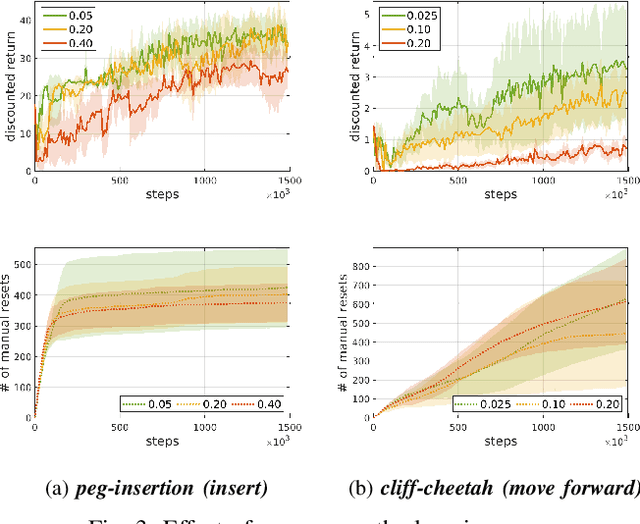
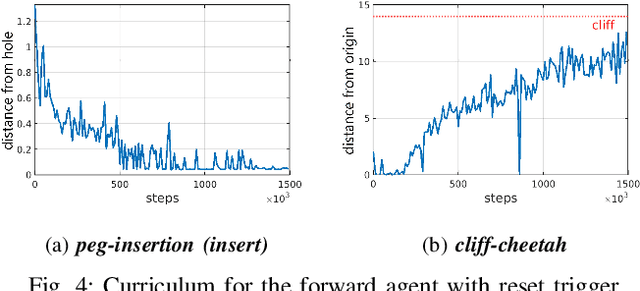
Deep reinforcement learning has enabled robots to learn motor skills from environmental interactions with minimal to no prior knowledge. However, existing reinforcement learning algorithms assume an episodic setting, in which the agent resets to a fixed initial state distribution at the end of each episode, to successfully train the agents from repeated trials. Such reset mechanism, while trivial for simulated tasks, can be challenging to provide for real-world robotics tasks. Resets in robotic systems often require extensive human supervision and task-specific workarounds, which contradicts the goal of autonomous robot learning. In this paper, we propose an extension to conventional reinforcement learning towards greater autonomy by introducing an additional agent that learns to reset in a self-supervised manner. The reset agent preemptively triggers a reset to prevent manual resets and implicitly imposes a curriculum for the forward agent. We apply our method to learn from scratch on a suite of simulated and real-world continuous control tasks and demonstrate that the reset agent successfully learns to reduce manual resets whilst also allowing the forward policy to improve gradually over time.