 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed multi-agent target search and tracking with Gaussian process and reinforcement learning
Aug 29, 2023Deploying multiple robots for target search and tracking has many practical applications, yet the challenge of planning over unknown or partially known targets remains difficult to address. With recent advances in deep learning, intelligent control techniques such as reinforcement learning have enabled agents to learn autonomously from environment interactions with little to no prior knowledge. Such methods can address the exploration-exploitation tradeoff of planning over unknown targets in a data-driven manner, eliminating the reliance on heuristics typical of traditional approaches and streamlining the decision-making pipeline with end-to-end training. In this paper, we propose a multi-agent reinforcement learning technique with target map building based on distributed Gaussian process. We leverage the distributed Gaussian process to encode belief over the target locations and efficiently plan over unknown targets. We evaluate the performance and transferability of the trained policy in simulation and demonstrate the method on a swarm of micro unmanned aerial vehicles with hardware experiments.
* 10 pages, 6 figures; preprint submitted to IJCAS; first two authors contributed equally
Fully Distributed Informative Planning for Environmental Learning with Multi-Robot Systems
Dec 29, 2021
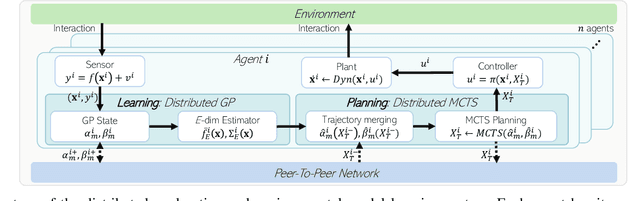
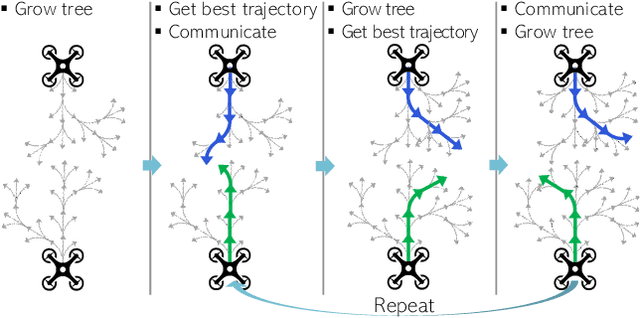
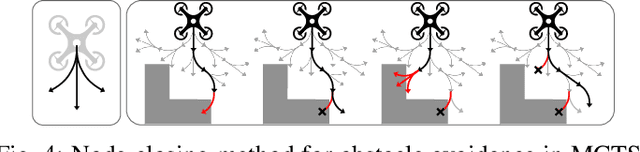
This paper proposes a cooperative environmental learning algorithm working in a fully distributed manner. A multi-robot system is more effective for exploration tasks than a single robot, but it involves the following challenges: 1) online distributed learning of environmental map using multiple robots; 2) generation of safe and efficient exploration path based on the learned map; and 3) maintenance of the scalability with respect to the number of robots. To this end, we divide the entire process into two stages of environmental learning and path planning. Distributed algorithms are applied in each stage and combined through communication between adjacent robots. The environmental learning algorithm uses a distributed Gaussian process, and the path planning algorithm uses a distributed Monte Carlo tree search. As a result, we build a scalable system without the constraint on the number of robots. Simulation results demonstrate the performance and scalability of the proposed system. Moreover, a real-world-dataset-based simulation validates the utility of our algorithm in a more realistic scenario.