 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSODA: Detecting Covid-19 in Chest X-rays with Semi-supervised Open Set Domain Adaptation
May 22, 2020
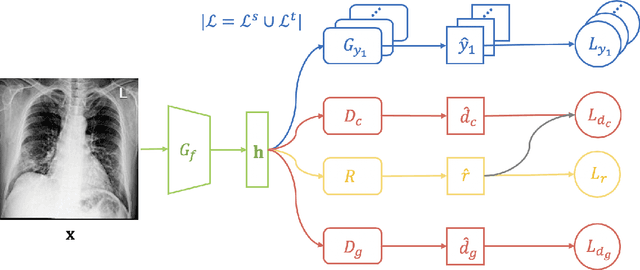
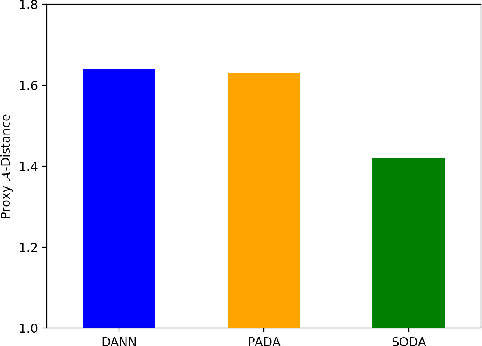
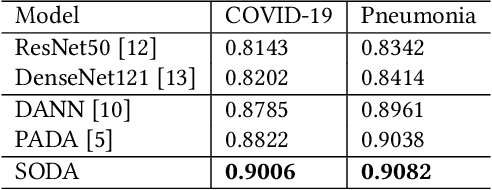
The global pandemic of COVID-19 has infected millions of people since its first outbreak in last December. A key challenge for preventing and controlling COVID-19 is how to quickly, widely, and effectively implement the test for the disease, because testing is the first step to break the chains of transmission. To assist the diagnosis of the disease, radiology imaging is used to complement the screening process and triage patients into different risk levels. Deep learning methods have taken a more active role in automatically detecting COVID-19 disease in chest x-ray images, as witnessed in many recent works. Most of these works first train a CNN on an existing large-scale chest x-ray image dataset and then fine-tune it with a COVID-19 dataset at a much smaller scale. However, direct transfer across datasets from different domains may lead to poor performance due to visual domain shift. Also, the small scale of the COVID-19 dataset on the target domain can make the training fall into the overfitting trap. To solve all these crucial problems and fully exploit the available large-scale chest x-ray image dataset, we formulate the problem of COVID-19 chest x-ray image classification in a semi-supervised open set domain adaptation setting, through which we are motivated to reduce the domain shift and avoid overfitting when training on a very small dataset of COVID-19. In addressing this formulated problem, we propose a novel Semi-supervised Open set Domain Adversarial network (SODA), which is able to align the data distributions across different domains in a general domain space and also in a common subspace of source and target data. In our experiments, SODA achieves a leading classification performance compared with recent state-of-the-art models, as well as effectively separating COVID-19 with common pneumonia.
Analogy Search Engine: Finding Analogies in Cross-Domain Research Papers
Dec 17, 2018
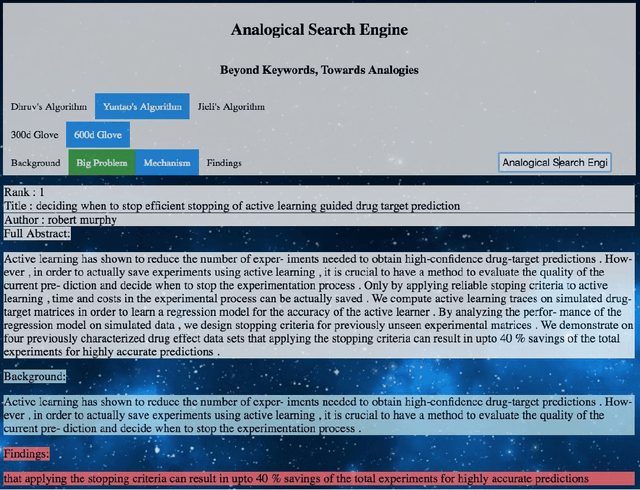
In recent years, with the rapid proliferation of research publications in the field of Artificial Intelligence, it is becoming increasingly difficult for researchers to effectively keep up with all the latest research in one's own domains. However, history has shown that scientific breakthroughs often come from collaborations of researchers from different domains. Traditional search algorithms like Lexical search, which look for literal matches or synonyms and variants of the query words, are not effective for discovering cross-domain research papers and meeting the needs of researchers in this age of information overflow. In this paper, we developed and tested an innovative semantic search engine, Analogy Search Engine (ASE), for 2000 AI research paper abstracts across domains like Language Technologies, Robotics, Machine Learning, Computational Biology, Human Computer Interactions, etc. ASE combines recent theories and methods from Computational Analogy and Natural Language Processing to go beyond keyword-based lexical search and discover the deeper analogical relationships among research paper abstracts. We experimentally show that ASE is capable of finding more interesting and useful research papers than baseline elasticsearch. Furthermore, we believe that the methods used in ASE go beyond academic paper and will benefit many other document search tasks.
Multimodal Machine Translation with Reinforcement Learning
May 07, 2018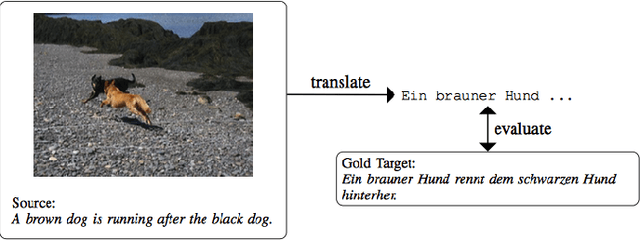
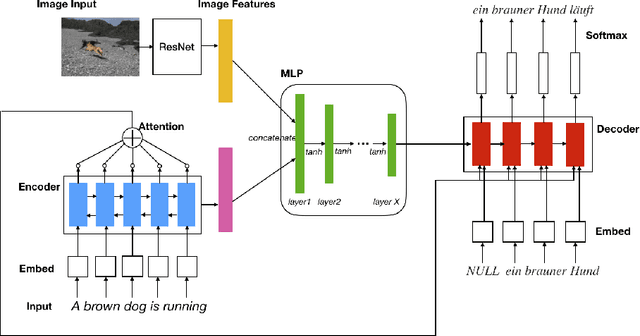
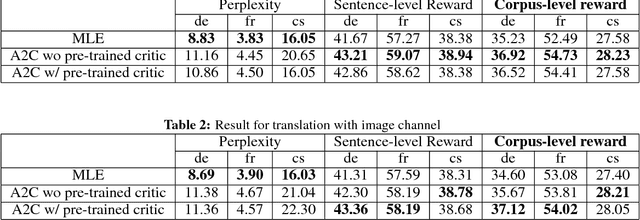
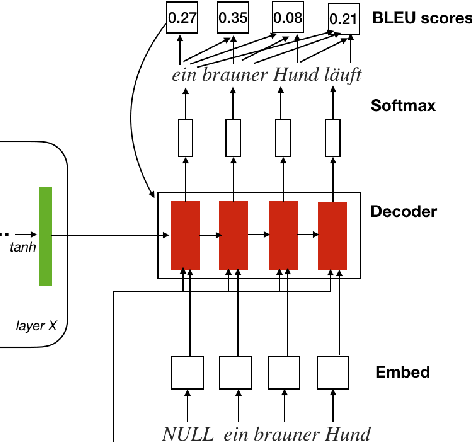
Multimodal machine translation is one of the applications that integrates computer vision and language processing. It is a unique task given that in the field of machine translation, many state-of-the-arts algorithms still only employ textual information. In this work, we explore the effectiveness of reinforcement learning in multimodal machine translation. We present a novel algorithm based on the Advantage Actor-Critic (A2C) algorithm that specifically cater to the multimodal machine translation task of the EMNLP 2018 Third Conference on Machine Translation (WMT18). We experiment our proposed algorithm on the Multi30K multilingual English-German image description dataset and the Flickr30K image entity dataset. Our model takes two channels of inputs, image and text, uses translation evaluation metrics as training rewards, and achieves better results than supervised learning MLE baseline models. Furthermore, we discuss the prospects and limitations of using reinforcement learning for machine translation. Our experiment results suggest a promising reinforcement learning solution to the general task of multimodal sequence to sequence learning.