 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Machine Translation with Reinforcement Learning
Paper and Code
May 07, 2018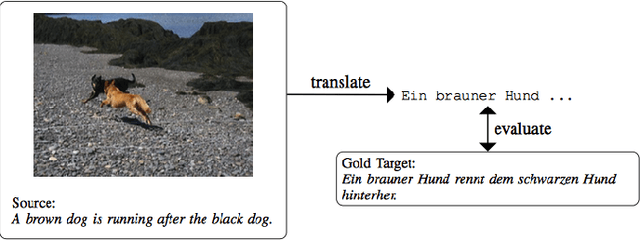
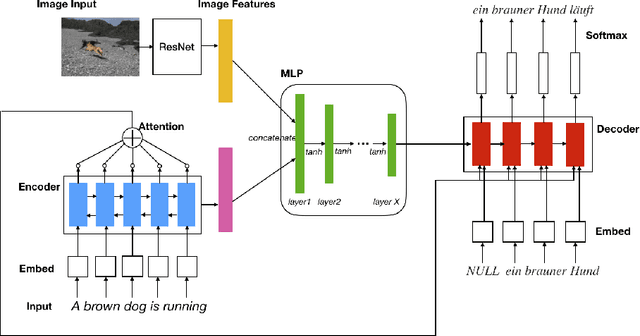
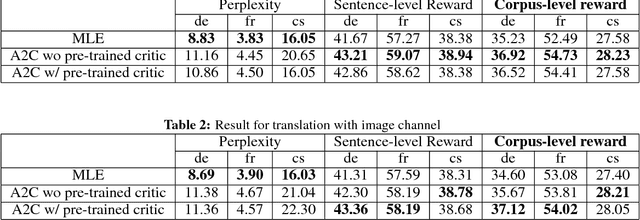
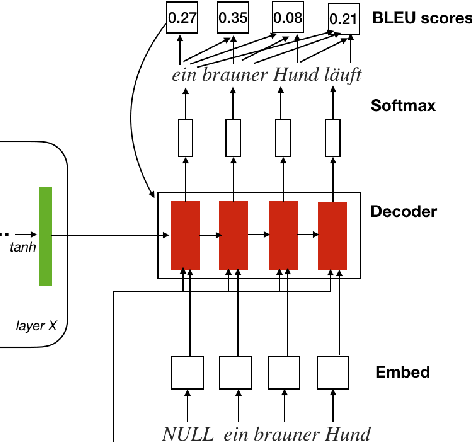
Multimodal machine translation is one of the applications that integrates computer vision and language processing. It is a unique task given that in the field of machine translation, many state-of-the-arts algorithms still only employ textual information. In this work, we explore the effectiveness of reinforcement learning in multimodal machine translation. We present a novel algorithm based on the Advantage Actor-Critic (A2C) algorithm that specifically cater to the multimodal machine translation task of the EMNLP 2018 Third Conference on Machine Translation (WMT18). We experiment our proposed algorithm on the Multi30K multilingual English-German image description dataset and the Flickr30K image entity dataset. Our model takes two channels of inputs, image and text, uses translation evaluation metrics as training rewards, and achieves better results than supervised learning MLE baseline models. Furthermore, we discuss the prospects and limitations of using reinforcement learning for machine translation. Our experiment results suggest a promising reinforcement learning solution to the general task of multimodal sequence to sequence learning.