 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Entailment Tree Generation Approach for Multimodal Multi-Hop Question Answering with Mixture-of-Experts and Iterative Feedback Mechanism
Dec 10, 2024



With the rise of large-scale language models (LLMs), it is currently popular and effective to convert multimodal information into text descriptions for multimodal multi-hop question answering. However, we argue that the current methods of multi-modal multi-hop question answering still mainly face two challenges: 1) The retrieved evidence containing a large amount of redundant information, inevitably leads to a significant drop in performance due to irrelevant information misleading the prediction. 2) The reasoning process without interpretable reasoning steps makes the model difficult to discover the logical errors for handling complex questions. To solve these problems, we propose a unified LLMs-based approach but without heavily relying on them due to the LLM's potential errors, and innovatively treat multimodal multi-hop question answering as a joint entailment tree generation and question answering problem. Specifically, we design a multi-task learning framework with a focus on facilitating common knowledge sharing across interpretability and prediction tasks while preventing task-specific errors from interfering with each other via mixture of experts. Afterward, we design an iterative feedback mechanism to further enhance both tasks by feeding back the results of the joint training to the LLM for regenerating entailment trees, aiming to iteratively refine the potential answer. Notably, our method has won the first place in the official leaderboard of WebQA (since April 10, 2024), and achieves competitive results on MultimodalQA.
* Erratum: We identified an error in the calculation of the F1 score in table 4 reported in a previous version of this work. The performance of the new result is better than the previous one. The corrected values are included in this updated version of the paper. These changes do not alter the primary conclusions of our research
Few-shot Incremental Event Detection
Sep 05, 2022


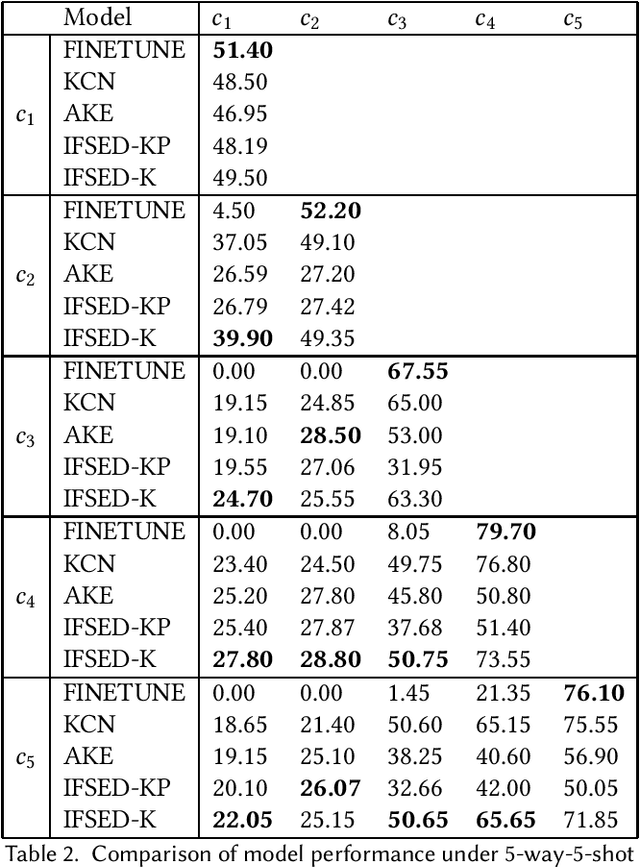
Event detection tasks can help people quickly determine the domain from complex texts. It can also provides powerful support for downstream tasks of natural language processing.Existing methods implement fixed-type learning only based on large amounts of data. When extending to new classes, it is often required to retain the original data and retrain the model.Incremental event detection tasks enables lifelong learning of new classes, but most existing methods need to retain a large number of original data or face the problem of catastrophic forgetting. Apart from that, it is difficult to obtain enough data for model training due to the lack of high-quality data in practical.To address the above problems, we define a new task in the domain of event detection, which is few-shot incremental event detection.This task require that the model should retain previous type when learning new event type in each round with limited input. We recreate and release a benchmark dataset in the few-shot incremental event detection task based on FewEvent.The dataset we published is more appropriate than other in this new task. In addition, we propose two benchmark approaches, IFSED-K and IFSED-KP, which can address the task in different ways. Experiments results have shown that our approach has a higher F1 score and is more stable than baseline.
Chinese Spelling Error Detection Using a Fusion Lattice LSTM
Nov 25, 2019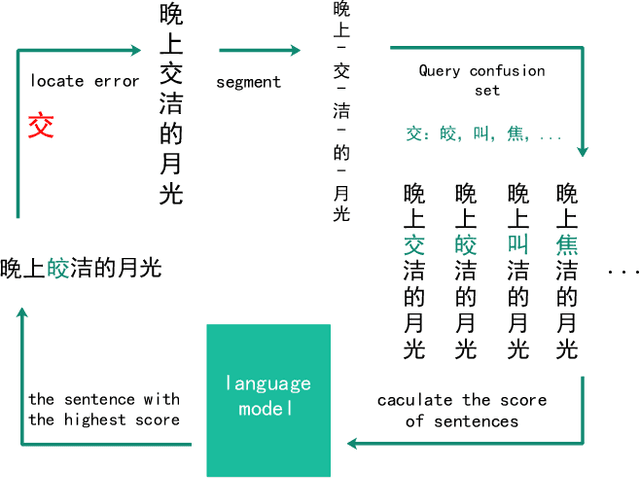
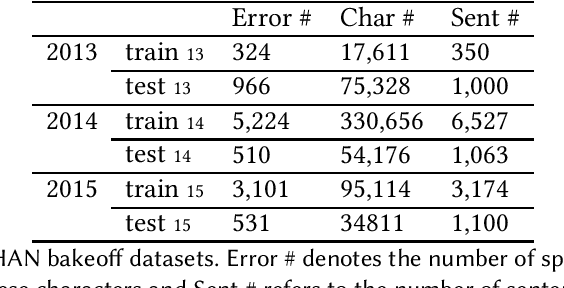
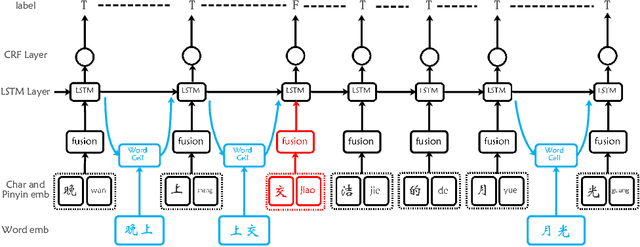
Spelling error detection serves as a crucial preprocessing in many natural language processing applications. Due to the characteristics of Chinese Language, Chinese spelling error detection is more challenging than error detection in English. Existing methods are mainly under a pipeline framework, which artificially divides error detection process into two steps. Thus, these methods bring error propagation and cannot always work well due to the complexity of the language environment. Besides existing methods only adopt character or word information, and ignore the positive effect of fusing character, word, pinyin1 information together. We propose an LF-LSTM-CRF model, which is an extension of the LSTMCRF with word lattices and character-pinyin-fusion inputs. Our model takes advantage of the end-to-end framework to detect errors as a whole process, and dynamically integrates character, word and pinyin information. Experiments on the SIGHAN data show that our LF-LSTM-CRF outperforms existing methods with similar external resources consistently, and confirm the feasibility of adopting the end-to-end framework and the availability of integrating of character, word and pinyin information.