 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Adversarial Training on Contextualized Language Representation
May 08, 2023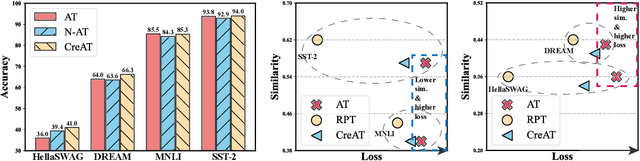
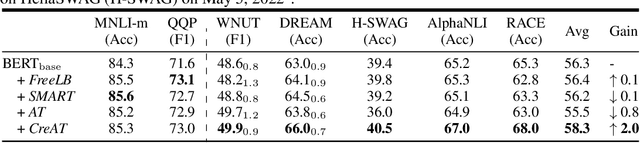
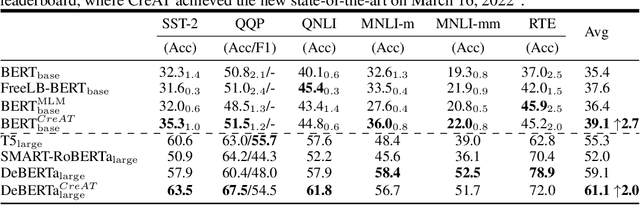
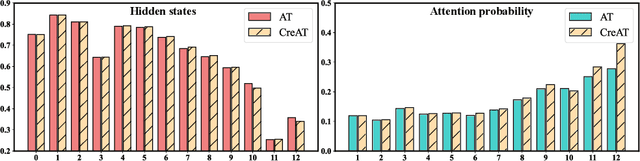
Beyond the success story of adversarial training (AT) in the recent text domain on top of pre-trained language models (PLMs), our empirical study showcases the inconsistent gains from AT on some tasks, e.g. commonsense reasoning, named entity recognition. This paper investigates AT from the perspective of the contextualized language representation outputted by PLM encoders. We find the current AT attacks lean to generate sub-optimal adversarial examples that can fool the decoder part but have a minor effect on the encoder. However, we find it necessary to effectively deviate the latter one to allow AT to gain. Based on the observation, we propose simple yet effective \textit{Contextualized representation-Adversarial Training} (CreAT), in which the attack is explicitly optimized to deviate the contextualized representation of the encoder. It allows a global optimization of adversarial examples that can fool the entire model. We also find CreAT gives rise to a better direction to optimize the adversarial examples, to let them less sensitive to hyperparameters. Compared to AT, CreAT produces consistent performance gains on a wider range of tasks and is proven to be more effective for language pre-training where only the encoder part is kept for downstream tasks. We achieve the new state-of-the-art performances on a series of challenging benchmarks, e.g. AdvGLUE (59.1 $ \rightarrow $ 61.1), HellaSWAG (93.0 $ \rightarrow $ 94.9), ANLI (68.1 $ \rightarrow $ 69.3).
Few-shot Incremental Event Detection
Sep 05, 2022


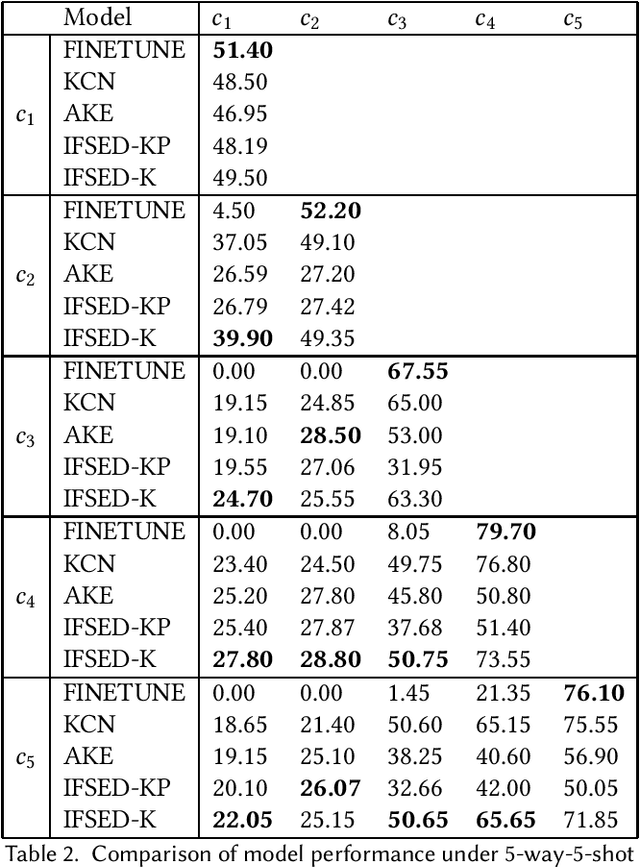
Event detection tasks can help people quickly determine the domain from complex texts. It can also provides powerful support for downstream tasks of natural language processing.Existing methods implement fixed-type learning only based on large amounts of data. When extending to new classes, it is often required to retain the original data and retrain the model.Incremental event detection tasks enables lifelong learning of new classes, but most existing methods need to retain a large number of original data or face the problem of catastrophic forgetting. Apart from that, it is difficult to obtain enough data for model training due to the lack of high-quality data in practical.To address the above problems, we define a new task in the domain of event detection, which is few-shot incremental event detection.This task require that the model should retain previous type when learning new event type in each round with limited input. We recreate and release a benchmark dataset in the few-shot incremental event detection task based on FewEvent.The dataset we published is more appropriate than other in this new task. In addition, we propose two benchmark approaches, IFSED-K and IFSED-KP, which can address the task in different ways. Experiments results have shown that our approach has a higher F1 score and is more stable than baseline.