 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChinese Spelling Error Detection Using a Fusion Lattice LSTM
Paper and Code
Nov 25, 2019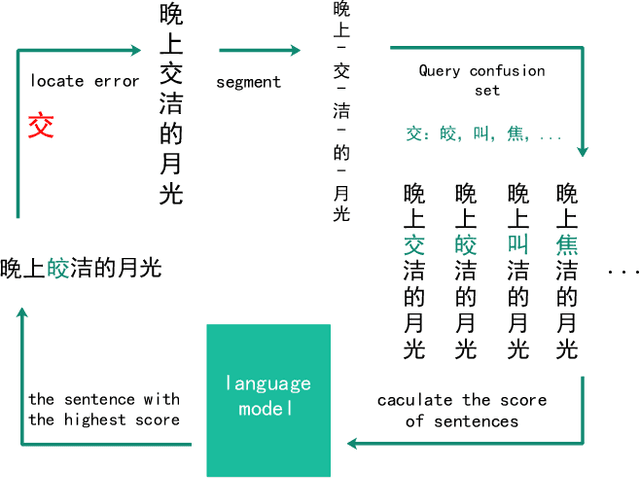
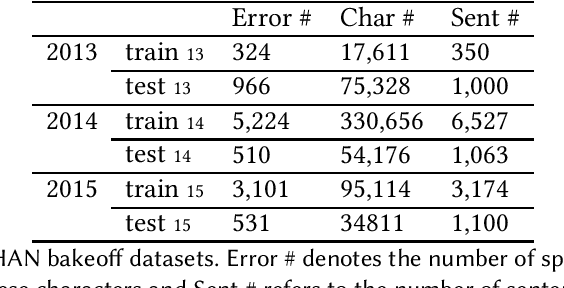
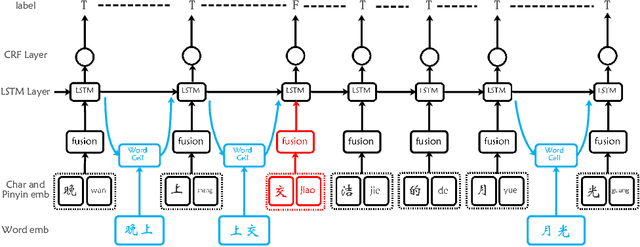
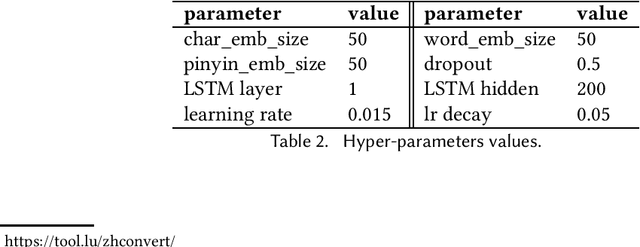
Spelling error detection serves as a crucial preprocessing in many natural language processing applications. Due to the characteristics of Chinese Language, Chinese spelling error detection is more challenging than error detection in English. Existing methods are mainly under a pipeline framework, which artificially divides error detection process into two steps. Thus, these methods bring error propagation and cannot always work well due to the complexity of the language environment. Besides existing methods only adopt character or word information, and ignore the positive effect of fusing character, word, pinyin1 information together. We propose an LF-LSTM-CRF model, which is an extension of the LSTMCRF with word lattices and character-pinyin-fusion inputs. Our model takes advantage of the end-to-end framework to detect errors as a whole process, and dynamically integrates character, word and pinyin information. Experiments on the SIGHAN data show that our LF-LSTM-CRF outperforms existing methods with similar external resources consistently, and confirm the feasibility of adopting the end-to-end framework and the availability of integrating of character, word and pinyin information.