 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMINT: Mitigating Hallucinations in Large Vision-Language Models via Token Reduction
Feb 02, 2025



Hallucination has been a long-standing and inevitable problem that hinders the application of Large Vision-Language Models (LVLMs) in domains that require high reliability. Various methods focus on improvement depending on data annotations or training strategies, yet place less emphasis on LLM's inherent problems. To fill this gap, we delve into the attention mechanism of the decoding process in the LVLM. Intriguingly, our investigation uncovers the prevalent attention redundancy within the hierarchical architecture of the LVLM, manifesting as overextended image processing in deep layers and an overabundance of non-essential image tokens. Stemming from the observation, we thus propose MINT, a novel training-free decoding strategy, MItigating hallucinations via tokeN reducTion. Specifically, we dynamically intensify the LVLM's local perception capability by masking its attention to irrelevant image tokens. In addition, we use contrastive decoding that pushes the model to focus more on those key image regions. Our full method aims to guide the model in concentrating more on key visual elements during generation. Extensive experimental results on several popular public benchmarks show that our approach achieves a 4% improvement in mitigating hallucinations caused by distracted perception compared to original models. Meanwhile, our approach is demonstrated to make the model perceive 5% more visual points even though we reduce a suite of image tokens.
Meta-HAR: Federated Representation Learning for Human Activity Recognition
May 31, 2021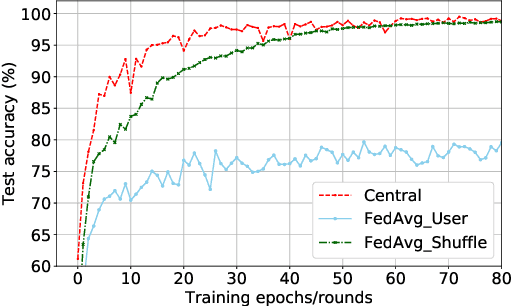
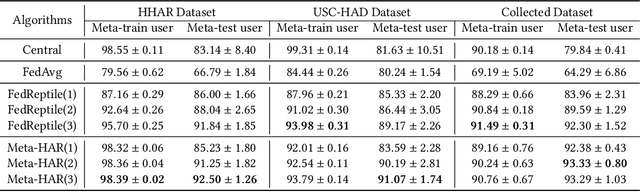
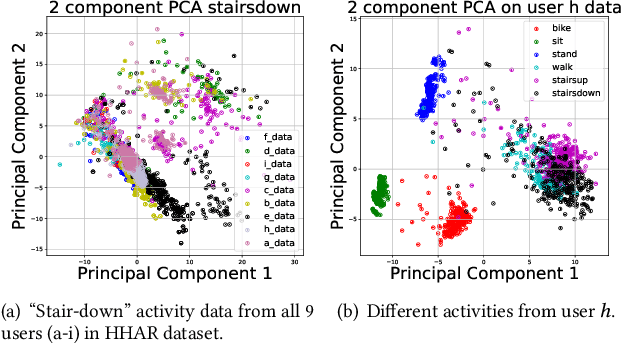
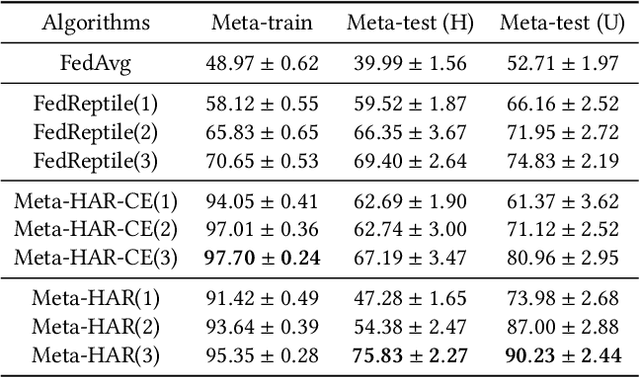
Human activity recognition (HAR) based on mobile sensors plays an important role in ubiquitous computing. However, the rise of data regulatory constraints precludes collecting private and labeled signal data from personal devices at scale. Federated learning has emerged as a decentralized alternative solution to model training, which iteratively aggregates locally updated models into a shared global model, therefore being able to leverage decentralized, private data without central collection. However, the effectiveness of federated learning for HAR is affected by the fact that each user has different activity types and even a different signal distribution for the same activity type. Furthermore, it is uncertain if a single global model trained can generalize well to individual users or new users with heterogeneous data. In this paper, we propose Meta-HAR, a federated representation learning framework, in which a signal embedding network is meta-learned in a federated manner, while the learned signal representations are further fed into a personalized classification network at each user for activity prediction. In order to boost the representation ability of the embedding network, we treat the HAR problem at each user as a different task and train the shared embedding network through a Model-Agnostic Meta-learning framework, such that the embedding network can generalize to any individual user. Personalization is further achieved on top of the robustly learned representations in an adaptation procedure. We conducted extensive experiments based on two publicly available HAR datasets as well as a newly created HAR dataset. Results verify that Meta-HAR is effective at maintaining high test accuracies for individual users, including new users, and significantly outperforms several baselines, including Federated Averaging, Reptile and even centralized learning in certain cases.
Stochastic Distributed Optimization for Machine Learning from Decentralized Features
Dec 16, 2018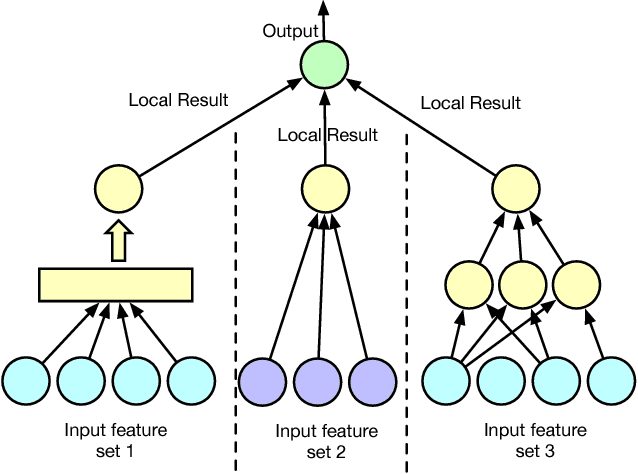


Distributed machine learning has been widely studied in the literature to scale up machine learning model training in the presence of an ever-increasing amount of data. We study distributed machine learning from another perspective, where the information about the training same samples are inherently decentralized and located on different parities. We propose an asynchronous stochastic gradient descent (SGD) algorithm for such a feature distributed machine learning (FDML) problem, to jointly learn from decentralized features, with theoretical convergence guarantees under bounded asynchrony. Our algorithm does not require sharing the original feature data or even local model parameters between parties, thus preserving a high level of data confidentiality. We implement our algorithm for FDML in a parameter server architecture. We compare our system with fully centralized training (which violates data locality requirements) and training only based on local features, through extensive experiments performed on a large amount of data from a real-world application, involving 5 million samples and $8700$ features in total. Experimental results have demonstrated the effectiveness and efficiency of the proposed FDML system.