 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAD: Self-Training with Ambiguous Data for Low-Resource Relation Extraction
Sep 07, 2022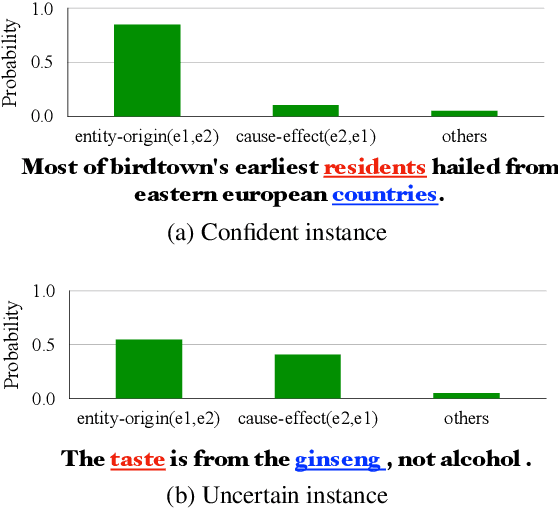
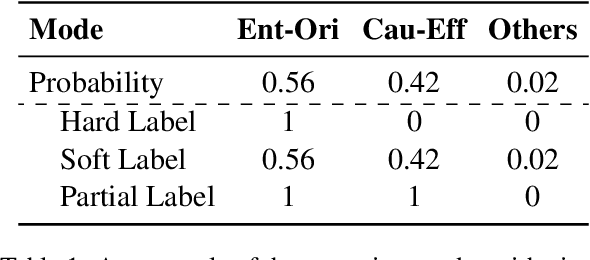
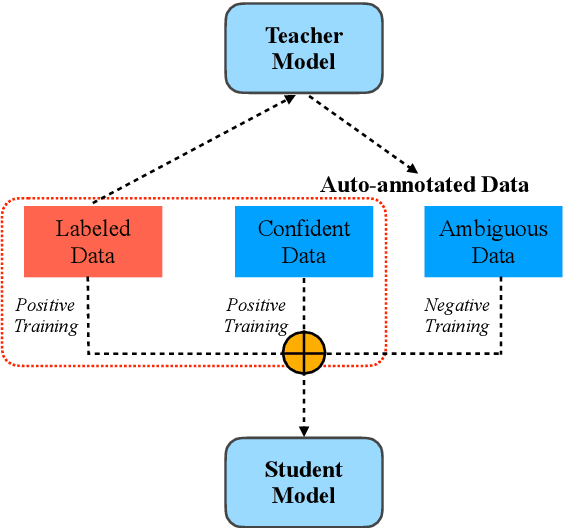
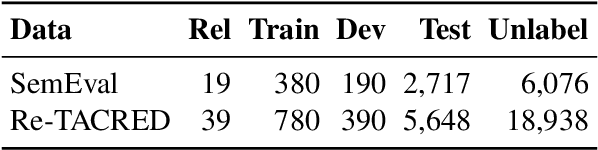
We present a simple yet effective self-training approach, named as STAD, for low-resource relation extraction. The approach first classifies the auto-annotated instances into two groups: confident instances and uncertain instances, according to the probabilities predicted by a teacher model. In contrast to most previous studies, which mainly only use the confident instances for self-training, we make use of the uncertain instances. To this end, we propose a method to identify ambiguous but useful instances from the uncertain instances and then divide the relations into candidate-label set and negative-label set for each ambiguous instance. Next, we propose a set-negative training method on the negative-label sets for the ambiguous instances and a positive training method for the confident instances. Finally, a joint-training method is proposed to build the final relation extraction system on all data. Experimental results on two widely used datasets SemEval2010 Task-8 and Re-TACRED with low-resource settings demonstrate that this new self-training approach indeed achieves significant and consistent improvements when comparing to several competitive self-training systems. Code is publicly available at https://github.com/jjyunlp/STAD
A Challenge on Semi-Supervised and Reinforced Task-Oriented Dialog Systems
Jul 06, 2022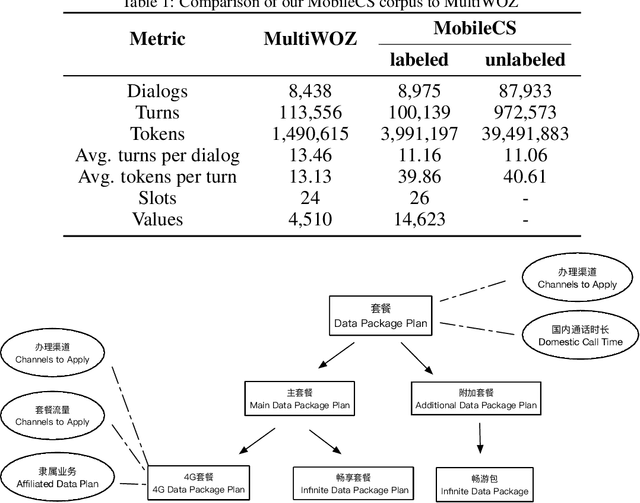

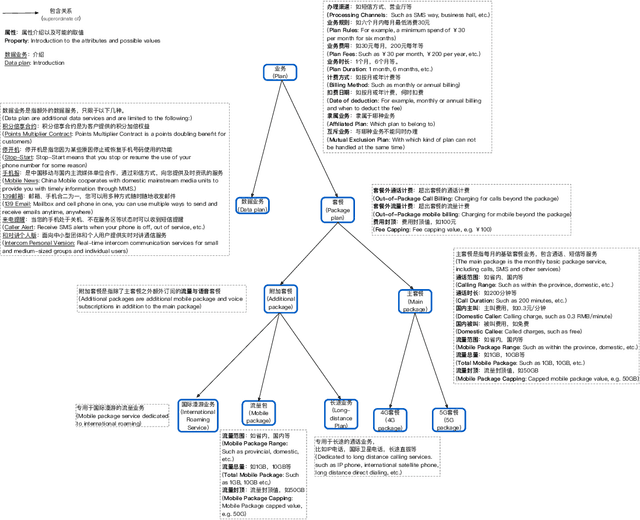
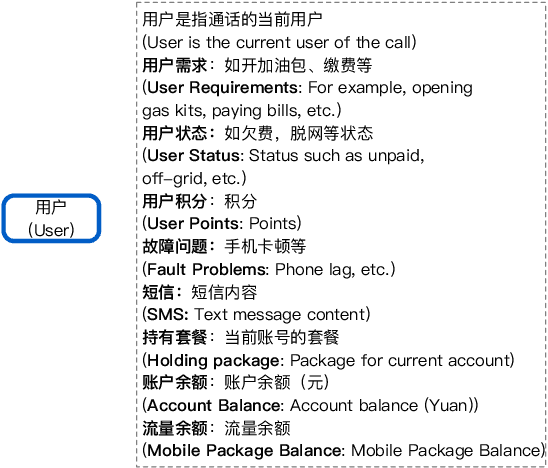
A challenge on Semi-Supervised and Reinforced Task-Oriented Dialog Systems, Co-located with EMNLP2022 SereTOD Workshop.
Domain Adaptation Using Class Similarity for Robust Speech Recognition
Nov 05, 2020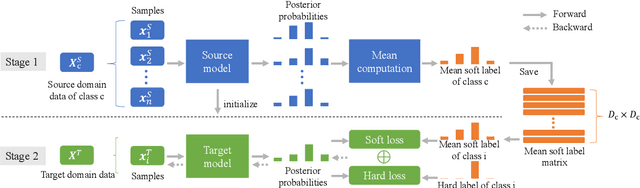
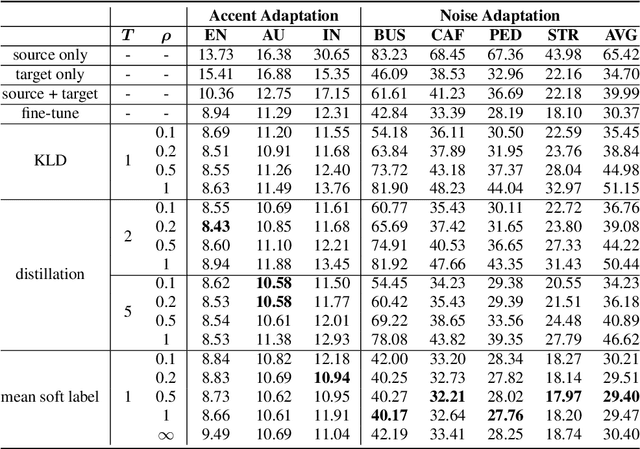
When only limited target domain data is available, domain adaptation could be used to promote performance of deep neural network (DNN) acoustic model by leveraging well-trained source model and target domain data. However, suffering from domain mismatch and data sparsity, domain adaptation is very challenging. This paper proposes a novel adaptation method for DNN acoustic model using class similarity. Since the output distribution of DNN model contains the knowledge of similarity among classes, which is applicable to both source and target domain, it could be transferred from source to target model for the performance improvement. In our approach, we first compute the frame level posterior probabilities of source samples using source model. Then, for each class, probabilities of this class are used to compute a mean vector, which we refer to as mean soft labels. During adaptation, these mean soft labels are used in a regularization term to train the target model. Experiments showed that our approach outperforms fine-tuning using one-hot labels on both accent and noise adaptation task, especially when source and target domain are highly mismatched.