 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAD: Self-Training with Ambiguous Data for Low-Resource Relation Extraction
Paper and Code
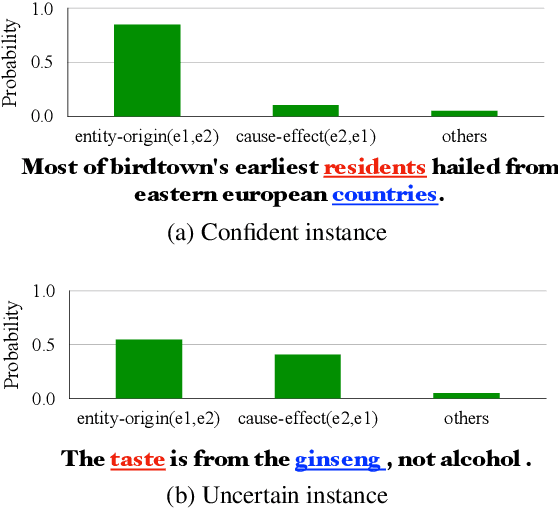
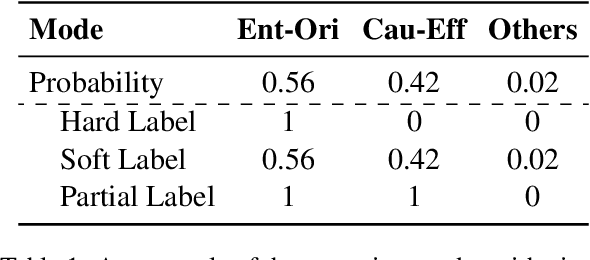
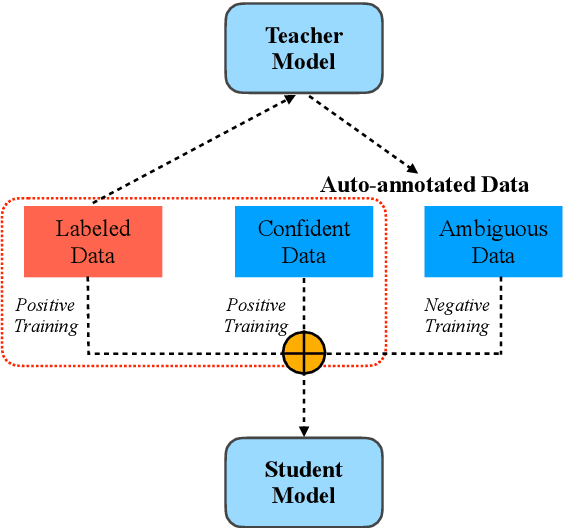
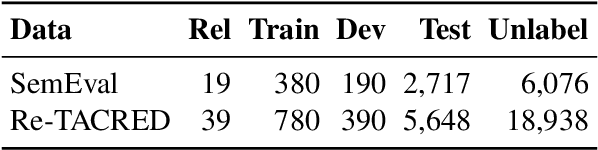
We present a simple yet effective self-training approach, named as STAD, for low-resource relation extraction. The approach first classifies the auto-annotated instances into two groups: confident instances and uncertain instances, according to the probabilities predicted by a teacher model. In contrast to most previous studies, which mainly only use the confident instances for self-training, we make use of the uncertain instances. To this end, we propose a method to identify ambiguous but useful instances from the uncertain instances and then divide the relations into candidate-label set and negative-label set for each ambiguous instance. Next, we propose a set-negative training method on the negative-label sets for the ambiguous instances and a positive training method for the confident instances. Finally, a joint-training method is proposed to build the final relation extraction system on all data. Experimental results on two widely used datasets SemEval2010 Task-8 and Re-TACRED with low-resource settings demonstrate that this new self-training approach indeed achieves significant and consistent improvements when comparing to several competitive self-training systems. Code is publicly available at https://github.com/jjyunlp/STAD