 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Budget Allocation in LLM-Augmented Surveys
Apr 14, 2026Large language models (LLMs) can generate survey responses at low cost, but their reliability varies substantially across questions and is unknown before data collection. Deploying LLMs in surveys still requires costly human responses for verification and correction. How should a limited human-labeling budget be allocated across questions in real time? We propose an adaptive allocation algorithm that learns which questions are hardest for the LLM while simultaneously collecting human responses. Each human label serves a dual role: it improves the estimate for that question and reveals how well the LLM predicts human responses on it. The algorithm directs more budget to questions where the LLM is least reliable, without requiring any prior knowledge of question-level LLM accuracy. We prove that the allocation gap relative to the best possible allocation vanishes as the budget grows, and validate the approach on both synthetic data and a real survey dataset with 68 questions and over 2000 respondents. On real survey data, the standard practice of allocating human labels uniformly across questions wastes 10--12% of the budget relative to the optimal; our algorithm reduces this waste to 2--6%, and the advantage grows as questions become more heterogeneous in LLM prediction quality. The algorithm achieves the same estimation quality as traditional uniform sampling with fewer human samples, requires no pilot study, and is backed by formal performance guarantees validated on real survey data. More broadly, the framework applies whenever scarce human oversight must be allocated across tasks where LLM reliability is unknown.
A Minibatch-SGD-Based Learning Meta-Policy for Inventory Systems with Myopic Optimal Policy
Aug 29, 2024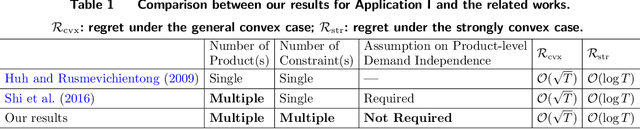

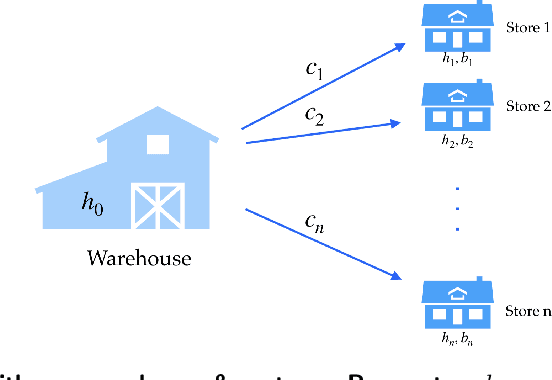
Stochastic gradient descent (SGD) has proven effective in solving many inventory control problems with demand learning. However, it often faces the pitfall of an infeasible target inventory level that is lower than the current inventory level. Several recent works (e.g., Huh and Rusmevichientong (2009), Shi et al.(2016)) are successful to resolve this issue in various inventory systems. However, their techniques are rather sophisticated and difficult to be applied to more complicated scenarios such as multi-product and multi-constraint inventory systems. In this paper, we address the infeasible-target-inventory-level issue from a new technical perspective -- we propose a novel minibatch-SGD-based meta-policy. Our meta-policy is flexible enough to be applied to a general inventory systems framework covering a wide range of inventory management problems with myopic clairvoyant optimal policy. By devising the optimal minibatch scheme, our meta-policy achieves a regret bound of $\mathcal{O}(\sqrt{T})$ for the general convex case and $\mathcal{O}(\log T)$ for the strongly convex case. To demonstrate the power and flexibility of our meta-policy, we apply it to three important inventory control problems: multi-product and multi-constraint systems, multi-echelon serial systems, and one-warehouse and multi-store systems by carefully designing application-specific subroutines.We also conduct extensive numerical experiments to demonstrate that our meta-policy enjoys competitive regret performance, high computational efficiency, and low variances among a wide range of applications.
Closing the Gaps: Optimality of Sample Average Approximation for Data-Driven Newsvendor Problems
Jul 06, 2024

We study the regret performance of Sample Average Approximation (SAA) for data-driven newsvendor problems with general convex inventory costs. In literature, the optimality of SAA has not been fully established under both \alpha-global strong convexity and (\alpha,\beta)-local strong convexity (\alpha-strongly convex within the \beta-neighborhood of the optimal quantity) conditions. This paper closes the gaps between regret upper and lower bounds for both conditions. Under the (\alpha,\beta)-local strong convexity condition, we prove the optimal regret bound of \Theta(\log T/\alpha + 1/ (\alpha\beta)) for SAA. This upper bound result demonstrates that the regret performance of SAA is only influenced by \alpha and not by \beta in the long run, enhancing our understanding about how local properties affect the long-term regret performance of decision-making strategies. Under the \alpha-global strong convexity condition, we demonstrate that the worst-case regret of any data-driven method is lower bounded by \Omega(\log T/\alpha), which is the first lower bound result that matches the existing upper bound with respect to both parameter \alpha and time horizon T. Along the way, we propose to analyze the SAA regret via a new gradient approximation technique, as well as a new class of smooth inverted-hat-shaped hard problem instances that might be of independent interest for the lower bounds of broader data-driven problems.
Stochastic Constrained DRO with a Complexity Independent of Sample Size
Oct 11, 2022



Distributionally Robust Optimization (DRO), as a popular method to train robust models against distribution shift between training and test sets, has received tremendous attention in recent years. In this paper, we propose and analyze stochastic algorithms that apply to both non-convex and convex losses for solving Kullback Leibler divergence constrained DRO problem. Compared with existing methods solving this problem, our stochastic algorithms not only enjoy competitive if not better complexity independent of sample size but also just require a constant batch size at every iteration, which is more practical for broad applications. We establish a nearly optimal complexity bound for finding an $\epsilon$ stationary solution for non-convex losses and an optimal complexity for finding an $\epsilon$ optimal solution for convex losses. Empirical studies demonstrate the effectiveness of the proposed algorithms for solving non-convex and convex constrained DRO problems.
Fairness-aware Network Revenue Management with Demand Learning
Jul 22, 2022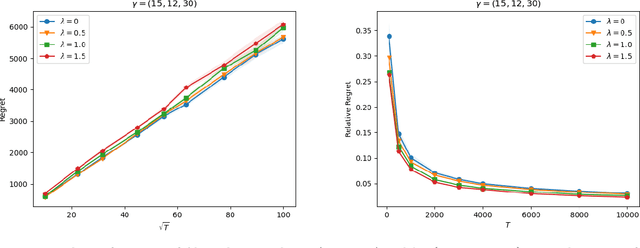

In addition to maximizing the total revenue, decision-makers in lots of industries would like to guarantee fair consumption across different resources and avoid saturating certain resources. Motivated by these practical needs, this paper studies the price-based network revenue management problem with both demand learning and fairness concern about the consumption across different resources. We introduce the regularized revenue, i.e., the total revenue with a fairness regularization, as our objective to incorporate fairness into the revenue maximization goal. We propose a primal-dual-type online policy with the Upper-Confidence-Bound (UCB) demand learning method to maximize the regularized revenue. We adopt several innovative techniques to make our algorithm a unified and computationally efficient framework for the continuous price set and a wide class of fairness regularizers. Our algorithm achieves a worst-case regret of $\tilde O(N^{5/2}\sqrt{T})$, where $N$ denotes the number of products and $T$ denotes the number of time periods. Numerical experiments in a few NRM examples demonstrate the effectiveness of our algorithm for balancing revenue and fairness.