 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Minibatch-SGD-Based Learning Meta-Policy for Inventory Systems with Myopic Optimal Policy
Aug 29, 2024

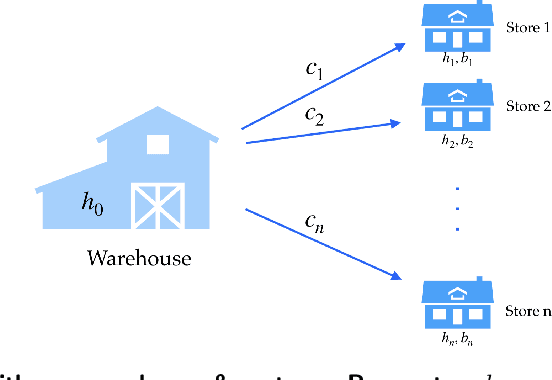
Stochastic gradient descent (SGD) has proven effective in solving many inventory control problems with demand learning. However, it often faces the pitfall of an infeasible target inventory level that is lower than the current inventory level. Several recent works (e.g., Huh and Rusmevichientong (2009), Shi et al.(2016)) are successful to resolve this issue in various inventory systems. However, their techniques are rather sophisticated and difficult to be applied to more complicated scenarios such as multi-product and multi-constraint inventory systems. In this paper, we address the infeasible-target-inventory-level issue from a new technical perspective -- we propose a novel minibatch-SGD-based meta-policy. Our meta-policy is flexible enough to be applied to a general inventory systems framework covering a wide range of inventory management problems with myopic clairvoyant optimal policy. By devising the optimal minibatch scheme, our meta-policy achieves a regret bound of $\mathcal{O}(\sqrt{T})$ for the general convex case and $\mathcal{O}(\log T)$ for the strongly convex case. To demonstrate the power and flexibility of our meta-policy, we apply it to three important inventory control problems: multi-product and multi-constraint systems, multi-echelon serial systems, and one-warehouse and multi-store systems by carefully designing application-specific subroutines.We also conduct extensive numerical experiments to demonstrate that our meta-policy enjoys competitive regret performance, high computational efficiency, and low variances among a wide range of applications.
Closing the Gaps: Optimality of Sample Average Approximation for Data-Driven Newsvendor Problems
Jul 06, 2024

We study the regret performance of Sample Average Approximation (SAA) for data-driven newsvendor problems with general convex inventory costs. In literature, the optimality of SAA has not been fully established under both \alpha-global strong convexity and (\alpha,\beta)-local strong convexity (\alpha-strongly convex within the \beta-neighborhood of the optimal quantity) conditions. This paper closes the gaps between regret upper and lower bounds for both conditions. Under the (\alpha,\beta)-local strong convexity condition, we prove the optimal regret bound of \Theta(\log T/\alpha + 1/ (\alpha\beta)) for SAA. This upper bound result demonstrates that the regret performance of SAA is only influenced by \alpha and not by \beta in the long run, enhancing our understanding about how local properties affect the long-term regret performance of decision-making strategies. Under the \alpha-global strong convexity condition, we demonstrate that the worst-case regret of any data-driven method is lower bounded by \Omega(\log T/\alpha), which is the first lower bound result that matches the existing upper bound with respect to both parameter \alpha and time horizon T. Along the way, we propose to analyze the SAA regret via a new gradient approximation technique, as well as a new class of smooth inverted-hat-shaped hard problem instances that might be of independent interest for the lower bounds of broader data-driven problems.