 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Channel-Triggered Backdoor Attack on Wireless Semantic Image Reconstruction
Mar 31, 2025Despite the transformative impact of deep learning (DL) on wireless communication systems through data-driven end-to-end (E2E) learning, the security vulnerabilities of these systems have been largely overlooked. Unlike the extensively studied image domain, limited research has explored the threat of backdoor attacks on the reconstruction of symbols in semantic communication (SemCom) systems. Previous work has investigated such backdoor attacks at the input level, but these approaches are infeasible in applications with strict input control. In this paper, we propose a novel attack paradigm, termed Channel-Triggered Backdoor Attack (CT-BA), where the backdoor trigger is a specific wireless channel. This attack leverages fundamental physical layer characteristics, making it more covert and potentially more threatening compared to previous input-level attacks. Specifically, we utilize channel gain with different fading distributions or channel noise with different power spectral densities as potential triggers. This approach establishes unprecedented attack flexibility as the adversary can select backdoor triggers from both fading characteristics and noise variations in diverse channel environments. Moreover, during the testing phase, CT-BA enables automatic trigger activation through natural channel variations without requiring active adversary participation. We evaluate the robustness of CT-BA on a ViT-based Joint Source-Channel Coding (JSCC) model across three datasets: MNIST, CIFAR-10, and ImageNet. Furthermore, we apply CT-BA to three typical E2E SemCom systems: BDJSCC, ADJSCC, and JSCCOFDM. Experimental results demonstrate that our attack achieves near-perfect attack success rate (ASR) while maintaining effective stealth. Finally, we discuss potential defense mechanisms against such attacks.
Model-Based Offline Meta-Reinforcement Learning with Regularization
Feb 07, 2022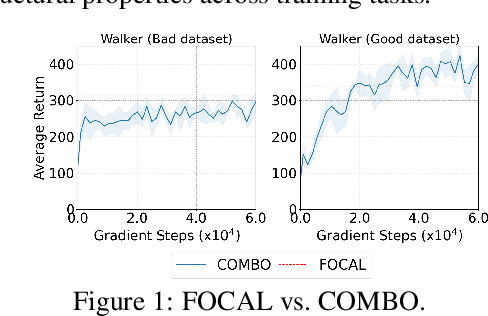
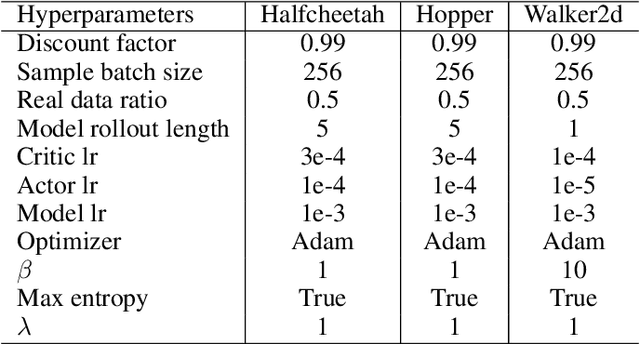
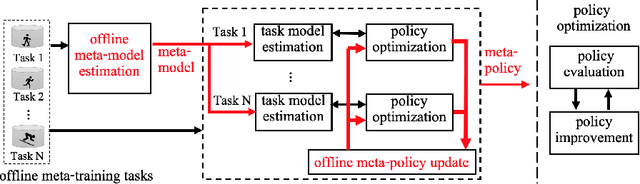
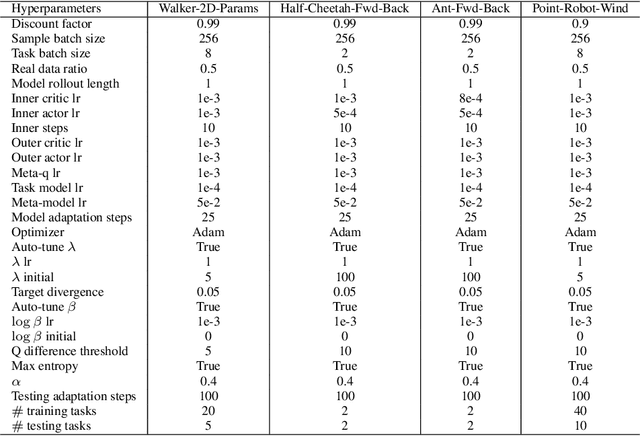
Existing offline reinforcement learning (RL) methods face a few major challenges, particularly the distributional shift between the learned policy and the behavior policy. Offline Meta-RL is emerging as a promising approach to address these challenges, aiming to learn an informative meta-policy from a collection of tasks. Nevertheless, as shown in our empirical studies, offline Meta-RL could be outperformed by offline single-task RL methods on tasks with good quality of datasets, indicating that a right balance has to be delicately calibrated between "exploring" the out-of-distribution state-actions by following the meta-policy and "exploiting" the offline dataset by staying close to the behavior policy. Motivated by such empirical analysis, we explore model-based offline Meta-RL with regularized Policy Optimization (MerPO), which learns a meta-model for efficient task structure inference and an informative meta-policy for safe exploration of out-of-distribution state-actions. In particular, we devise a new meta-Regularized model-based Actor-Critic (RAC) method for within-task policy optimization, as a key building block of MerPO, using conservative policy evaluation and regularized policy improvement; and the intrinsic tradeoff therein is achieved via striking the right balance between two regularizers, one based on the behavior policy and the other on the meta-policy. We theoretically show that the learnt policy offers guaranteed improvement over both the behavior policy and the meta-policy, thus ensuring the performance improvement on new tasks via offline Meta-RL. Experiments corroborate the superior performance of MerPO over existing offline Meta-RL methods.