 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogical Induction
Dec 13, 2017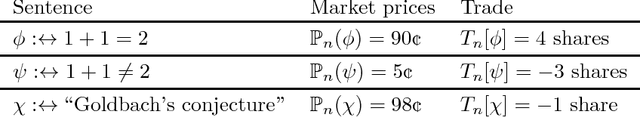
We present a computable algorithm that assigns probabilities to every logical statement in a given formal language, and refines those probabilities over time. For instance, if the language is Peano arithmetic, it assigns probabilities to all arithmetical statements, including claims about the twin prime conjecture, the outputs of long-running computations, and its own probabilities. We show that our algorithm, an instance of what we call a logical inductor, satisfies a number of intuitive desiderata, including: (1) it learns to predict patterns of truth and falsehood in logical statements, often long before having the resources to evaluate the statements, so long as the patterns can be written down in polynomial time; (2) it learns to use appropriate statistical summaries to predict sequences of statements whose truth values appear pseudorandom; and (3) it learns to have accurate beliefs about its own current beliefs, in a manner that avoids the standard paradoxes of self-reference. For example, if a given computer program only ever produces outputs in a certain range, a logical inductor learns this fact in a timely manner; and if late digits in the decimal expansion of $\pi$ are difficult to predict, then a logical inductor learns to assign $\approx 10\%$ probability to "the $n$th digit of $\pi$ is a 7" for large $n$. Logical inductors also learn to trust their future beliefs more than their current beliefs, and their beliefs are coherent in the limit (whenever $\phi \implies \psi$, $\mathbb{P}_\infty(\phi) \le \mathbb{P}_\infty(\psi)$, and so on); and logical inductors strictly dominate the universal semimeasure in the limit. These properties and many others all follow from a single logical induction criterion, which is motivated by a series of stock trading analogies. Roughly speaking, each logical sentence $\phi$ is associated with a stock that is worth \$1 per share if [...]
A Formal Solution to the Grain of Truth Problem
Sep 16, 2016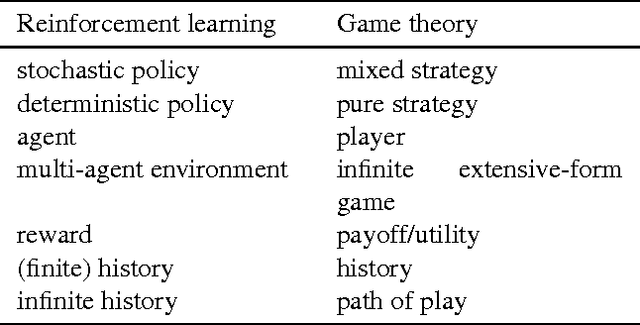

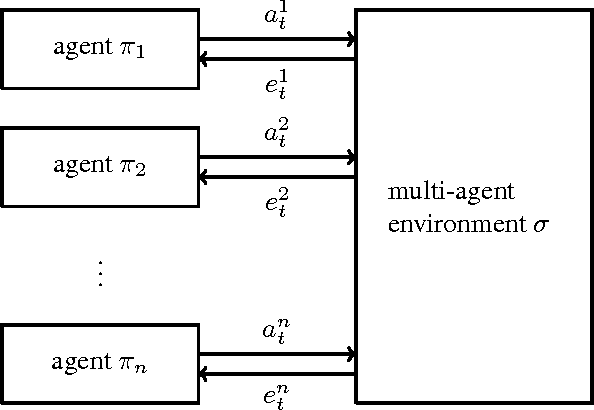
A Bayesian agent acting in a multi-agent environment learns to predict the other agents' policies if its prior assigns positive probability to them (in other words, its prior contains a \emph{grain of truth}). Finding a reasonably large class of policies that contains the Bayes-optimal policies with respect to this class is known as the \emph{grain of truth problem}. Only small classes are known to have a grain of truth and the literature contains several related impossibility results. In this paper we present a formal and general solution to the full grain of truth problem: we construct a class of policies that contains all computable policies as well as Bayes-optimal policies for every lower semicomputable prior over the class. When the environment is unknown, Bayes-optimal agents may fail to act optimally even asymptotically. However, agents based on Thompson sampling converge to play {\epsilon}-Nash equilibria in arbitrary unknown computable multi-agent environments. While these results are purely theoretical, we show that they can be computationally approximated arbitrarily closely.
Asymptotic Convergence in Online Learning with Unbounded Delays
Sep 07, 2016We study the problem of predicting the results of computations that are too expensive to run, via the observation of the results of smaller computations. We model this as an online learning problem with delayed feedback, where the length of the delay is unbounded, which we study mainly in a stochastic setting. We show that in this setting, consistency is not possible in general, and that optimal forecasters might not have average regret going to zero. However, it is still possible to give algorithms that converge asymptotically to Bayes-optimal predictions, by evaluating forecasters on specific sparse independent subsequences of their predictions. We give an algorithm that does this, which converges asymptotically on good behavior, and give very weak bounds on how long it takes to converge. We then relate our results back to the problem of predicting large computations in a deterministic setting.
Reflective Oracles: A Foundation for Classical Game Theory
Aug 17, 2015Classical game theory treats players as special---a description of a game contains a full, explicit enumeration of all players---even though in the real world, "players" are no more fundamentally special than rocks or clouds. It isn't trivial to find a decision-theoretic foundation for game theory in which an agent's coplayers are a non-distinguished part of the agent's environment. Attempts to model both players and the environment as Turing machines, for example, fail for standard diagonalization reasons. In this paper, we introduce a "reflective" type of oracle, which is able to answer questions about the outputs of oracle machines with access to the same oracle. These oracles avoid diagonalization by answering some queries randomly. We show that machines with access to a reflective oracle can be used to define rational agents using causal decision theory. These agents model their environment as a probabilistic oracle machine, which may contain other agents as a non-distinguished part. We show that if such agents interact, they will play a Nash equilibrium, with the randomization in mixed strategies coming from the randomization in the oracle's answers. This can be seen as providing a foundation for classical game theory in which players aren't special.