 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFourier Transformers for Latent Crystallographic Diffusion and Generative Modeling
Feb 12, 2026The discovery of new crystalline materials calls for generative models that handle periodic boundary conditions, crystallographic symmetries, and physical constraints, while scaling to large and structurally diverse unit cells. We propose a reciprocal-space generative pipeline that represents crystals through a truncated Fourier transform of the species-resolved unit-cell density, rather than modeling atomic coordinates directly. This representation is periodicity-native, admits simple algebraic actions of space-group symmetries, and naturally supports variable atomic multiplicities during generation, addressing a common limitation of particle-based approaches. Using only nine Fourier basis functions per spatial dimension, our approach reconstructs unit cells containing up to 108 atoms per chemical species. We instantiate this pipeline with a transformer variational autoencoder over complex-valued Fourier coefficients, and a latent diffusion model that generates in the compressed latent space. We evaluate reconstruction and latent diffusion on the LeMaterial benchmark and compare unconditional generation against coordinate-based baselines in the small-cell regime ($\leq 16$ atoms per unit cell).
Curvature in the Looking-Glass: Optimal Methods to Exploit Curvature of Expectation in the Loss Landscape
Nov 25, 2024
Harnessing the local topography of the loss landscape is a central challenge in advanced optimization tasks. By accounting for the effect of potential parameter changes, we can alter the model more efficiently. Contrary to standard assumptions, we find that the Hessian does not always approximate loss curvature well, particularly near gradient discontinuities, which commonly arise in deep learning architectures. We present a new conceptual framework to understand how curvature of expected changes in loss emerges in architectures with many rectified linear units. Each ReLU creates a parameter boundary that, when crossed, induces a pseudorandom gradient perturbation. Our derivations show how these discontinuities combine to form a glass-like structure, similar to amorphous solids that contain microscopic domains of strong, but random, atomic alignment. By estimating the density of the resulting gradient variations, we can bound how the loss may change with parameter movement. Our analysis includes the optimal kernel and sample distribution for approximating glass density from ordinary gradient evaluations. We also derive the optimal modification to quasi-Newton steps that incorporate both glass and Hessian terms, as well as certain exactness properties that are possible with Nesterov-accelerated gradient updates. Our algorithm, Alice, tests these techniques to determine which curvature terms are most impactful for training a given architecture and dataset. Additional safeguards enforce stable exploitation through step bounds that expand on the functionality of Adam. These theoretical and experimental tools lay groundwork to improve future efforts (e.g., pruning and quantization) by providing new insight into the loss landscape.
An Efficient Quadrature Sequence and Sparsifying Methodology for Mean-Field Variational Inference
Jan 20, 2023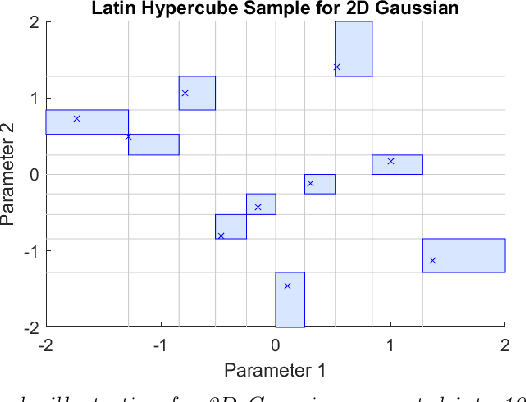
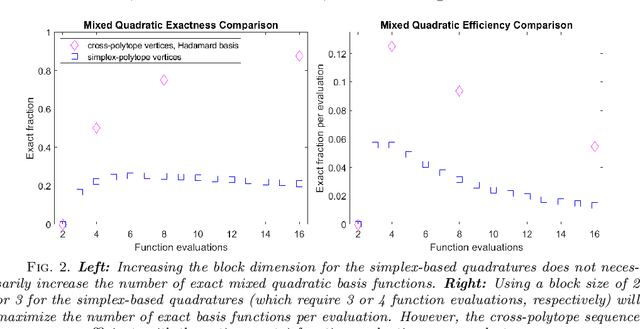
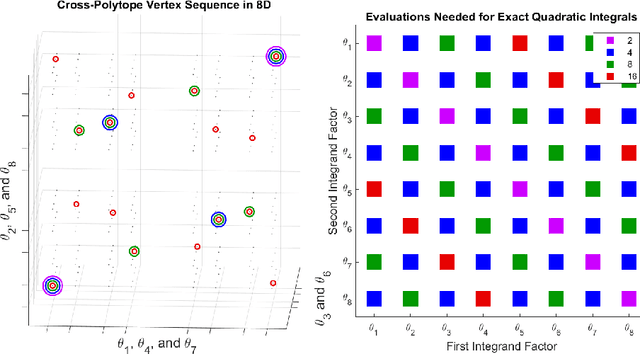
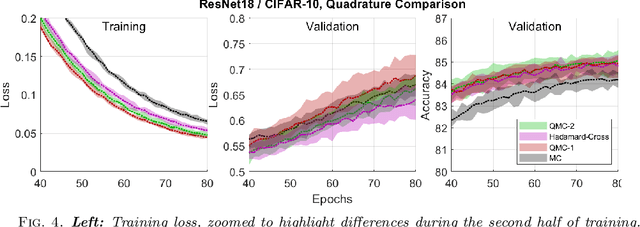
This work proposes a quasirandom sequence of quadratures for high-dimensional mean-field variational inference and a related sparsifying methodology. Each iterate of the sequence contains two evaluations points that combine to correctly integrate all univariate quadratic functions, as well as univariate cubics if the mean-field factors are symmetric. More importantly, averaging results over short subsequences achieves periodic exactness on a much larger space of multivariate polynomials of quadratic total degree. This framework is devised by first considering stochastic blocked mean-field quadratures, which may be useful in other contexts. By replacing pseudorandom sequences with quasirandom sequences, over half of all multivariate quadratic basis functions integrate exactly with only 4 function evaluations, and the exactness dimension increases for longer subsequences. Analysis shows how these efficient integrals characterize the dominant log-posterior contributions to mean-field variational approximations, including diagonal Hessian approximations, to support a robust sparsifying methodology in deep learning algorithms. A numerical demonstration of this approach on a simple Convolutional Neural Network for MNIST retains high test accuracy, 96.9%, while training over 98.9% of parameters to zero in only 10 epochs, bearing potential to reduce both storage and energy requirements for deep learning models.
Variational Kalman Filtering with Hinf-Based Correction for Robust Bayesian Learning in High Dimensions
Apr 27, 2022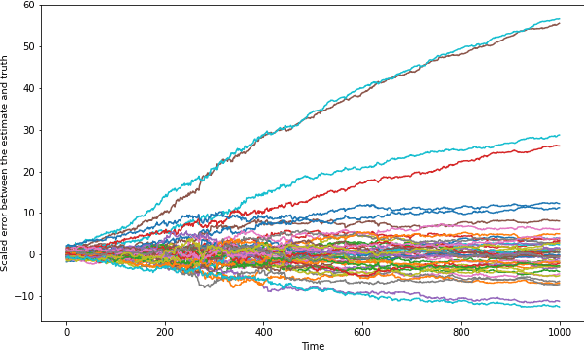
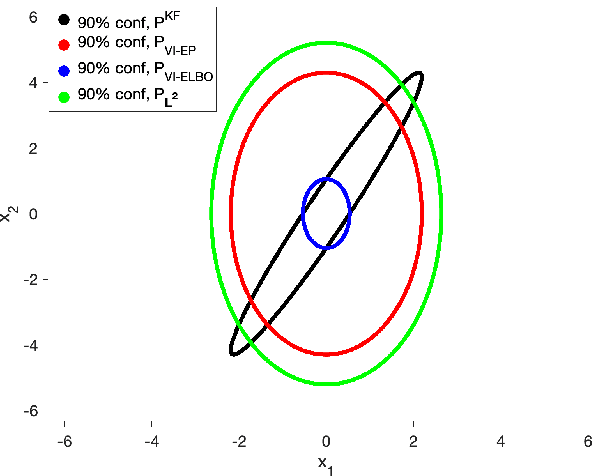
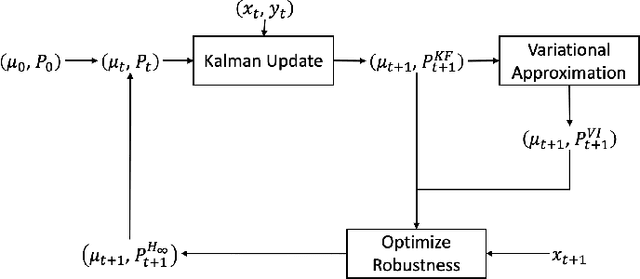
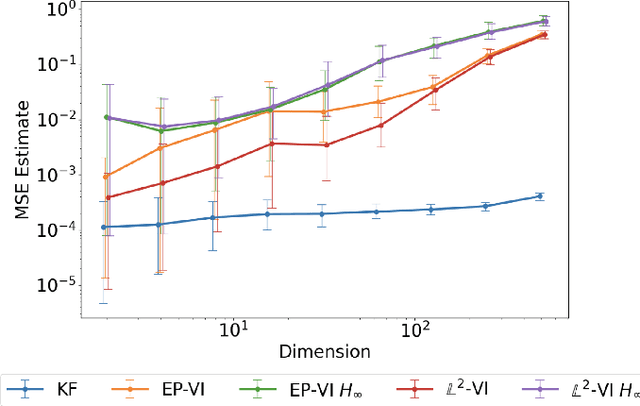
In this paper, we address the problem of convergence of sequential variational inference filter (VIF) through the application of a robust variational objective and Hinf-norm based correction for a linear Gaussian system. As the dimension of state or parameter space grows, performing the full Kalman update with the dense covariance matrix for a large scale system requires increased storage and computational complexity, making it impractical. The VIF approach, based on mean-field Gaussian variational inference, reduces this burden through the variational approximation to the covariance usually in the form of a diagonal covariance approximation. The challenge is to retain convergence and correct for biases introduced by the sequential VIF steps. We desire a framework that improves feasibility while still maintaining reasonable proximity to the optimal Kalman filter as data is assimilated. To accomplish this goal, a Hinf-norm based optimization perturbs the VIF covariance matrix to improve robustness. This yields a novel VIF- Hinf recursion that employs consecutive variational inference and Hinf based optimization steps. We explore the development of this method and investigate a numerical example to illustrate the effectiveness of the proposed filter.
Adaptive n-ary Activation Functions for Probabilistic Boolean Logic
Mar 16, 2022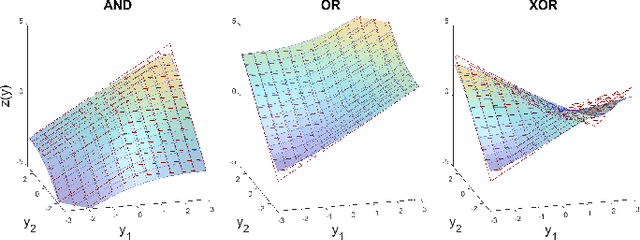
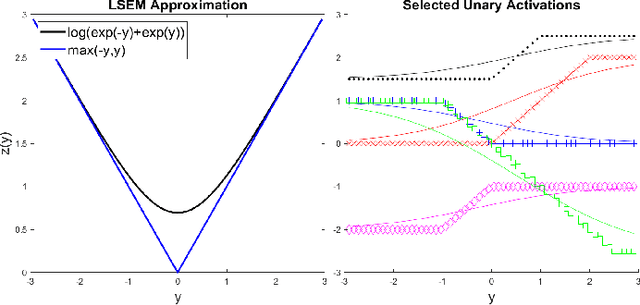
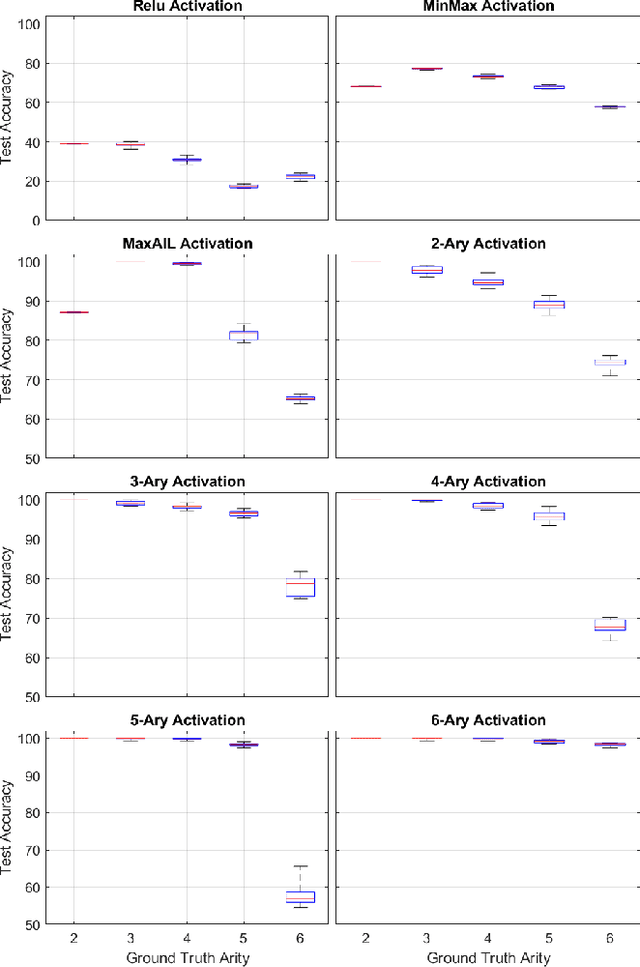
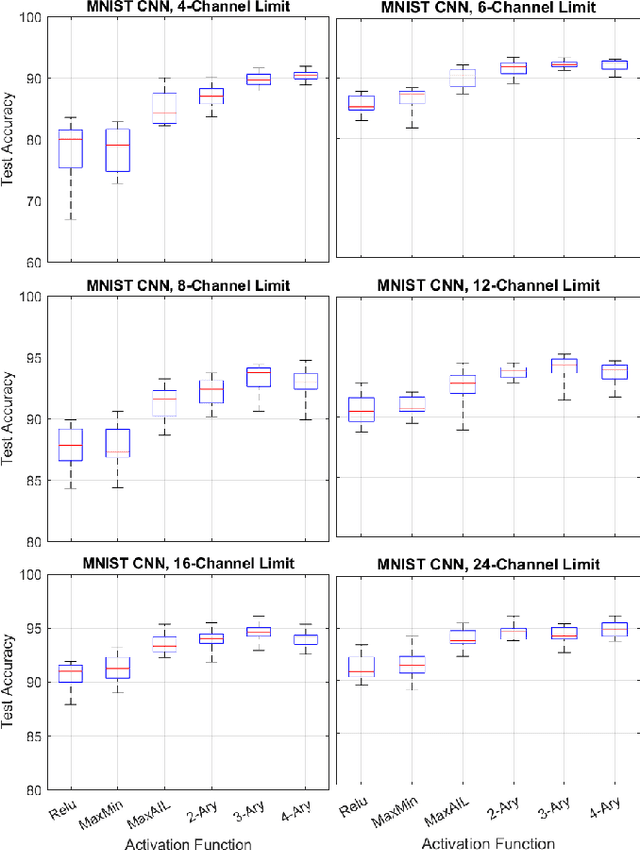
Balancing model complexity against the information contained in observed data is the central challenge to learning. In order for complexity-efficient models to exist and be discoverable in high dimensions, we require a computational framework that relates a credible notion of complexity to simple parameter representations. Further, this framework must allow excess complexity to be gradually removed via gradient-based optimization. Our n-ary, or n-argument, activation functions fill this gap by approximating belief functions (probabilistic Boolean logic) using logit representations of probability. Just as Boolean logic determines the truth of a consequent claim from relationships among a set of antecedent propositions, probabilistic formulations generalize predictions when antecedents, truth tables, and consequents all retain uncertainty. Our activation functions demonstrate the ability to learn arbitrary logic, such as the binary exclusive disjunction (p xor q) and ternary conditioned disjunction ( c ? p : q ), in a single layer using an activation function of matching or greater arity. Further, we represent belief tables using a basis that directly associates the number of nonzero parameters to the effective arity of the belief function, thus capturing a concrete relationship between logical complexity and efficient parameter representations. This opens optimization approaches to reduce logical complexity by inducing parameter sparsity.
Parsimonious Inference
Mar 03, 2021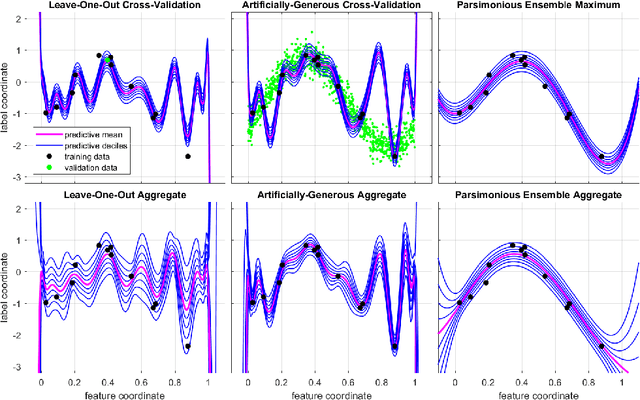

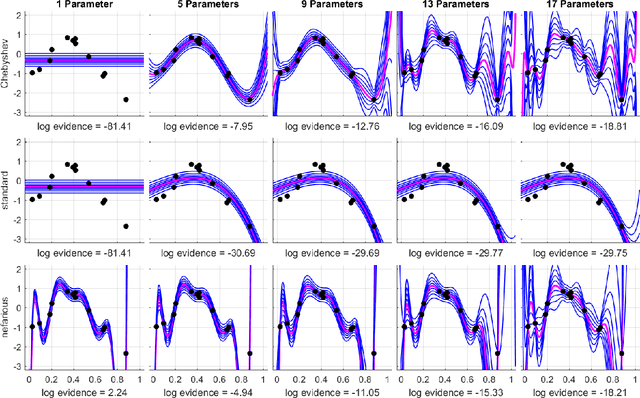
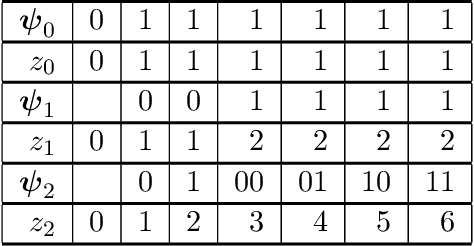
Bayesian inference provides a uniquely rigorous approach to obtain principled justification for uncertainty in predictions, yet it is difficult to articulate suitably general prior belief in the machine learning context, where computational architectures are pure abstractions subject to frequent modifications by practitioners attempting to improve results. Parsimonious inference is an information-theoretic formulation of inference over arbitrary architectures that formalizes Occam's Razor; we prefer simple and sufficient explanations. Our universal hyperprior assigns plausibility to prior descriptions, encoded as sequences of symbols, by expanding on the core relationships between program length, Kolmogorov complexity, and Solomonoff's algorithmic probability. We then cast learning as information minimization over our composite change in belief when an architecture is specified, training data are observed, and model parameters are inferred. By distinguishing model complexity from prediction information, our framework also quantifies the phenomenon of memorization. Although our theory is general, it is most critical when datasets are limited, e.g. small or skewed. We develop novel algorithms for polynomial regression and random forests that are suitable for such data, as demonstrated by our experiments. Our approaches combine efficient encodings with prudent sampling strategies to construct predictive ensembles without cross-validation, thus addressing a fundamental challenge in how to efficiently obtain predictions from data.
Generalizing Information to the Evolution of Rational Belief
Jan 12, 2020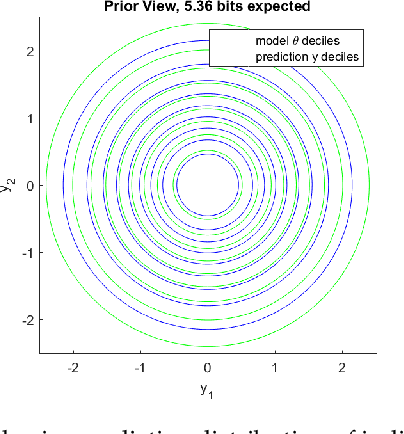
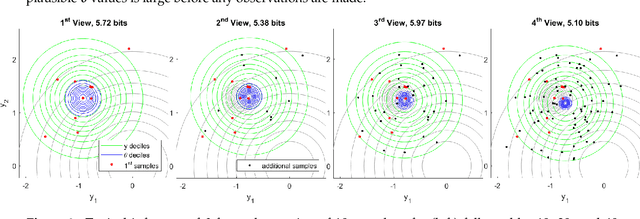
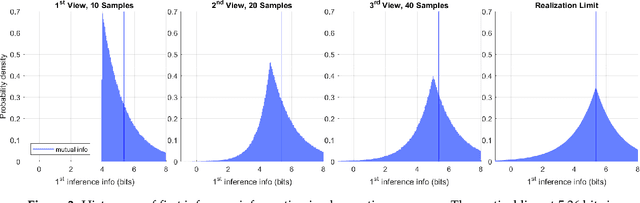
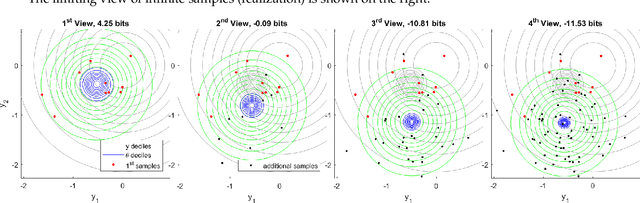
Information theory provides a mathematical foundation to measure uncertainty in belief. Belief is represented by a probability distribution that captures our understanding of an outcome's plausibility. Information measures based on Shannon's concept of entropy include realization information, Kullback-Leibler divergence, Lindley's information in experiment, cross entropy, and mutual information. We derive a general theory of information from first principles that accounts for evolving belief and recovers all of these measures. Rather than simply gauging uncertainty, information is understood in this theory to measure change in belief. We may then regard entropy as the information we expect to gain upon realization of a discrete latent random variable. This theory of information is compatible with the Bayesian paradigm in which rational belief is updated as evidence becomes available. Furthermore, this theory admits novel measures of information with well-defined properties, which we explore in both analysis and experiment. This view of information illuminates the study of machine learning by allowing us to quantify information captured by a predictive model and distinguish it from residual information contained in training data. We gain related insights regarding feature selection, anomaly detection, and novel Bayesian approaches.
Generalized Canonical Polyadic Tensor Decomposition
Aug 22, 2018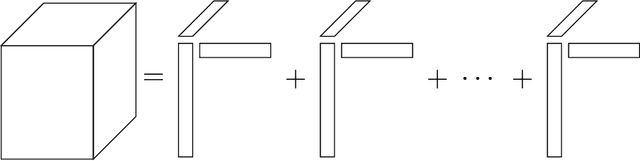

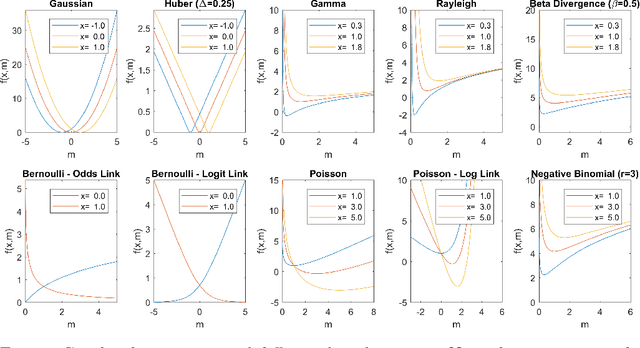
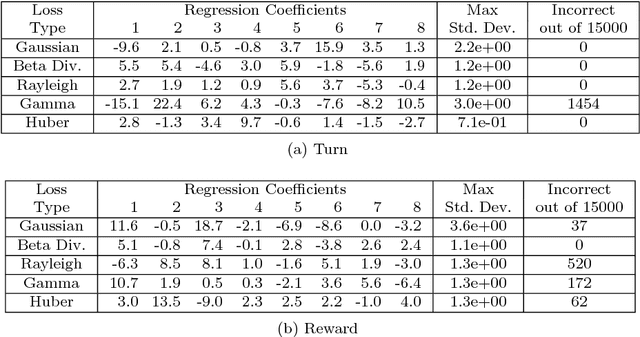
Tensor decomposition is a fundamental unsupervised machine learning method in data science, with applications including network analysis and sensor data processing. This work develops a generalized canonical polyadic (GCP) low-rank tensor decomposition that allows other loss functions besides squared error. For instance, we can use logistic loss or Kullback-Leibler divergence, enabling tensor decomposition for binary or count data. We present a variety statistically-motivated loss functions for various scenarios. We provide a generalized framework for computing gradients and handling missing data that enables the use of standard optimization methods for fitting the model. We demonstrate the flexibility of GCP on several real-world examples including interactions in a social network, neural activity in a mouse, and monthly rainfall measurements in India.