 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParsimonious Inference
Paper and Code
Mar 03, 2021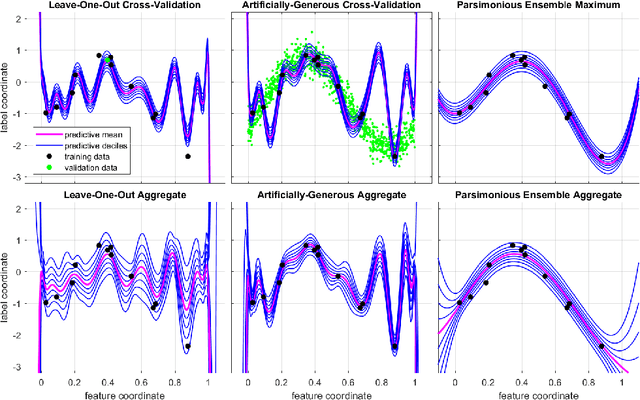

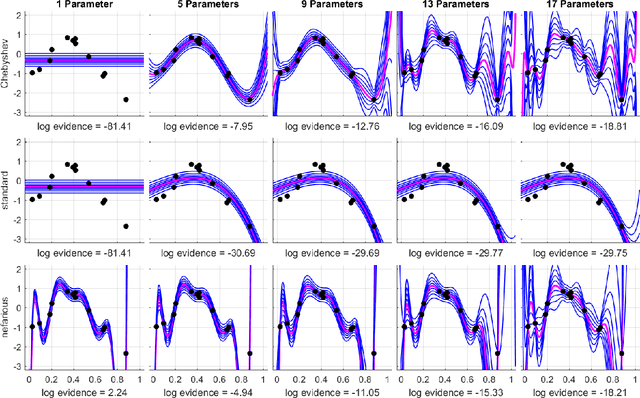
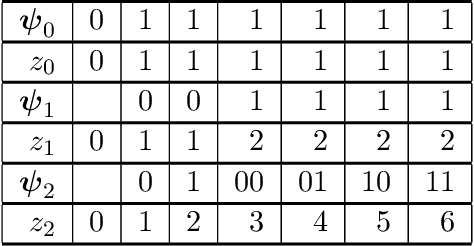
Bayesian inference provides a uniquely rigorous approach to obtain principled justification for uncertainty in predictions, yet it is difficult to articulate suitably general prior belief in the machine learning context, where computational architectures are pure abstractions subject to frequent modifications by practitioners attempting to improve results. Parsimonious inference is an information-theoretic formulation of inference over arbitrary architectures that formalizes Occam's Razor; we prefer simple and sufficient explanations. Our universal hyperprior assigns plausibility to prior descriptions, encoded as sequences of symbols, by expanding on the core relationships between program length, Kolmogorov complexity, and Solomonoff's algorithmic probability. We then cast learning as information minimization over our composite change in belief when an architecture is specified, training data are observed, and model parameters are inferred. By distinguishing model complexity from prediction information, our framework also quantifies the phenomenon of memorization. Although our theory is general, it is most critical when datasets are limited, e.g. small or skewed. We develop novel algorithms for polynomial regression and random forests that are suitable for such data, as demonstrated by our experiments. Our approaches combine efficient encodings with prudent sampling strategies to construct predictive ensembles without cross-validation, thus addressing a fundamental challenge in how to efficiently obtain predictions from data.