 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Meteorological and Operational Data: A Novel Approach to Understanding Railway Delays in Finland
Jan 23, 2026Train delays result from complex interactions between operational, technical, and environmental factors. While weather impacts railway reliability, particularly in Nordic regions, existing datasets rarely integrate meteorological information with operational train data. This study presents the first publicly available dataset combining Finnish railway operations with synchronized meteorological observations from 2018-2024. The dataset integrates operational metrics from Finland Digitraffic Railway Traffic Service with weather measurements from 209 environmental monitoring stations, using spatial-temporal alignment via Haversine distance. It encompasses 28 engineered features across operational variables and meteorological measurements, covering approximately 38.5 million observations from Finland's 5,915-kilometer rail network. Preprocessing includes strategic missing data handling through spatial fallback algorithms, cyclical encoding of temporal features, and robust scaling of weather data to address sensor outliers. Analysis reveals distinct seasonal patterns, with winter months exhibiting delay rates exceeding 25\% and geographic clustering of high-delay corridors in central and northern Finland. Furthermore, the work demonstrates applications of the data set in analysing the reliability of railway traffic in Finland. A baseline experiment using XGBoost regression achieved a Mean Absolute Error of 2.73 minutes for predicting station-specific delays, demonstrating the dataset's utility for machine learning applications. The dataset enables diverse applications, including train delay prediction, weather impact assessment, and infrastructure vulnerability mapping, providing researchers with a flexible resource for machine learning applications in railway operations research.
Probabilistic Allocation of Payload Code Rate and Header Copies in LR-FHSS Networks
Oct 07, 2024



We evaluate the performance of the LoRaWAN Long-Range Frequency Hopping Spread Spectrum (LR-FHSS) technique using a device-level probabilistic strategy for code rate and header replica allocation. Specifically, we investigate the effects of different header replica and code rate allocations at each end-device, guided by a probability distribution provided by the network server. As a benchmark, we compare the proposed strategy with the standardized LR-FHSS data rates DR8 and DR9. Our numerical results demonstrate that the proposed strategy consistently outperforms the DR8 and DR9 standard data rates across all considered scenarios. Notably, our findings reveal that the optimal distribution rarely includes data rate DR9, while data rate DR8 significantly contributes to the goodput and energy efficiency optimizations.
Non-Orthogonal Multiple-Access Strategies for Direct-to-Satellite IoT Networks
Sep 04, 2024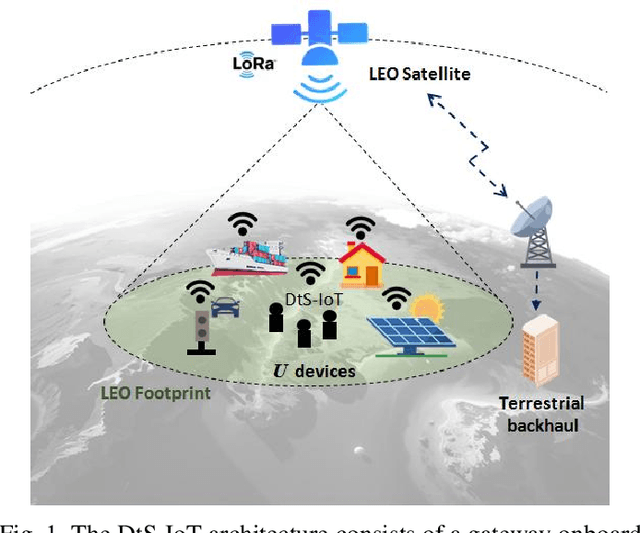
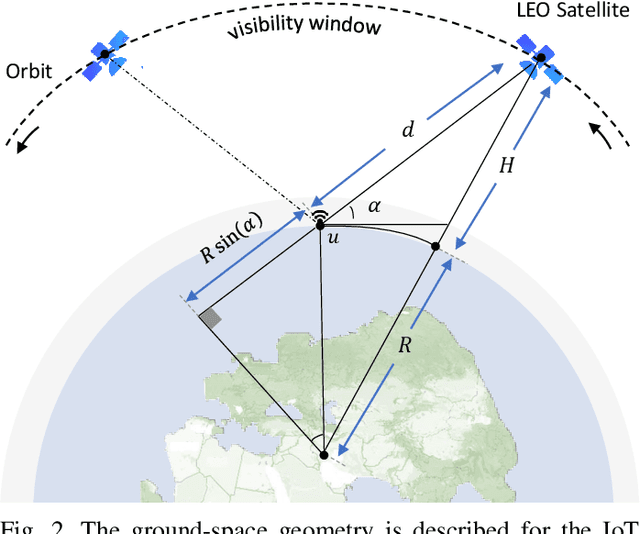
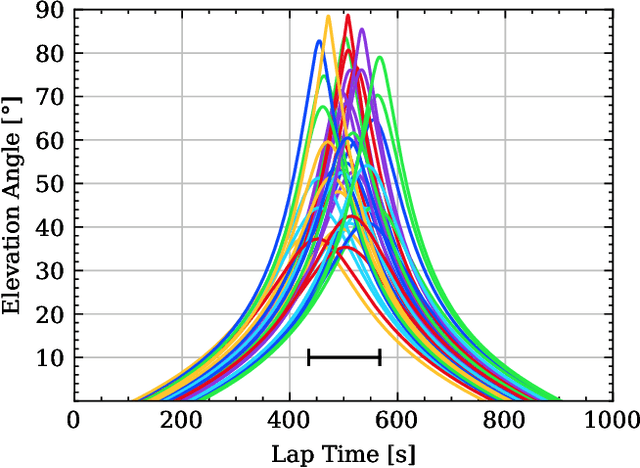
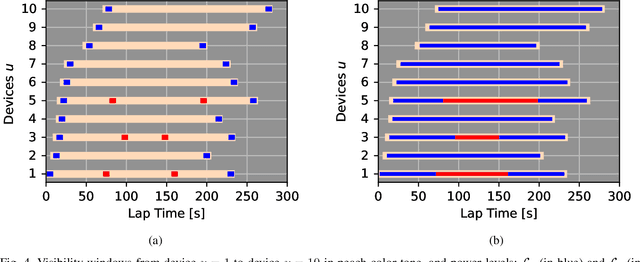
Direct-to-Satellite IoT (DtS-IoT) has the potential to support multiple verticals, including agriculture, industry, smart cities, and environmental disaster prevention. This work introduces two novel DtS-IoT schemes using power domain NonOrthogonal Multiple Access (NOMA) in the uplink with either fixed (FTP) or controlled (CTP) transmit power. We consider that the IoT devices use LoRa technology to transmit data packets to the satellite in orbit, equipped with a Successive Interference Cancellation (SIC)-enabled gateway. We also assume the IoT devices are empowered with a predictor of the satellite orbit. Using real geographic location and trajectory data, we evaluate the performance of the average number of successfully decoded transmissions, goodput (bytes/lap), and energy consumption (bytes/Joule) as a function of the number of network devices. Numerical results show the trade-off between goodput and energy efficiency for both proposed schemes. Comparing FTP and CTP with regular ALOHA for 100 (600) devices, we find goodput improvements of 65% (29%) and 52% (101%), respectively. Notably, CTP effectively leverages transmission opportunities as the network size increases, outperforming the other strategies. Moreover, CTP shows the best performance in energy efficiency compared to FTP and ALOHA.
Multi-UAV Path Learning for Age and Power Optimization in IoT with UAV Battery Recharge
Jan 09, 2023



In many emerging Internet of Things (IoT) applications, the freshness of the is an important design criterion. Age of Information (AoI) quantifies the freshness of the received information or status update. This work considers a setup of deployed IoT devices in an IoT network; multiple unmanned aerial vehicles (UAVs) serve as mobile relay nodes between the sensors and the base station. We formulate an optimization problem to jointly plan the UAVs' trajectory, while minimizing the AoI of the received messages and the devices' energy consumption. The solution accounts for the UAVs' battery lifetime and flight time to recharging depots to ensure the UAVs' green operation. The complex optimization problem is efficiently solved using a deep reinforcement learning algorithm. In particular, we propose a deep Q-network, which works as a function approximation to estimate the state-action value function. The proposed scheme is quick to converge and results in a lower ergodic age and ergodic energy consumption when compared with benchmark algorithms such as greedy algorithm (GA), nearest neighbour (NN), and random-walk (RW).
A Learning-Based Trajectory Planning of Multiple UAVs for AoI Minimization in IoT Networks
Sep 13, 2022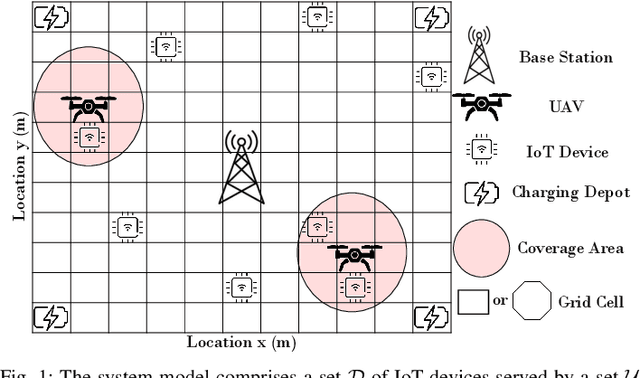
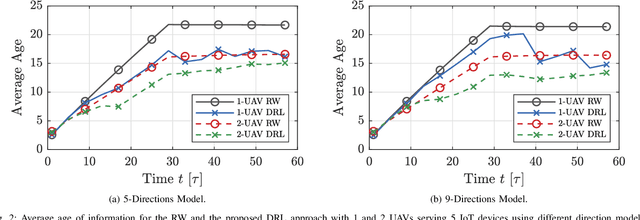
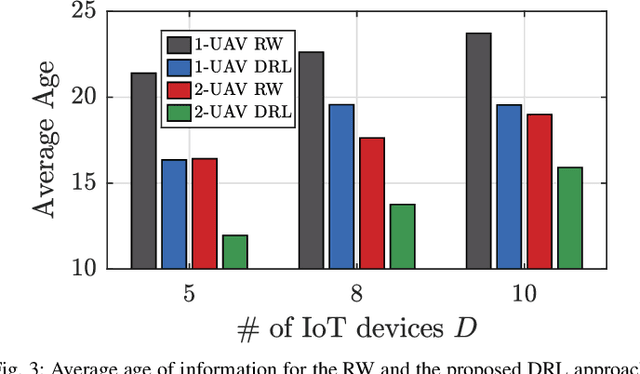
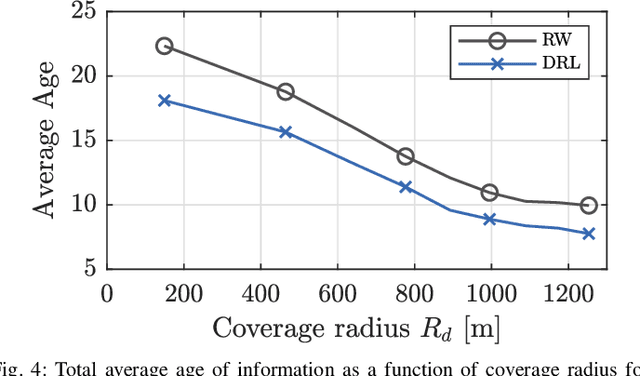
Many emerging Internet of Things (IoT) applications rely on information collected by sensor nodes where the freshness of information is an important criterion. \textit{Age of Information} (AoI) is a metric that quantifies information timeliness, i.e., the freshness of the received information or status update. This work considers a setup of deployed sensors in an IoT network, where multiple unmanned aerial vehicles (UAVs) serve as mobile relay nodes between the sensors and the base station. We formulate an optimization problem to jointly plan the UAVs' trajectory, while minimizing the AoI of the received messages. This ensures that the received information at the base station is as fresh as possible. The complex optimization problem is efficiently solved using a deep reinforcement learning (DRL) algorithm. In particular, we propose a deep Q-network, which works as a function approximation to estimate the state-action value function. The proposed scheme is quick to converge and results in a lower AoI than the random walk scheme. Our proposed algorithm reduces the average age by approximately $25\%$ and requires down to $50\%$ less energy when compared to the baseline scheme.