 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Kernels to Features: A Multi-Scale Adaptive Theory of Feature Learning
Feb 05, 2025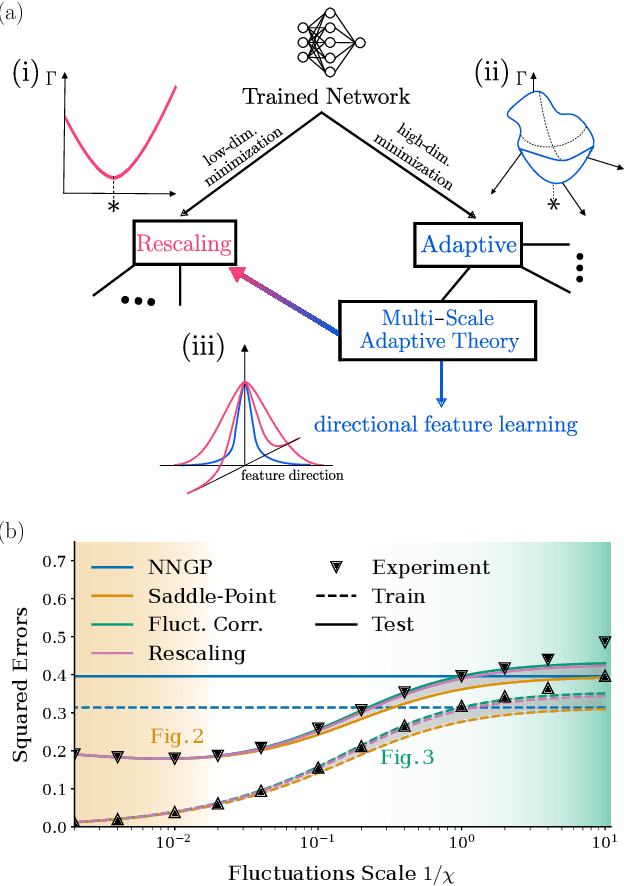


Theoretically describing feature learning in neural networks is crucial for understanding their expressive power and inductive biases, motivating various approaches. Some approaches describe network behavior after training through a simple change in kernel scale from initialization, resulting in a generalization power comparable to a Gaussian process. Conversely, in other approaches training results in the adaptation of the kernel to the data, involving complex directional changes to the kernel. While these approaches capture different facets of network behavior, their relationship and respective strengths across scaling regimes remains an open question. This work presents a theoretical framework of multi-scale adaptive feature learning bridging these approaches. Using methods from statistical mechanics, we derive analytical expressions for network output statistics which are valid across scaling regimes and in the continuum between them. A systematic expansion of the network's probability distribution reveals that mean-field scaling requires only a saddle-point approximation, while standard scaling necessitates additional correction terms. Remarkably, we find across regimes that kernel adaptation can be reduced to an effective kernel rescaling when predicting the mean network output of a linear network. However, even in this case, the multi-scale adaptive approach captures directional feature learning effects, providing richer insights than what could be recovered from a rescaling of the kernel alone.
A theory of data variability in Neural Network Bayesian inference
Jul 31, 2023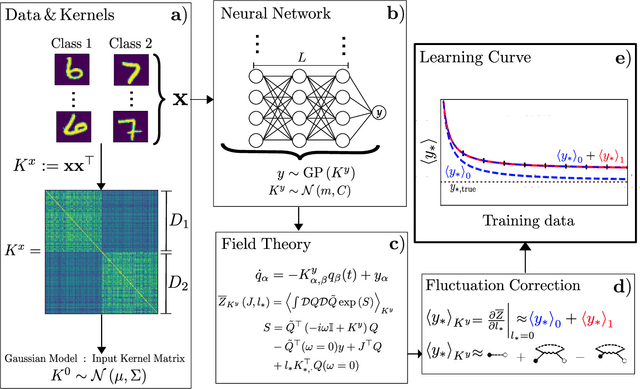



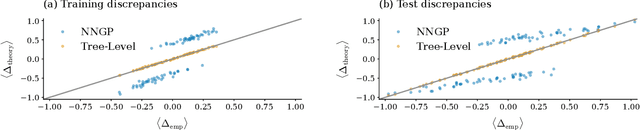
Bayesian inference and kernel methods are well established in machine learning. The neural network Gaussian process in particular provides a concept to investigate neural networks in the limit of infinitely wide hidden layers by using kernel and inference methods. Here we build upon this limit and provide a field-theoretic formalism which covers the generalization properties of infinitely wide networks. We systematically compute generalization properties of linear, non-linear, and deep non-linear networks for kernel matrices with heterogeneous entries. In contrast to currently employed spectral methods we derive the generalization properties from the statistical properties of the input, elucidating the interplay of input dimensionality, size of the training data set, and variability of the data. We show that data variability leads to a non-Gaussian action reminiscent of a ($\varphi^3+\varphi^4$)-theory. Using our formalism on a synthetic task and on MNIST we obtain a homogeneous kernel matrix approximation for the learning curve as well as corrections due to data variability which allow the estimation of the generalization properties and exact results for the bounds of the learning curves in the case of infinitely many training data points.