 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrossmodal Attentive Skill Learner
May 22, 2018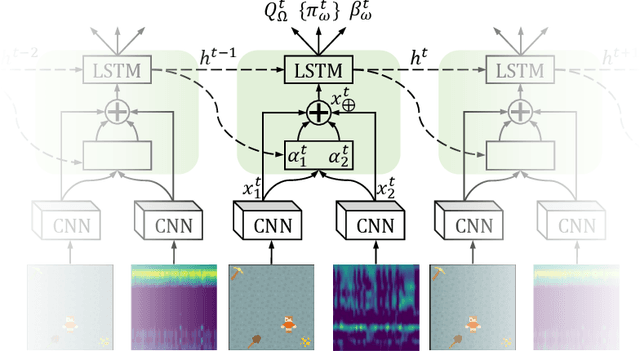
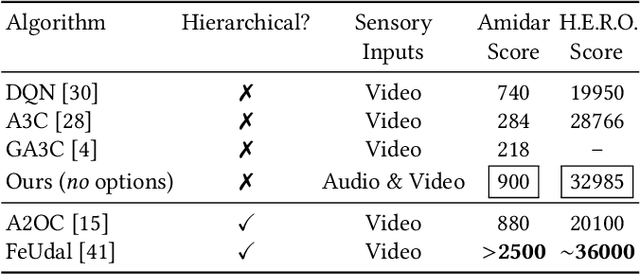
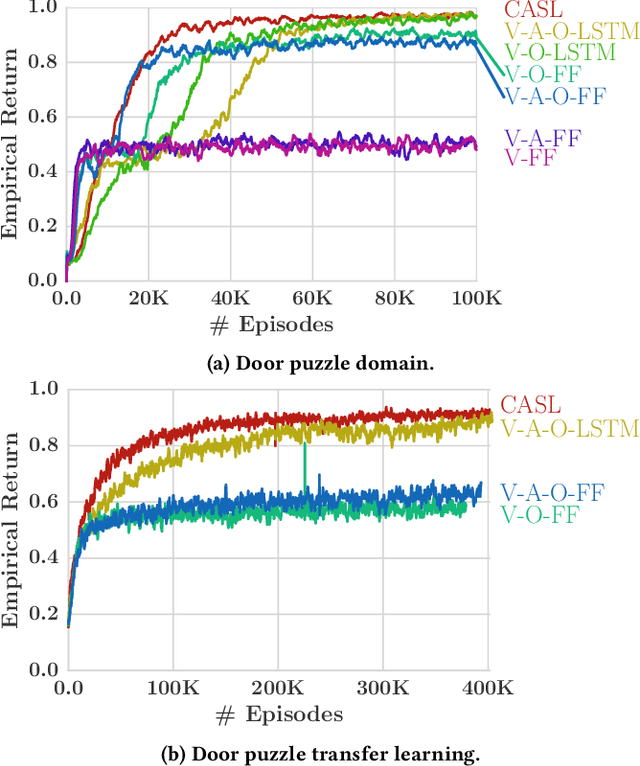
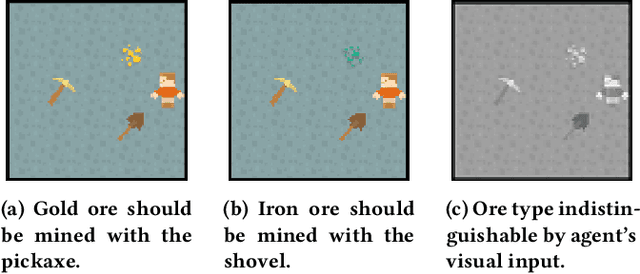
This paper presents the Crossmodal Attentive Skill Learner (CASL), integrated with the recently-introduced Asynchronous Advantage Option-Critic (A2OC) architecture [Harb et al., 2017] to enable hierarchical reinforcement learning across multiple sensory inputs. We provide concrete examples where the approach not only improves performance in a single task, but accelerates transfer to new tasks. We demonstrate the attention mechanism anticipates and identifies useful latent features, while filtering irrelevant sensor modalities during execution. We modify the Arcade Learning Environment [Bellemare et al., 2013] to support audio queries, and conduct evaluations of crossmodal learning in the Atari 2600 game Amidar. Finally, building on the recent work of Babaeizadeh et al. [2017], we open-source a fast hybrid CPU-GPU implementation of CASL.
Deep Decentralized Multi-task Multi-Agent Reinforcement Learning under Partial Observability
Jul 13, 2017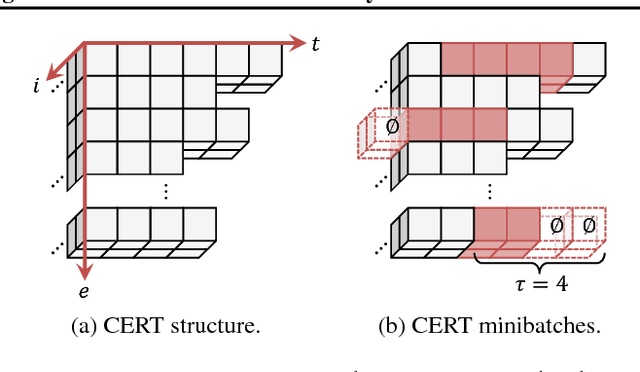
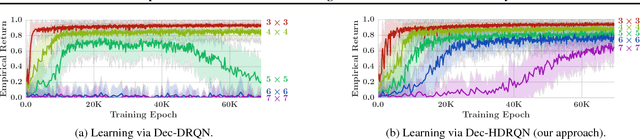
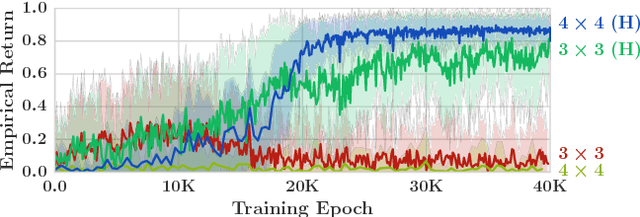
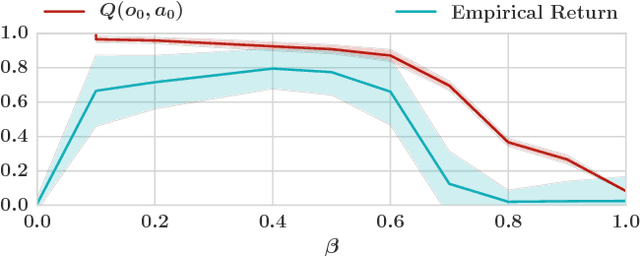
Many real-world tasks involve multiple agents with partial observability and limited communication. Learning is challenging in these settings due to local viewpoints of agents, which perceive the world as non-stationary due to concurrently-exploring teammates. Approaches that learn specialized policies for individual tasks face problems when applied to the real world: not only do agents have to learn and store distinct policies for each task, but in practice identities of tasks are often non-observable, making these approaches inapplicable. This paper formalizes and addresses the problem of multi-task multi-agent reinforcement learning under partial observability. We introduce a decentralized single-task learning approach that is robust to concurrent interactions of teammates, and present an approach for distilling single-task policies into a unified policy that performs well across multiple related tasks, without explicit provision of task identity.
* Accepted to ICML 2017