 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Decentralized Multi-task Multi-Agent Reinforcement Learning under Partial Observability
Paper and Code
Jul 13, 2017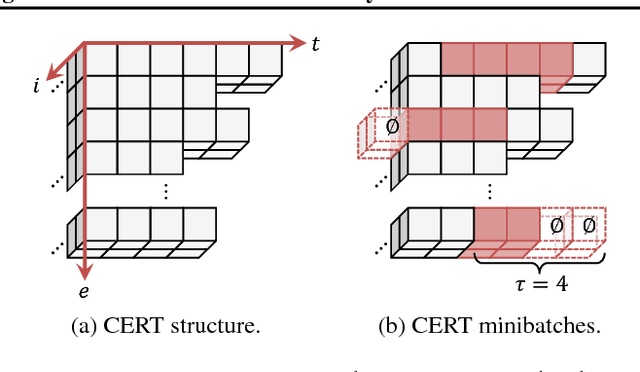
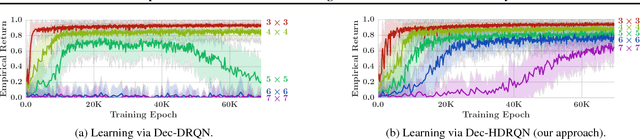
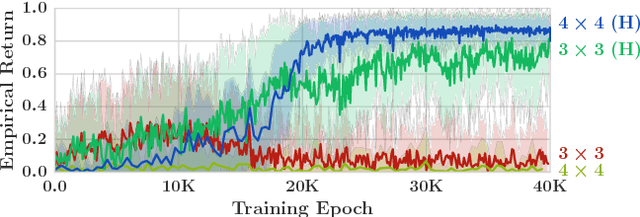
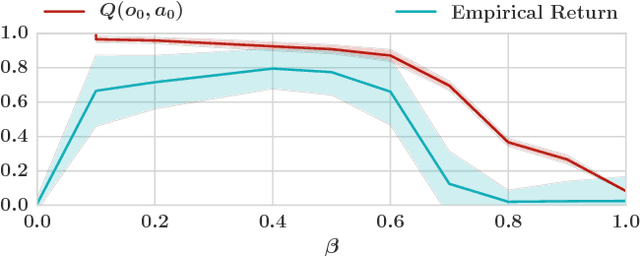
Many real-world tasks involve multiple agents with partial observability and limited communication. Learning is challenging in these settings due to local viewpoints of agents, which perceive the world as non-stationary due to concurrently-exploring teammates. Approaches that learn specialized policies for individual tasks face problems when applied to the real world: not only do agents have to learn and store distinct policies for each task, but in practice identities of tasks are often non-observable, making these approaches inapplicable. This paper formalizes and addresses the problem of multi-task multi-agent reinforcement learning under partial observability. We introduce a decentralized single-task learning approach that is robust to concurrent interactions of teammates, and present an approach for distilling single-task policies into a unified policy that performs well across multiple related tasks, without explicit provision of task identity.