 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActionable Cognitive Twins for Decision Making in Manufacturing
Mar 23, 2021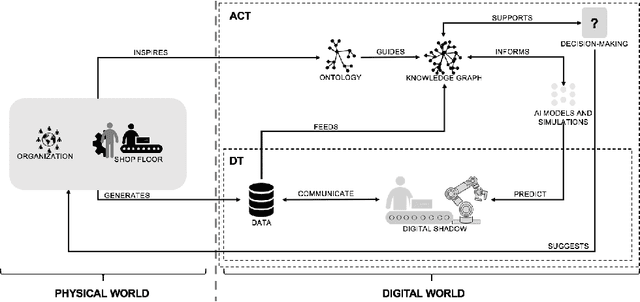
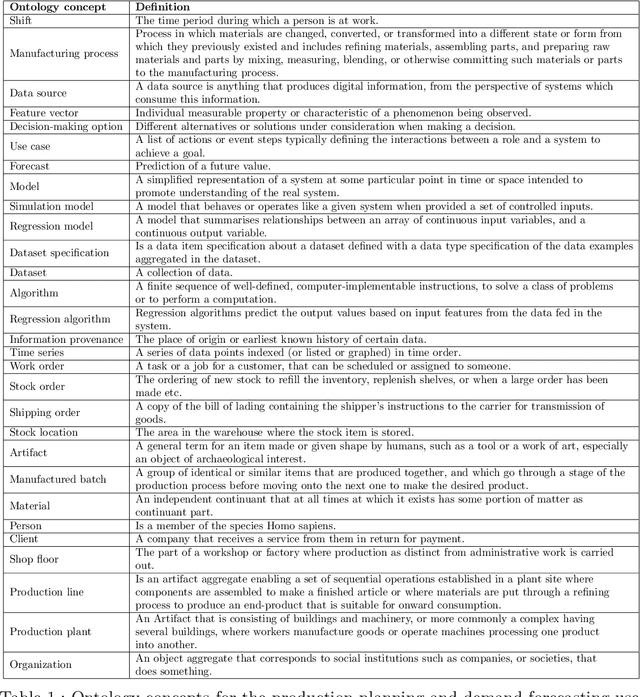
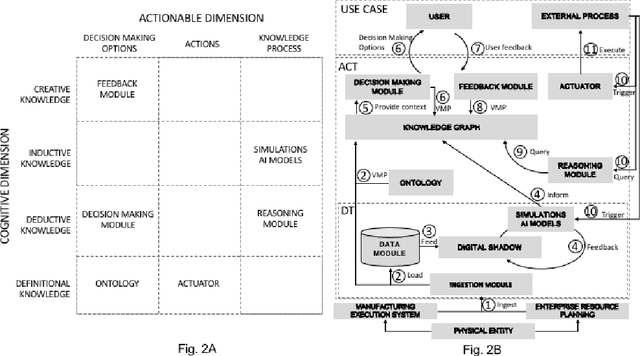
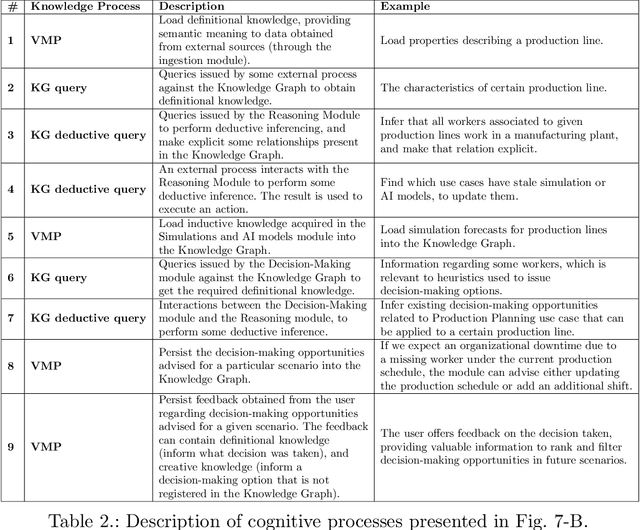
Actionable Cognitive Twins are the next generation Digital Twins enhanced with cognitive capabilities through a knowledge graph and artificial intelligence models that provide insights and decision-making options to the users. The knowledge graph describes the domain-specific knowledge regarding entities and interrelationships related to a manufacturing setting. It also contains information on possible decision-making options that can assist decision-makers, such as planners or logisticians. In this paper, we propose a knowledge graph modeling approach to construct actionable cognitive twins for capturing specific knowledge related to demand forecasting and production planning in a manufacturing plant. The knowledge graph provides semantic descriptions and contextualization of the production lines and processes, including data identification and simulation or artificial intelligence algorithms and forecasts used to support them. Such semantics provide ground for inferencing, relating different knowledge types: creative, deductive, definitional, and inductive. To develop the knowledge graph models for describing the use case completely, systems thinking approach is proposed to design and verify the ontology, develop a knowledge graph and build an actionable cognitive twin. Finally, we evaluate our approach in two use cases developed for a European original equipment manufacturer related to the automotive industry as part of the European Horizon 2020 project FACTLOG.
News Across Languages - Cross-Lingual Document Similarity and Event Tracking
Dec 22, 2015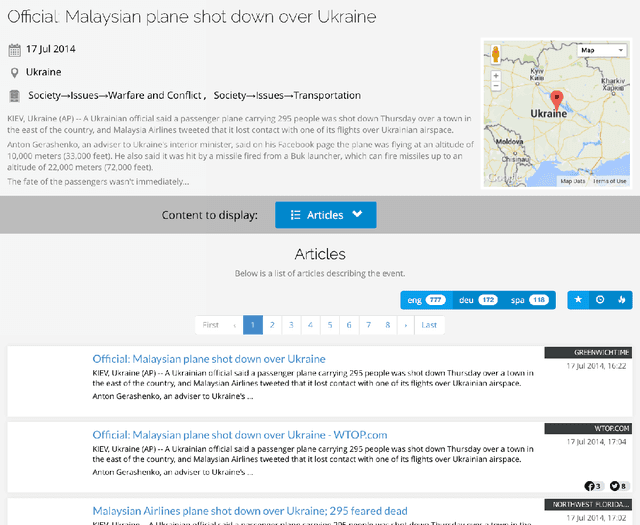

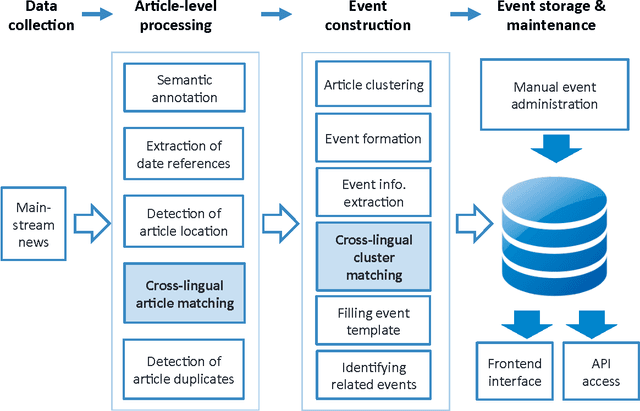
In today's world, we follow news which is distributed globally. Significant events are reported by different sources and in different languages. In this work, we address the problem of tracking of events in a large multilingual stream. Within a recently developed system Event Registry we examine two aspects of this problem: how to compare articles in different languages and how to link collections of articles in different languages which refer to the same event. Taking a multilingual stream and clusters of articles from each language, we compare different cross-lingual document similarity measures based on Wikipedia. This allows us to compute the similarity of any two articles regardless of language. Building on previous work, we show there are methods which scale well and can compute a meaningful similarity between articles from languages with little or no direct overlap in the training data. Using this capability, we then propose an approach to link clusters of articles across languages which represent the same event. We provide an extensive evaluation of the system as a whole, as well as an evaluation of the quality and robustness of the similarity measure and the linking algorithm.
Algorithms of the LDA model [REPORT]
Jul 01, 2013![Figure 1 for Algorithms of the LDA model [REPORT]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fa8f5e011bd33efa6cad7dc416b8077c2844bc2b7%2F1-Figure1-1.png&w=640&q=75)
![Figure 2 for Algorithms of the LDA model [REPORT]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fa8f5e011bd33efa6cad7dc416b8077c2844bc2b7%2F3-Figure2-1.png&w=640&q=75)
![Figure 3 for Algorithms of the LDA model [REPORT]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fa8f5e011bd33efa6cad7dc416b8077c2844bc2b7%2F4-Figure3-1.png&w=640&q=75)
![Figure 4 for Algorithms of the LDA model [REPORT]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fa8f5e011bd33efa6cad7dc416b8077c2844bc2b7%2F4-Figure4-1.png&w=640&q=75)
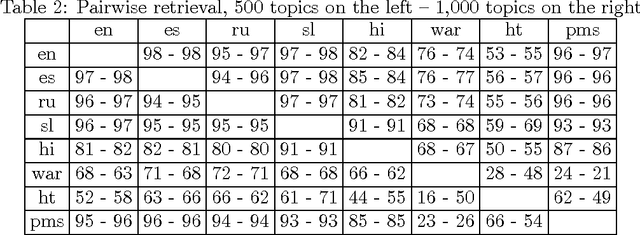
We review three algorithms for Latent Dirichlet Allocation (LDA). Two of them are variational inference algorithms: Variational Bayesian inference and Online Variational Bayesian inference and one is Markov Chain Monte Carlo (MCMC) algorithm -- Collapsed Gibbs sampling. We compare their time complexity and performance. We find that online variational Bayesian inference is the fastest algorithm and still returns reasonably good results.
A Comparison of Relaxations of Multiset Cannonical Correlation Analysis and Applications
Feb 05, 2013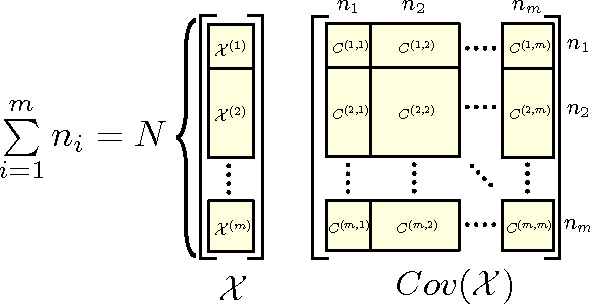
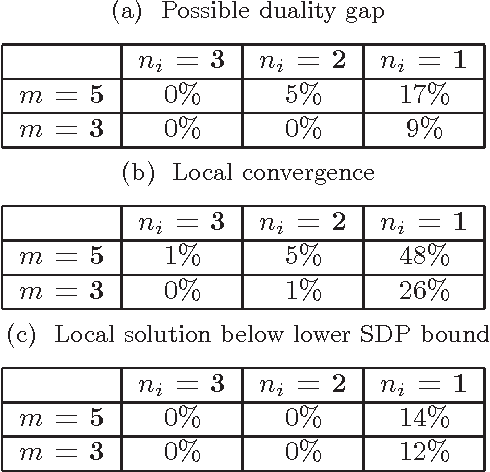
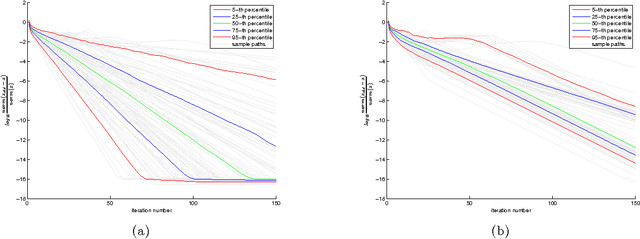
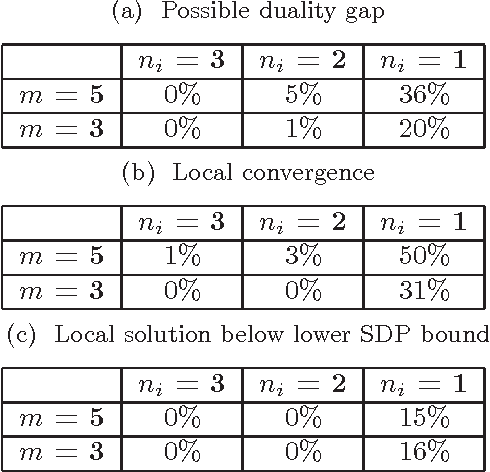
Canonical correlation analysis is a statistical technique that is used to find relations between two sets of variables. An important extension in pattern analysis is to consider more than two sets of variables. This problem can be expressed as a quadratically constrained quadratic program (QCQP), commonly referred to Multi-set Canonical Correlation Analysis (MCCA). This is a non-convex problem and so greedy algorithms converge to local optima without any guarantees on global optimality. In this paper, we show that despite being highly structured, finding the optimal solution is NP-Hard. This motivates our relaxation of the QCQP to a semidefinite program (SDP). The SDP is convex, can be solved reasonably efficiently and comes with both absolute and output-sensitive approximation quality. In addition to theoretical guarantees, we do an extensive comparison of the QCQP method and the SDP relaxation on a variety of synthetic and real world data. Finally, we present two useful extensions: we incorporate kernel methods and computing multiple sets of canonical vectors.