 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring and Analyzing Subjective Uncertainty in Scientific Communications
Mar 27, 2025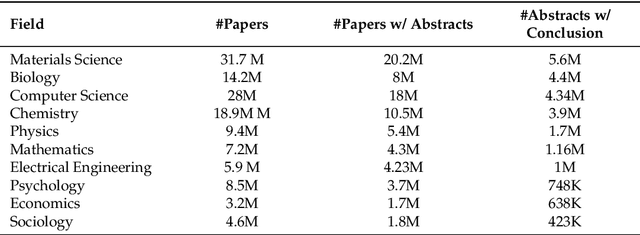
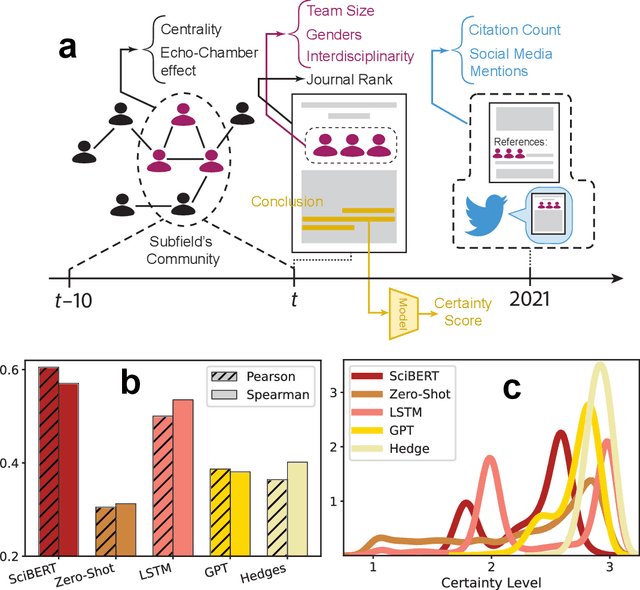
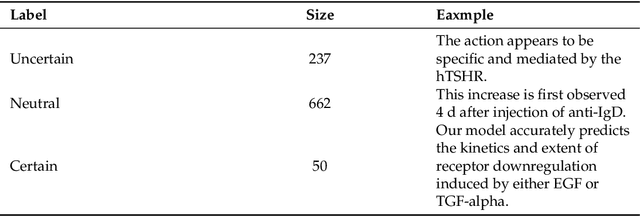
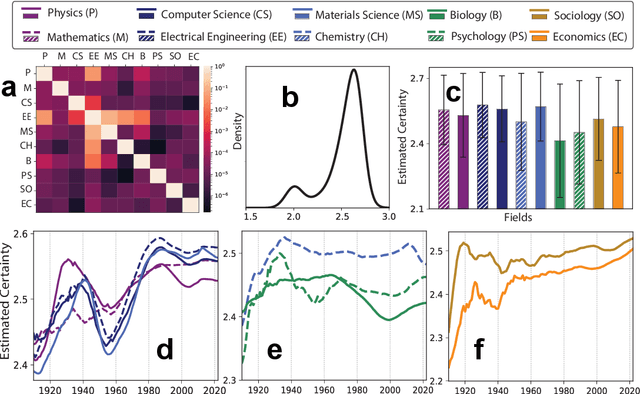
Uncertainty of scientific findings are typically reported through statistical metrics such as $p$-values, confidence intervals, etc. The magnitude of this objective uncertainty is reflected in the language used by the authors to report their findings primarily through expressions carrying uncertainty-inducing terms or phrases. This language uncertainty is a subjective concept and is highly dependent on the writing style of the authors. There is evidence that such subjective uncertainty influences the impact of science on public audience. In this work, we turned our focus to scientists themselves, and measured/analyzed the subjective uncertainty and its impact within scientific communities across different disciplines. We showed that the level of this type of uncertainty varies significantly across different fields, years of publication and geographical locations. We also studied the correlation between subjective uncertainty and several bibliographical metrics, such as number/gender of authors, centrality of the field's community, citation count, etc. The underlying patterns identified in this work are useful in identification and documentation of linguistic norms in scientific communication in different communities/societies.
Accelerating science with human-aware artificial intelligence
Jun 02, 2023Artificial intelligence (AI) models trained on published scientific findings have been used to invent valuable materials and targeted therapies, but they typically ignore the human scientists who continually alter the landscape of discovery. Here we show that incorporating the distribution of human expertise by training unsupervised models on simulated inferences cognitively accessible to experts dramatically improves (up to 400%) AI prediction of future discoveries beyond those focused on research content alone, especially when relevant literature is sparse. These models succeed by predicting human predictions and the scientists who will make them. By tuning human-aware AI to avoid the crowd, we can generate scientifically promising "alien" hypotheses unlikely to be imagined or pursued without intervention until the distant future, which hold promise to punctuate scientific advance beyond questions currently pursued. Accelerating human discovery or probing its blind spots, human-aware AI enables us to move toward and beyond the contemporary scientific frontier.
Complementary artificial intelligence designed to augment human discovery
Jul 02, 2022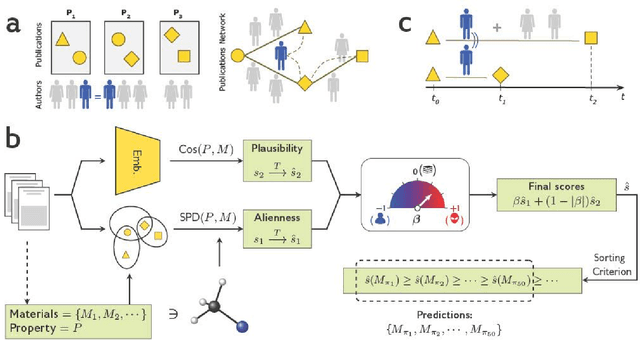
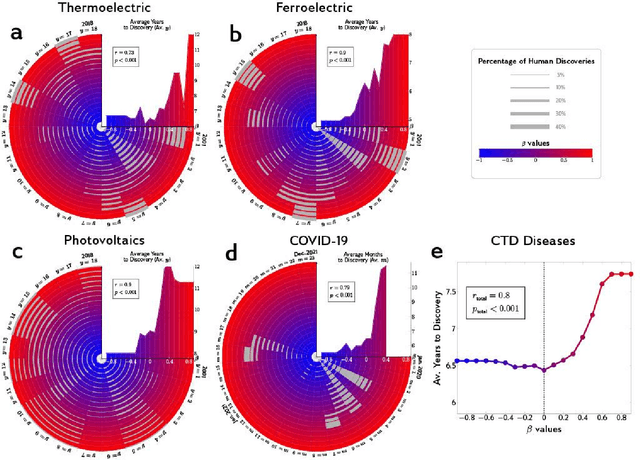
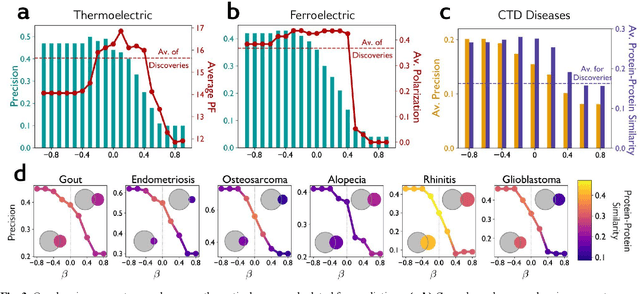
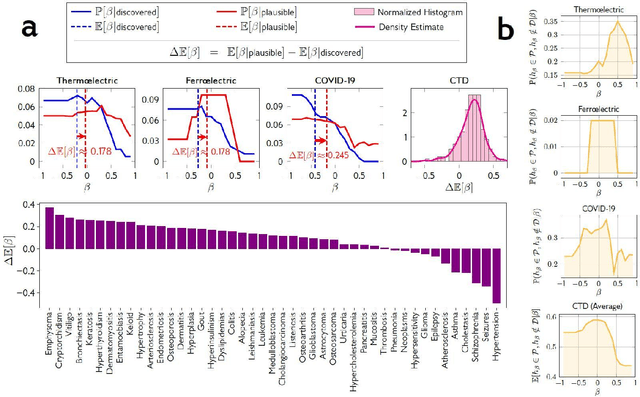
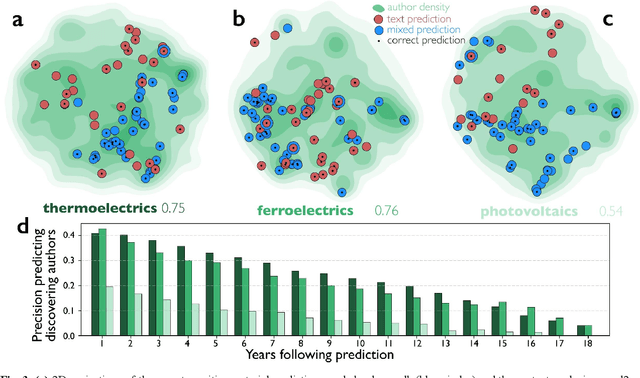
Neither artificial intelligence designed to play Turing's imitation game, nor augmented intelligence built to maximize the human manipulation of information are tuned to accelerate innovation and improve humanity's collective advance against its greatest challenges. We reconceptualize and pilot beneficial AI to radically augment human understanding by complementing rather than competing with human cognitive capacity. Our approach to complementary intelligence builds on insights underlying the wisdom of crowds, which hinges on the independence and diversity of crowd members' information and approach. By programmatically incorporating information on the evolving distribution of scientific expertise from research papers, our approach follows the distribution of content in the literature while avoiding the scientific crowd and the hypotheses cognitively available to it. We use this approach to generate valuable predictions for what materials possess valuable energy-related properties (e.g., thermoelectricity), and what compounds possess valuable medical properties (e.g., asthma) that complement the human scientific crowd. We demonstrate that our complementary predictions, if identified by human scientists and inventors at all, are only discovered years further into the future. When we evaluate the promise of our predictions with first-principles equations, we demonstrate that increased complementarity of our predictions does not decrease and in some cases increases the probability that the predictions possess the targeted properties. In summary, by tuning AI to avoid the crowd, we can generate hypotheses unlikely to be imagined or pursued until the distant future and promise to punctuate scientific advance. By identifying and correcting for collective human bias, these models also suggest opportunities to improve human prediction by reformulating science education for discovery.
Accelerating science with human versus alien artificial intelligences
Apr 12, 2021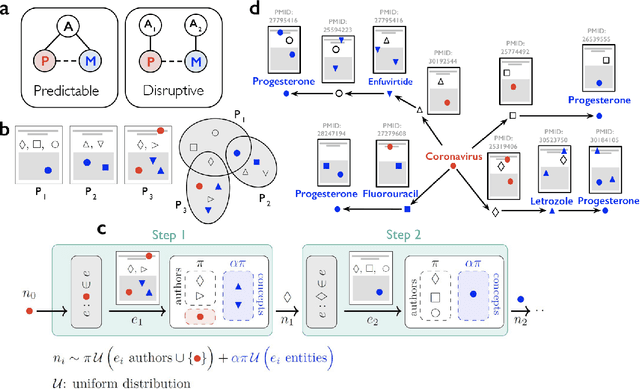
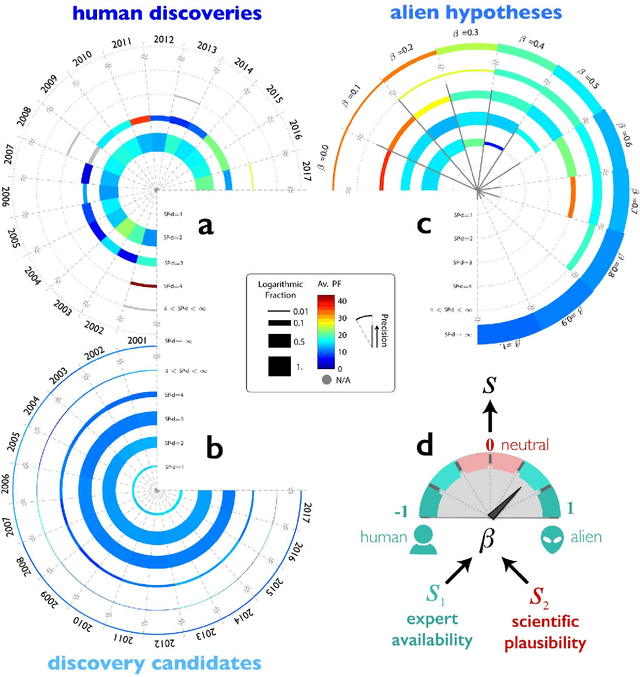
Data-driven artificial intelligence models fed with published scientific findings have been used to create powerful prediction engines for scientific and technological advance, such as the discovery of novel materials with desired properties and the targeted invention of new therapies and vaccines. These AI approaches typically ignore the distribution of human prediction engines -- scientists and inventor -- who continuously alter the landscape of discovery and invention. As a result, AI hypotheses are designed to substitute for human experts, failing to complement them for punctuated collective advance. Here we show that incorporating the distribution of human expertise into self-supervised models by training on inferences cognitively available to experts dramatically improves AI prediction of future human discoveries and inventions. Including expert-awareness into models that propose (a) valuable energy-relevant materials increases the precision of materials predictions by ~100%, (b) repurposing thousands of drugs to treat new diseases increases precision by 43%, and (c) COVID-19 vaccine candidates examined in clinical trials by 260%. These models succeed by predicting human predictions and the scientists who will make them. By tuning AI to avoid the crowd, however, it generates scientifically promising "alien" hypotheses unlikely to be imagined or pursued without intervention, not only accelerating but punctuating scientific advance. By identifying and correcting for collective human bias, these models also suggest opportunities to improve human prediction by reformulating science education for discovery.
Towards Robust and Reproducible Active Learning Using Neural Networks
Feb 21, 2020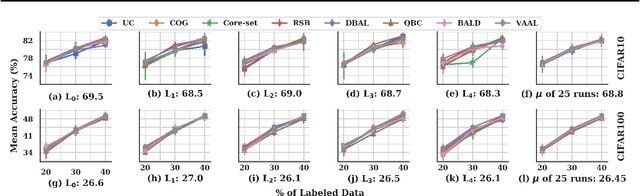
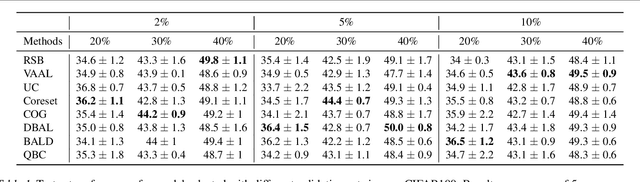
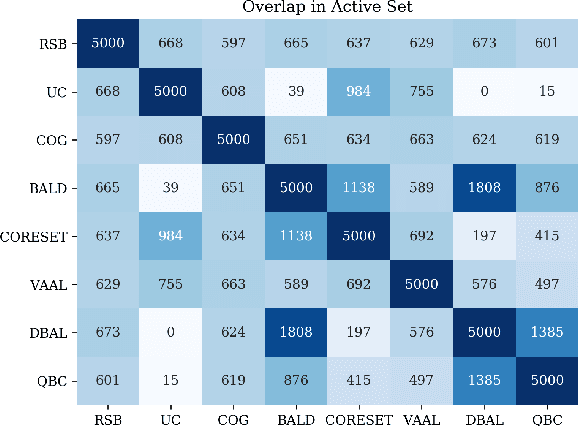
Active learning (AL) is a promising ML paradigm that has the potential to parse through large unlabeled data and help reduce annotation cost in domains where labeling entire data can be prohibitive. Recently proposed neural network based AL methods use different heuristics to accomplish this goal. In this study, we show that recent AL methods offer a gain over random baseline under a brittle combination of experimental conditions. We demonstrate that such marginal gains vanish when experimental factors are changed, leading to reproducibility issues and suggesting that AL methods lack robustness. We also observe that with a properly tuned model, which employs recently proposed regularization techniques, the performance significantly improves for all AL methods including the random sampling baseline, and performance differences among the AL methods become negligible. Based on these observations, we suggest a set of experiments that are critical to assess the true effectiveness of an AL method. To facilitate these experiments we also present an open source toolkit. We believe our findings and recommendations will help advance reproducible research in robust AL using neural networks.
Asymptotic Analysis of Objectives based on Fisher Information in Active Learning
Oct 14, 2016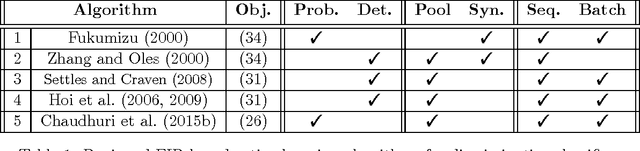

Obtaining labels can be costly and time-consuming. Active learning allows a learning algorithm to intelligently query samples to be labeled for efficient learning. Fisher information ratio (FIR) has been used as an objective for selecting queries in active learning. However, little is known about the theory behind the use of FIR for active learning. There is a gap between the underlying theory and the motivation of its usage in practice. In this paper, we attempt to fill this gap and provide a rigorous framework for analyzing existing FIR-based active learning methods. In particular, we show that FIR can be asymptotically viewed as an upper bound of the expected variance of the log-likelihood ratio. Additionally, our analysis suggests a unifying framework that not only enables us to make theoretical comparisons among the existing querying methods based on FIR, but also allows us to give insight into the development of new active learning approaches based on this objective.