 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust and Reproducible Active Learning Using Neural Networks
Paper and Code
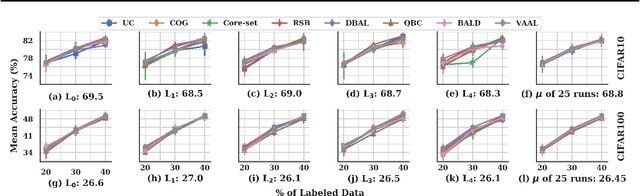
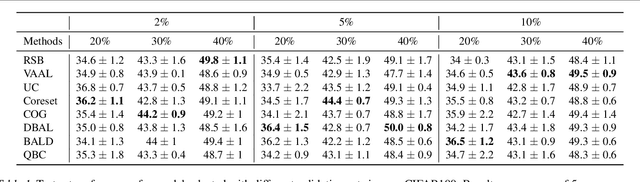
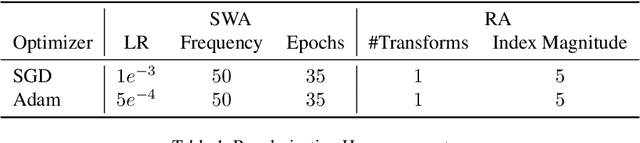
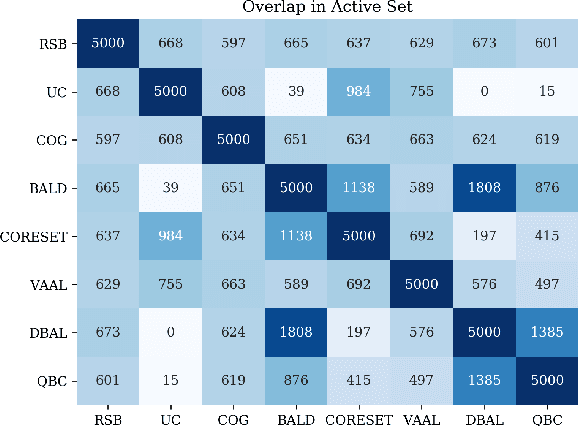
Active learning (AL) is a promising ML paradigm that has the potential to parse through large unlabeled data and help reduce annotation cost in domains where labeling entire data can be prohibitive. Recently proposed neural network based AL methods use different heuristics to accomplish this goal. In this study, we show that recent AL methods offer a gain over random baseline under a brittle combination of experimental conditions. We demonstrate that such marginal gains vanish when experimental factors are changed, leading to reproducibility issues and suggesting that AL methods lack robustness. We also observe that with a properly tuned model, which employs recently proposed regularization techniques, the performance significantly improves for all AL methods including the random sampling baseline, and performance differences among the AL methods become negligible. Based on these observations, we suggest a set of experiments that are critical to assess the true effectiveness of an AL method. To facilitate these experiments we also present an open source toolkit. We believe our findings and recommendations will help advance reproducible research in robust AL using neural networks.