 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Multimodal Large Language Models for Radiology Report Error-checking
Dec 20, 2023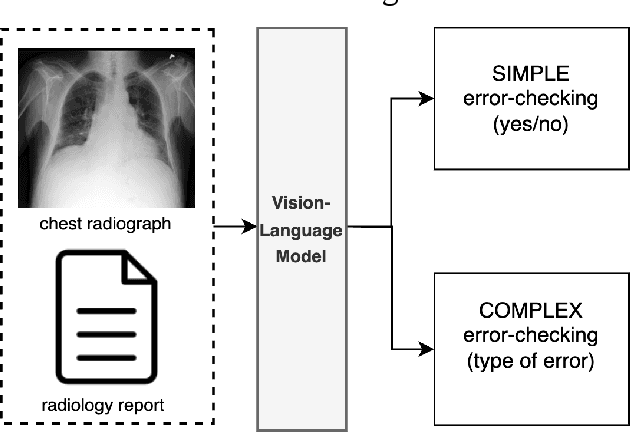


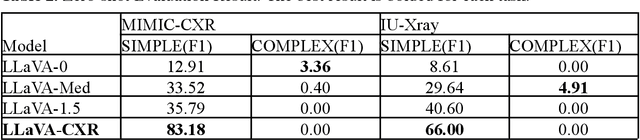
This paper proposes one of the first clinical applications of multimodal large language models (LLMs) as an assistant for radiologists to check errors in their reports. We created an evaluation dataset from two real-world radiology datasets (MIMIC-CXR and IU-Xray), with 1,000 subsampled reports each. A subset of original reports was modified to contain synthetic errors by introducing various type of mistakes. The evaluation contained two difficulty levels: SIMPLE for binary error-checking and COMPLEX for identifying error types. LLaVA (Large Language and Visual Assistant) variant models, including our instruction-tuned model, were used for the evaluation. Additionally, a domain expert evaluation was conducted on a small test set. At the SIMPLE level, the LLaVA v1.5 model outperformed other publicly available models. Instruction tuning significantly enhanced performance by 47.4% and 25.4% on MIMIC-CXR and IU-Xray data, respectively. The model also surpassed the domain experts accuracy in the MIMIC-CXR dataset by 1.67%. Notably, among the subsets (N=21) of the test set where a clinician did not achieve the correct conclusion, the LLaVA ensemble mode correctly identified 71.4% of these cases. This study marks a promising step toward utilizing multi-modal LLMs to enhance diagnostic accuracy in radiology. The ensemble model demonstrated comparable performance to clinicians, even capturing errors overlooked by humans. Nevertheless, future work is needed to improve the model ability to identify the types of inconsistency.