 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIHC-LLMiner: Automated extraction of tumour immunohistochemical profiles from PubMed abstracts using large language models
Apr 01, 2025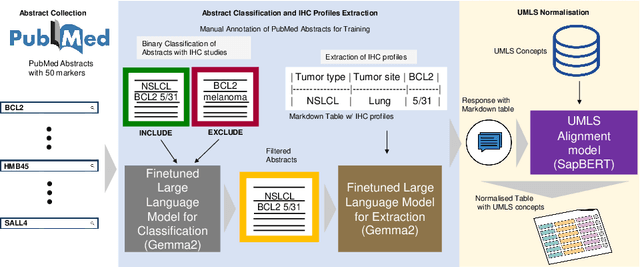
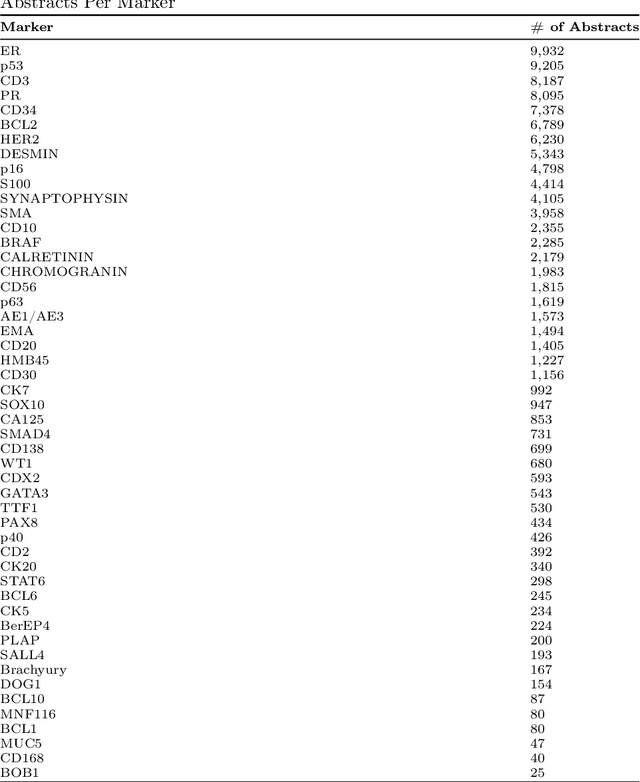
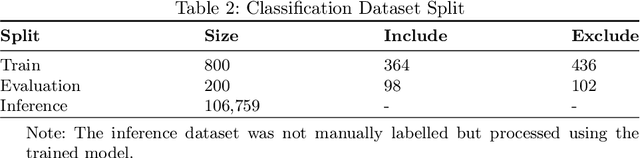
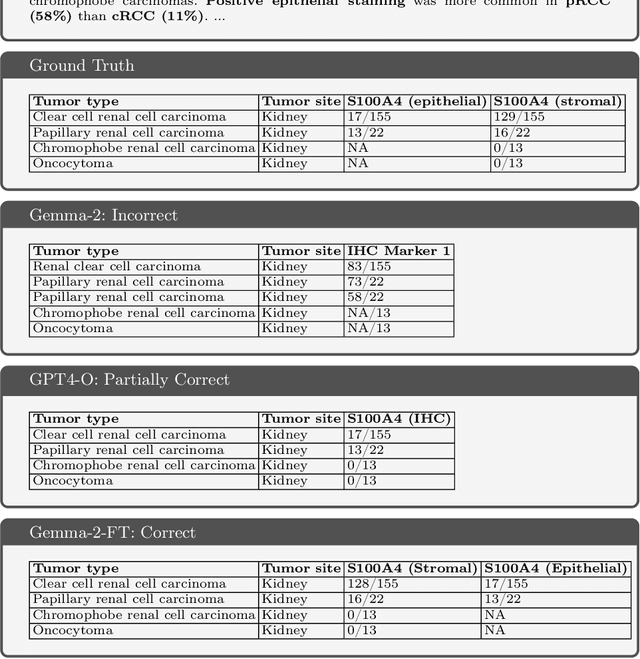
Immunohistochemistry (IHC) is essential in diagnostic pathology and biomedical research, offering critical insights into protein expression and tumour biology. This study presents an automated pipeline, IHC-LLMiner, for extracting IHC-tumour profiles from PubMed abstracts, leveraging advanced biomedical text mining. There are two subtasks: abstract classification (include/exclude as relevant) and IHC-tumour profile extraction on relevant included abstracts. The best-performing model, "Gemma-2 finetuned", achieved 91.5% accuracy and an F1 score of 91.4, outperforming GPT4-O by 9.5% accuracy with 5.9 times faster inference time. From an initial dataset of 107,759 abstracts identified for 50 immunohistochemical markers, the classification task identified 30,481 relevant abstracts (Include) using the Gemma-2 finetuned model. For IHC-tumour profile extraction, the Gemma-2 finetuned model achieved the best performance with 63.3% Correct outputs. Extracted IHC-tumour profiles (tumour types and markers) were normalised to Unified Medical Language System (UMLS) concepts to ensure consistency and facilitate IHC-tumour profile landscape analysis. The extracted IHC-tumour profiles demonstrated excellent concordance with available online summary data and provided considerable added value in terms of both missing IHC-tumour profiles and quantitative assessments. Our proposed LLM based pipeline provides a practical solution for large-scale IHC-tumour profile data mining, enhancing the accessibility and utility of such data for research and clinical applications as well as enabling the generation of quantitative and structured data to support cancer-specific knowledge base development. Models and training datasets are available at https://github.com/knowlab/IHC-LLMiner.
Exploring Multimodal Large Language Models for Radiology Report Error-checking
Dec 20, 2023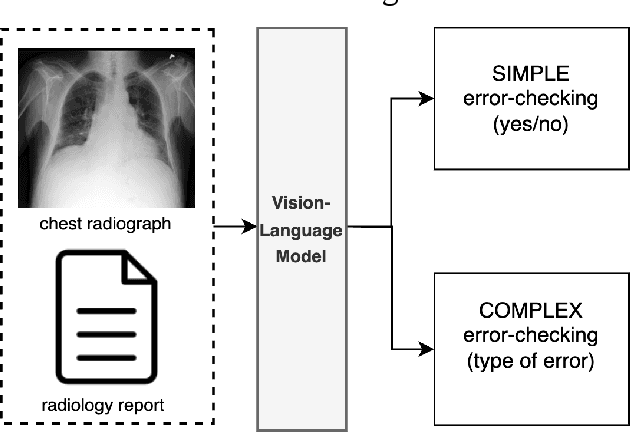


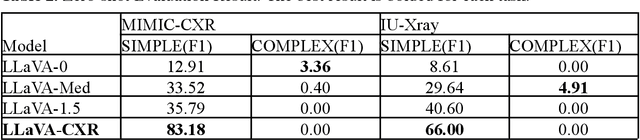
This paper proposes one of the first clinical applications of multimodal large language models (LLMs) as an assistant for radiologists to check errors in their reports. We created an evaluation dataset from two real-world radiology datasets (MIMIC-CXR and IU-Xray), with 1,000 subsampled reports each. A subset of original reports was modified to contain synthetic errors by introducing various type of mistakes. The evaluation contained two difficulty levels: SIMPLE for binary error-checking and COMPLEX for identifying error types. LLaVA (Large Language and Visual Assistant) variant models, including our instruction-tuned model, were used for the evaluation. Additionally, a domain expert evaluation was conducted on a small test set. At the SIMPLE level, the LLaVA v1.5 model outperformed other publicly available models. Instruction tuning significantly enhanced performance by 47.4% and 25.4% on MIMIC-CXR and IU-Xray data, respectively. The model also surpassed the domain experts accuracy in the MIMIC-CXR dataset by 1.67%. Notably, among the subsets (N=21) of the test set where a clinician did not achieve the correct conclusion, the LLaVA ensemble mode correctly identified 71.4% of these cases. This study marks a promising step toward utilizing multi-modal LLMs to enhance diagnostic accuracy in radiology. The ensemble model demonstrated comparable performance to clinicians, even capturing errors overlooked by humans. Nevertheless, future work is needed to improve the model ability to identify the types of inconsistency.