 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkin Cancer Machine Learning Model Tone Bias
Oct 08, 2024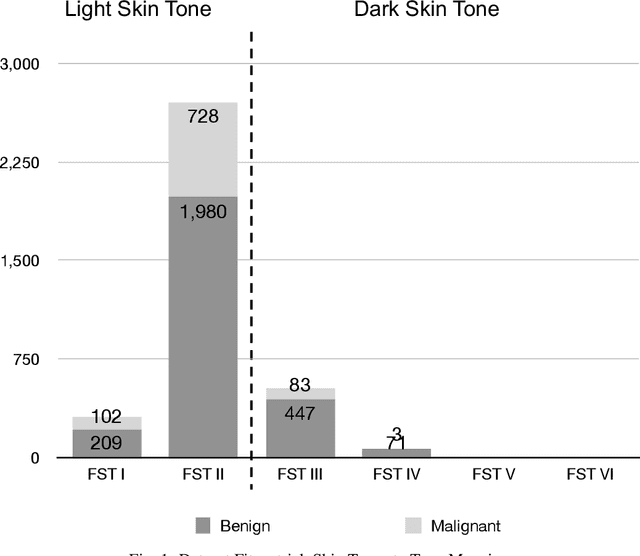
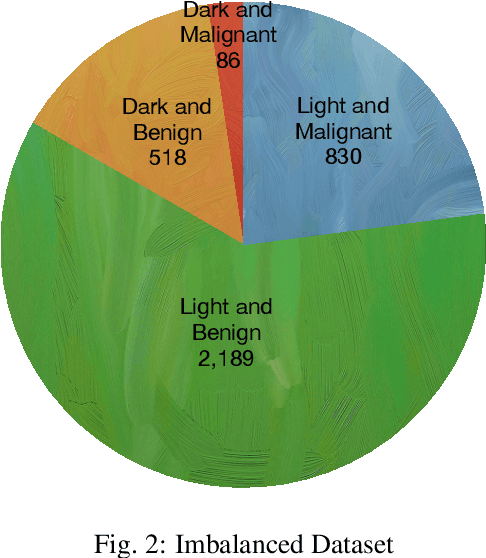

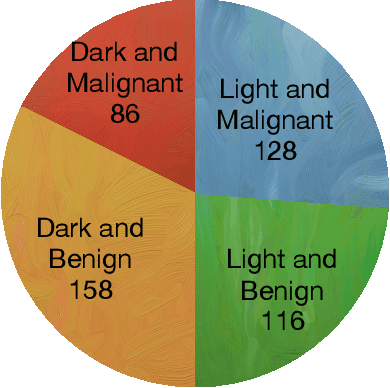
Background: Many open-source skin cancer image datasets are the result of clinical trials conducted in countries with lighter skin tones. Due to this tone imbalance, machine learning models derived from these datasets can perform well at detecting skin cancer for lighter skin tones. Any tone bias in these models could introduce fairness concerns and reduce public trust in the artificial intelligence health field. Methods: We examine a subset of images from the International Skin Imaging Collaboration (ISIC) archive that provide tone information. The subset has a significant tone imbalance. These imbalances could explain a model's tone bias. To address this, we train models using the imbalanced dataset and a balanced dataset to compare against. The datasets are used to train a deep convolutional neural network model to classify the images as malignant or benign. We then evaluate the models' disparate impact, based on selection rate, relative to dark or light skin tone. Results: Using the imbalanced dataset, we found that the model is significantly better at detecting malignant images in lighter tone resulting in a disparate impact of 0.577. Using the balanced dataset, we found that the model is also significantly better at detecting malignant images in lighter versus darker tones with a disparate impact of 0.684. Using the imbalanced or balanced dataset to train the model still results in a disparate impact well below the standard threshold of 0.80 which suggests the model is biased with respect to skin tone. Conclusion: The results show that typical skin cancer machine learning models can be tone biased. These results provide evidence that diagnosis or tone imbalance is not the cause of the bias. Other techniques will be necessary to identify and address the bias in these models, an area of future investigation.
Content Rating Classification for Fan Fiction
Dec 23, 2022



Content ratings can enable audiences to determine the suitability of various media products. With the recent advent of fan fiction, the critical issue of fan fiction content ratings has emerged. Whether fan fiction content ratings are done voluntarily or required by regulation, there is the need to automate the content rating classification. The problem is to take fan fiction text and determine the appropriate content rating. Methods for other domains, such as online books, have been attempted though none have been applied to fan fiction. We propose natural language processing techniques, including traditional and deep learning methods, to automatically determine the content rating. We show that these methods produce poor accuracy results for multi-classification. We then demonstrate that treating the problem as a binary classification problem produces better accuracy. Finally, we believe and provide some evidence that the current approach of self-annotating has led to incorrect labels limiting classification results.
LE3D: A Lightweight Ensemble Framework of Data Drift Detectors for Resource-Constrained Devices
Nov 18, 2022



Data integrity becomes paramount as the number of Internet of Things (IoT) sensor deployments increases. Sensor data can be altered by benign causes or malicious actions. Mechanisms that detect drifts and irregularities can prevent disruptions and data bias in the state of an IoT application. This paper presents LE3D, an ensemble framework of data drift estimators capable of detecting abnormal sensor behaviours. Working collaboratively with surrounding IoT devices, the type of drift (natural/abnormal) can also be identified and reported to the end-user. The proposed framework is a lightweight and unsupervised implementation able to run on resource-constrained IoT devices. Our framework is also generalisable, adapting to new sensor streams and environments with minimal online reconfiguration. We compare our method against state-of-the-art ensemble data drift detection frameworks, evaluating both the real-world detection accuracy as well as the resource utilisation of the implementation. Experimenting with real-world data and emulated drifts, we show the effectiveness of our method, which achieves up to 97% of detection accuracy while requiring minimal resources to run.
Online Heart Rate Prediction using Acceleration from a Wrist Worn Wearable
Jun 25, 2018



In this paper we study the prediction of heart rate from acceleration using a wrist worn wearable. Although existing photoplethysmography (PPG) heart rate sensors provide reliable measurements, they use considerably more energy than accelerometers and have a major impact on battery life of wearable devices. By using energy-efficient accelerometers to predict heart rate, significant energy savings can be made. Further, we are interested in understanding patient recovery after a heart rate intervention, where we expect a variation in heart rate over time. Therefore, we propose an online approach to tackle the concept as time passes. We evaluate the methods on approximately 4 weeks of free living data from three patients over a number of months. We show that our approach can achieve good predictive performance (e.g., 2.89 Mean Absolute Error) while using the PPG heart rate sensor infrequently (e.g., 20.25% of the samples).