 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvably Robust Model-Centric Explanations for Critical Decision-Making
Oct 26, 2021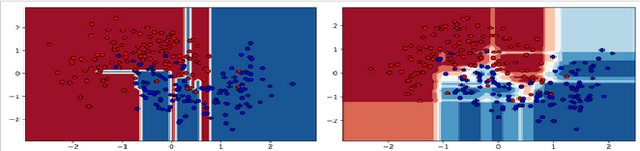


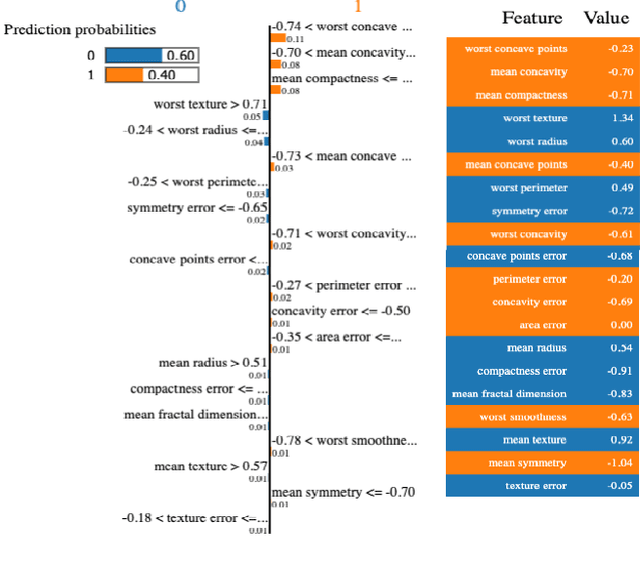
We recommend using a model-centric, Boolean Satisfiability (SAT) formalism to obtain useful explanations of trained model behavior, different and complementary to what can be gleaned from LIME and SHAP, popular data-centric explanation tools in Artificial Intelligence (AI). We compare and contrast these methods, and show that data-centric methods may yield brittle explanations of limited practical utility. The model-centric framework, however, can offer actionable insights into risks of using AI models in practice. For critical applications of AI, split-second decision making is best informed by robust explanations that are invariant to properties of data, the capability offered by model-centric frameworks.
Scaling Active Search using Linear Similarity Functions
Aug 22, 2017
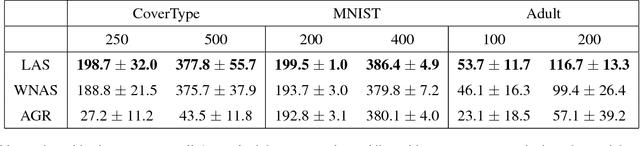
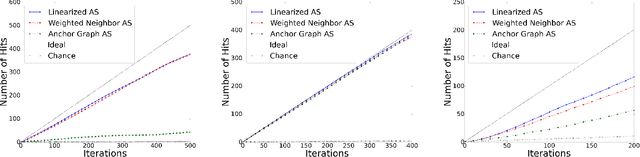
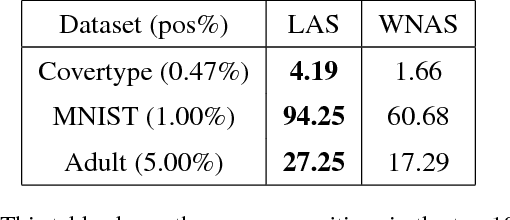
Active Search has become an increasingly useful tool in information retrieval problems where the goal is to discover as many target elements as possible using only limited label queries. With the advent of big data, there is a growing emphasis on the scalability of such techniques to handle very large and very complex datasets. In this paper, we consider the problem of Active Search where we are given a similarity function between data points. We look at an algorithm introduced by Wang et al. [2013] for Active Search over graphs and propose crucial modifications which allow it to scale significantly. Their approach selects points by minimizing an energy function over the graph induced by the similarity function on the data. Our modifications require the similarity function to be a dot-product between feature vectors of data points, equivalent to having a linear kernel for the adjacency matrix. With this, we are able to scale tremendously: for $n$ data points, the original algorithm runs in $O(n^2)$ time per iteration while ours runs in only $O(nr + r^2)$ given $r$-dimensional features. We also describe a simple alternate approach using a weighted-neighbor predictor which also scales well. In our experiments, we show that our method is competitive with existing semi-supervised approaches. We also briefly discuss conditions under which our algorithm performs well.