Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvably Robust Model-Centric Explanations for Critical Decision-Making
Paper and Code
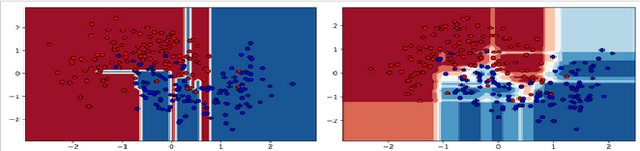


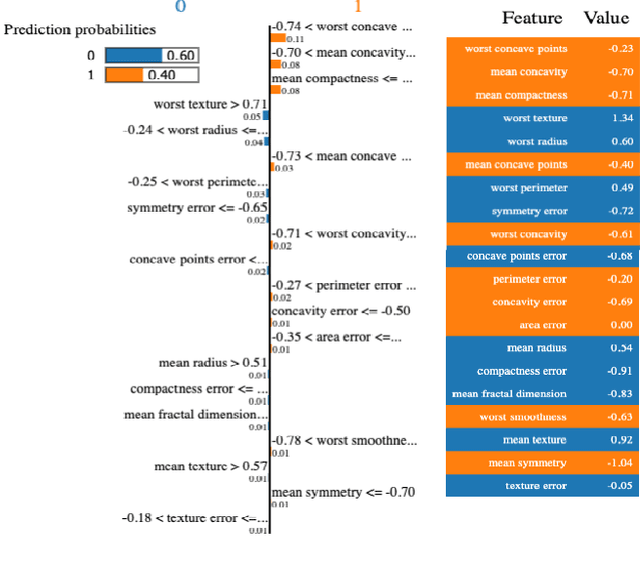
We recommend using a model-centric, Boolean Satisfiability (SAT) formalism to obtain useful explanations of trained model behavior, different and complementary to what can be gleaned from LIME and SHAP, popular data-centric explanation tools in Artificial Intelligence (AI). We compare and contrast these methods, and show that data-centric methods may yield brittle explanations of limited practical utility. The model-centric framework, however, can offer actionable insights into risks of using AI models in practice. For critical applications of AI, split-second decision making is best informed by robust explanations that are invariant to properties of data, the capability offered by model-centric frameworks.
* 8 pages, 9 figures
View paper on