 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn Their Own Words: Reasoning Traces Tailored for Small Models Make Them Better Reasoners
Sep 26, 2025Transferring reasoning capabilities from larger language models to smaller ones through supervised fine-tuning often fails counterintuitively, with performance degrading despite access to high-quality teacher demonstrations. We identify that this failure stems from distributional misalignment: reasoning traces from larger models contain tokens that are low probability under the student's distribution, exceeding the internal representation capacity of smaller architectures and creating learning barriers rather than helpful guidance. We propose Reverse Speculative Decoding (RSD), a mechanism for generating student-friendly reasoning traces in which the teacher model proposes candidate tokens but the student model determines acceptance based on its own probability distributions, filtering low probability tokens. When applied to Qwen3-0.6B, direct distillation of s1K-1.1 reasoning trace data degrades average performance across major reasoning benchmarks by 20.5\%, while the same model trained on RSD-generated reasoning traces achieves meaningful improvements of 4.9\%. Our analysis reveals that low probability tokens constitute the critical bottleneck in reasoning ability transfer. However, cross-model experiments demonstrate that RSD traces are model-specific rather than universally applicable, indicating that distributional alignment must be tailored for each student architecture's unique internal representation.
Label-aware Hard Negative Sampling Strategies with Momentum Contrastive Learning for Implicit Hate Speech Detection
Jun 12, 2024Detecting implicit hate speech that is not directly hateful remains a challenge. Recent research has attempted to detect implicit hate speech by applying contrastive learning to pre-trained language models such as BERT and RoBERTa, but the proposed models still do not have a significant advantage over cross-entropy loss-based learning. We found that contrastive learning based on randomly sampled batch data does not encourage the model to learn hard negative samples. In this work, we propose Label-aware Hard Negative sampling strategies (LAHN) that encourage the model to learn detailed features from hard negative samples, instead of naive negative samples in random batch, using momentum-integrated contrastive learning. LAHN outperforms the existing models for implicit hate speech detection both in- and cross-datasets. The code is available at https://github.com/Hanyang-HCC-Lab/LAHN
HearHere: Mitigating Echo Chambers in News Consumption through an AI-based Web System
Feb 29, 2024Considerable efforts are currently underway to mitigate the negative impacts of echo chambers, such as increased susceptibility to fake news and resistance towards accepting scientific evidence. Prior research has presented the development of computer systems that support the consumption of news information from diverse political perspectives to mitigate the echo chamber effect. However, existing studies still lack the ability to effectively support the key processes of news information consumption and quantitatively identify a political stance towards the information. In this paper, we present HearHere, an AI-based web system designed to help users accommodate information and opinions from diverse perspectives. HearHere facilitates the key processes of news information consumption through two visualizations. Visualization 1 provides political news with quantitative political stance information, derived from our graph-based political classification model, and users can experience diverse perspectives (Hear). Visualization 2 allows users to express their opinions on specific political issues in a comment form and observe the position of their own opinions relative to pro-liberal and pro-conservative comments presented on a map interface (Here). Through a user study with 94 participants, we demonstrate the feasibility of HearHere in supporting the consumption of information from various perspectives. Our findings highlight the importance of providing political stance information and quantifying users' political status as a means to mitigate political polarization. In addition, we propose design implications for system development, including the consideration of demographics such as political interest and providing users with initiatives.
Solvent: A Framework for Protein Folding
Jul 31, 2023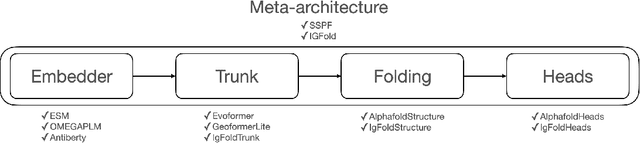

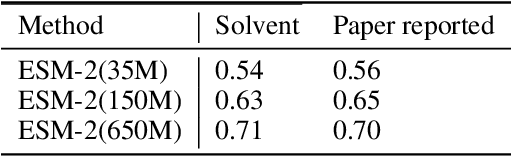
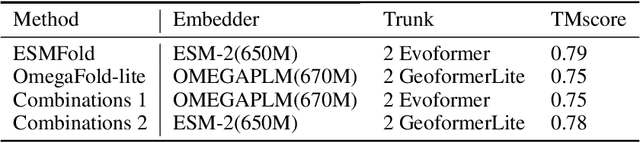
Consistency and reliability are crucial for conducting AI research. Many famous research fields, such as object detection, have been compared and validated with solid benchmark frameworks. After AlphaFold2, the protein folding task has entered a new phase, and many methods are proposed based on the component of AlphaFold2. The importance of a unified research framework in protein folding contains implementations and benchmarks to consistently and fairly compare various approaches. To achieve this, we present Solvent, a protein folding framework that supports significant components of state-of-the-art models in the manner of an off-the-shelf interface Solvent contains different models implemented in a unified codebase and supports training and evaluation for defined models on the same dataset. We benchmark well-known algorithms and their components and provide experiments that give helpful insights into the protein structure modeling field. We hope that Solvent will increase the reliability and consistency of proposed models and give efficiency in both speed and costs, resulting in acceleration on protein folding modeling research. The code is available at https://github.com/kakaobrain/solvent, and the project will continue to be developed.
KHAN: Knowledge-Aware Hierarchical Attention Networks for Accurate Political Stance Prediction
Mar 01, 2023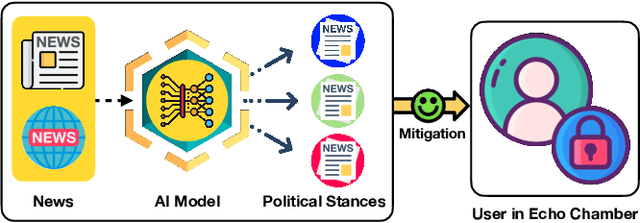



The political stance prediction for news articles has been widely studied to mitigate the echo chamber effect -- people fall into their thoughts and reinforce their pre-existing beliefs. The previous works for the political stance problem focus on (1) identifying political factors that could reflect the political stance of a news article and (2) capturing those factors effectively. Despite their empirical successes, they are not sufficiently justified in terms of how effective their identified factors are in the political stance prediction. Motivated by this, in this work, we conduct a user study to investigate important factors in political stance prediction, and observe that the context and tone of a news article (implicit) and external knowledge for real-world entities appearing in the article (explicit) are important in determining its political stance. Based on this observation, we propose a novel knowledge-aware approach to political stance prediction (KHAN), employing (1) hierarchical attention networks (HAN) to learn the relationships among words and sentences in three different levels and (2) knowledge encoding (KE) to incorporate external knowledge for real-world entities into the process of political stance prediction. Also, to take into account the subtle and important difference between opposite political stances, we build two independent political knowledge graphs (KG) (i.e., KG-lib and KG-con) by ourselves and learn to fuse the different political knowledge. Through extensive evaluations on three real-world datasets, we demonstrate the superiority of DASH in terms of (1) accuracy, (2) efficiency, and (3) effectiveness.
Catalyst design using actively learned machine with non-ab initio input features towards CO2 reduction reactions
Sep 14, 2017
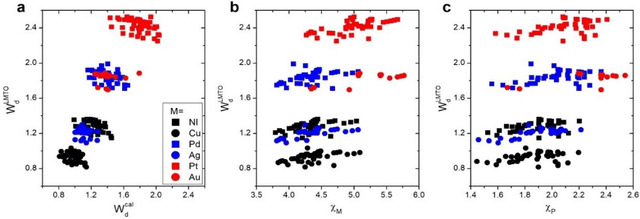
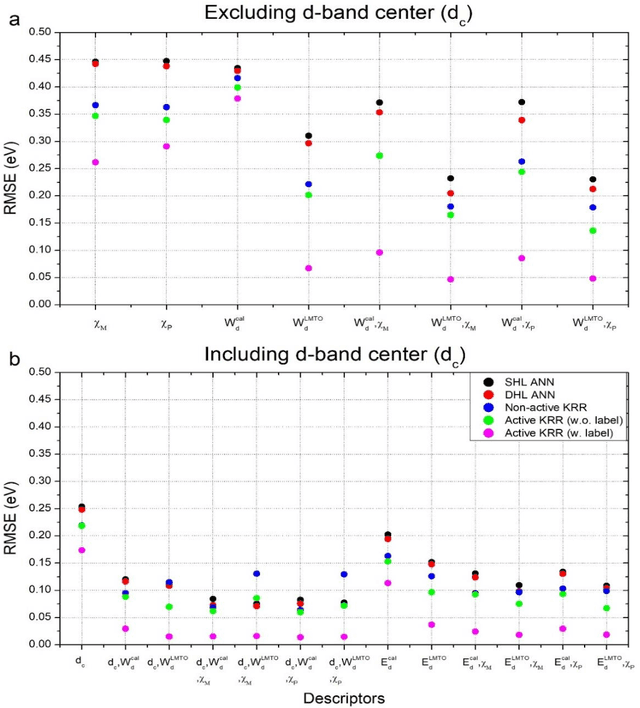
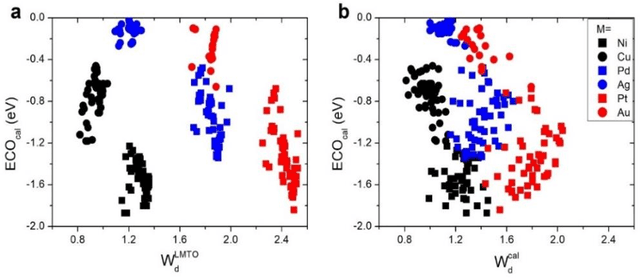
In conventional chemisorption model, the d-band center theory (augmented sometimes with the upper edge of d-band for imporved accuarcy) plays a central role in predicting adsorption energies and catalytic activity as a function of d-band center of the solid surfaces, but it requires density functional calculations that can be quite costly for large scale screening purposes of materials. In this work, we propose to use the d-band width of the muffin-tin orbital theory (to account for local coordination environment) plus electronegativity (to account for adsorbate renormalization) as a simple set of alternative descriptors for chemisorption, which do not demand the ab initio calculations. This pair of descriptors are then combined with machine learning methods, namely, artificial neural network (ANN) and kernel ridge regression (KRR), to allow large scale materials screenings. We show, for a toy set of 263 alloy systems, that the CO adsorption energy can be predicted with a remarkably small mean absolute deviation error of 0.05 eV, a significantly improved result as compared to 0.13 eV obtained with descriptors including costly d-band center calculations in literature. We achieved this high accuracy by utilizing an active learning algorithm, without which the accuracy was 0.18 eV otherwise. As a practical application of this machine, we identified Cu3Y@Cu as a highly active and cost-effective electrochemical CO2 reduction catalyst to produce CO with the overpotential 0.37 V lower than Au catalyst.