 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Language Model for Catalyst Discovery
Jul 19, 2024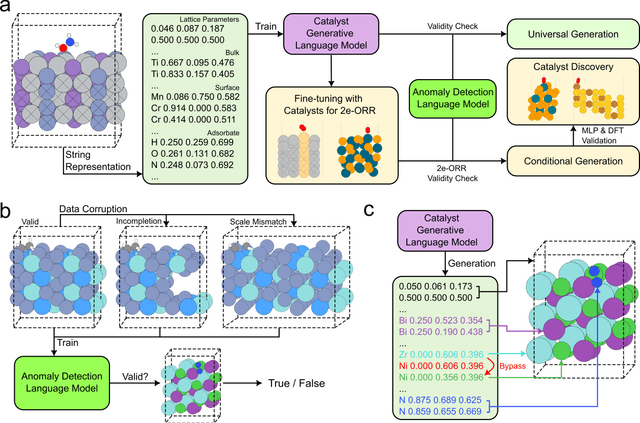


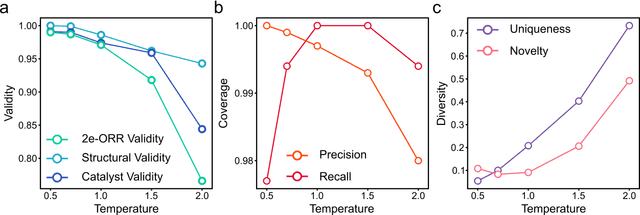
Discovery of novel and promising materials is a critical challenge in the field of chemistry and material science, traditionally approached through methodologies ranging from trial-and-error to machine learning-driven inverse design. Recent studies suggest that transformer-based language models can be utilized as material generative models to expand chemical space and explore materials with desired properties. In this work, we introduce the Catalyst Generative Pretrained Transformer (CatGPT), trained to generate string representations of inorganic catalyst structures from a vast chemical space. CatGPT not only demonstrates high performance in generating valid and accurate catalyst structures but also serves as a foundation model for generating desired types of catalysts by fine-tuning with sparse and specified datasets. As an example, we fine-tuned the pretrained CatGPT using a binary alloy catalyst dataset designed for screening two-electron oxygen reduction reaction (2e-ORR) catalyst and generate catalyst structures specialized for 2e-ORR. Our work demonstrates the potential of language models as generative tools for catalyst discovery.
Catalyst design using actively learned machine with non-ab initio input features towards CO2 reduction reactions
Sep 14, 2017
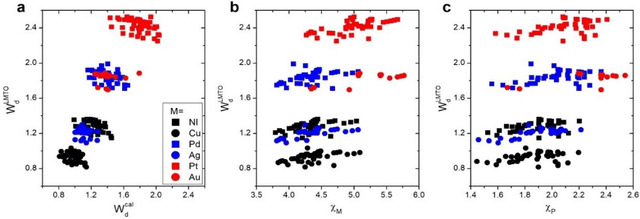
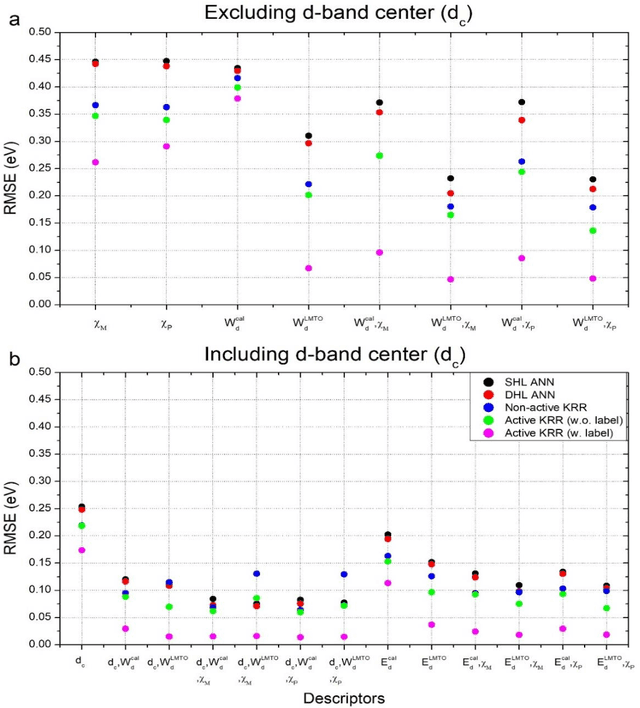
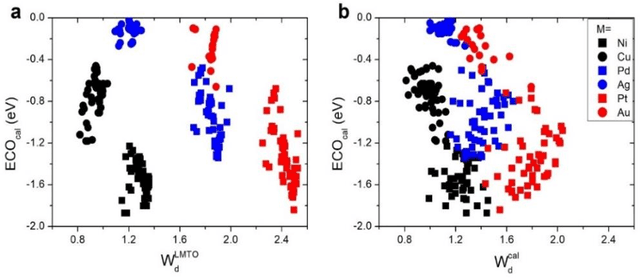
In conventional chemisorption model, the d-band center theory (augmented sometimes with the upper edge of d-band for imporved accuarcy) plays a central role in predicting adsorption energies and catalytic activity as a function of d-band center of the solid surfaces, but it requires density functional calculations that can be quite costly for large scale screening purposes of materials. In this work, we propose to use the d-band width of the muffin-tin orbital theory (to account for local coordination environment) plus electronegativity (to account for adsorbate renormalization) as a simple set of alternative descriptors for chemisorption, which do not demand the ab initio calculations. This pair of descriptors are then combined with machine learning methods, namely, artificial neural network (ANN) and kernel ridge regression (KRR), to allow large scale materials screenings. We show, for a toy set of 263 alloy systems, that the CO adsorption energy can be predicted with a remarkably small mean absolute deviation error of 0.05 eV, a significantly improved result as compared to 0.13 eV obtained with descriptors including costly d-band center calculations in literature. We achieved this high accuracy by utilizing an active learning algorithm, without which the accuracy was 0.18 eV otherwise. As a practical application of this machine, we identified Cu3Y@Cu as a highly active and cost-effective electrochemical CO2 reduction catalyst to produce CO with the overpotential 0.37 V lower than Au catalyst.