 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounting Circuits: Mechanistic Interpretability of Visual Reasoning in Large Vision-Language Models
Mar 19, 2026Counting serves as a simple but powerful test of a Large Vision-Language Model's (LVLM's) reasoning; it forces the model to identify each individual object and then add them all up. In this study, we investigate how LVLMs implement counting using controlled synthetic and real-world benchmarks, combined with mechanistic analyses. Our results show that LVLMs display a human-like counting behavior, with precise performance on small numerosities and noisy estimation for larger quantities. We introduce two novel interpretability methods, Visual Activation Patching and HeadLens, and use them to uncover a structured "counting circuit" that is largely shared across a variety of visual reasoning tasks. Building on these insights, we propose a lightweight intervention strategy that exploits simple and abundantly available synthetic images to fine-tune arbitrary pretrained LVLMs exclusively on counting. Despite the narrow scope of this fine-tuning, the intervention not only enhances counting accuracy on in-distribution synthetic data, but also yields an average improvement of +8.36% on out-of-distribution counting benchmarks and an average gain of +1.54% on complex, general visual reasoning tasks for Qwen2.5-VL. These findings highlight the central, influential role of counting in visual reasoning and suggest a potential pathway for improving overall visual reasoning capabilities through targeted enhancement of counting mechanisms.
Reasoning or Simply Next Token Prediction? A Benchmark for Stress-Testing Large Language Models
Jun 15, 2024We propose MMLU-SR, a novel dataset designed to measure the true comprehension abilities of Large Language Models (LLMs) by challenging their performance in question-answering tasks with modified terms. We reasoned that an agent that ``truly'' understands a concept can still evaluate it when key terms are replaced by suitably defined alternate terms, and sought to differentiate such comprehension from mere text replacement. In our study, we modified standardized test questions by replacing a key term with a dummy word along with its definition. The key term could be in the context of questions, answers, or both questions and answers. Notwithstanding the high scores achieved by recent popular LLMs on the MMLU leaderboard, we found a substantial reduction in model performance after such replacement, suggesting poor comprehension. This new benchmark provides a rigorous benchmark for testing true model comprehension, and poses a challenge to the broader scientific community.
Socially Cognizant Robotics for a Technology Enhanced Society
Oct 27, 2023



Emerging applications of robotics, and concerns about their impact, require the research community to put human-centric objectives front-and-center. To meet this challenge, we advocate an interdisciplinary approach, socially cognizant robotics, which synthesizes technical and social science methods. We argue that this approach follows from the need to empower stakeholder participation (from synchronous human feedback to asynchronous societal assessment) in shaping AI-driven robot behavior at all levels, and leads to a range of novel research perspectives and problems both for improving robots' interactions with individuals and impacts on society. Drawing on these arguments, we develop best practices for socially cognizant robot design that balance traditional technology-based metrics (e.g. efficiency, precision and accuracy) with critically important, albeit challenging to measure, human and society-based metrics.
The Role of Typicality in Object Classification: Improving The Generalization Capacity of Convolutional Neural Networks
Feb 09, 2016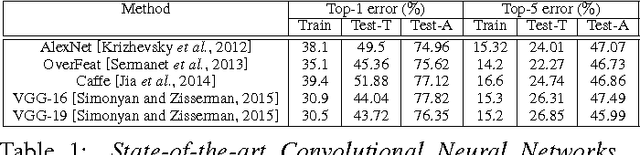


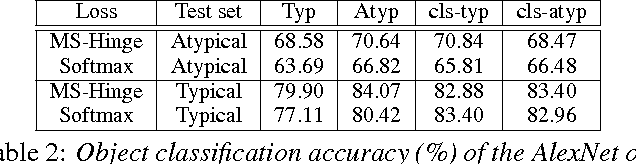
Deep artificial neural networks have made remarkable progress in different tasks in the field of computer vision. However, the empirical analysis of these models and investigation of their failure cases has received attention recently. In this work, we show that deep learning models cannot generalize to atypical images that are substantially different from training images. This is in contrast to the superior generalization ability of the visual system in the human brain. We focus on Convolutional Neural Networks (CNN) as the state-of-the-art models in object recognition and classification; investigate this problem in more detail, and hypothesize that training CNN models suffer from unstructured loss minimization. We propose computational models to improve the generalization capacity of CNNs by considering how typical a training image looks like. By conducting an extensive set of experiments we show that involving a typicality measure can improve the classification results on a new set of images by a large margin. More importantly, this significant improvement is achieved without fine-tuning the CNN model on the target image set.
Toward a Taxonomy and Computational Models of Abnormalities in Images
Dec 04, 2015
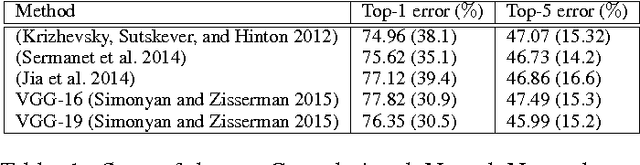


The human visual system can spot an abnormal image, and reason about what makes it strange. This task has not received enough attention in computer vision. In this paper we study various types of atypicalities in images in a more comprehensive way than has been done before. We propose a new dataset of abnormal images showing a wide range of atypicalities. We design human subject experiments to discover a coarse taxonomy of the reasons for abnormality. Our experiments reveal three major categories of abnormality: object-centric, scene-centric, and contextual. Based on this taxonomy, we propose a comprehensive computational model that can predict all different types of abnormality in images and outperform prior arts in abnormality recognition.