 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWrite a Classifier: Predicting Visual Classifiers from Unstructured Text
Dec 28, 2016
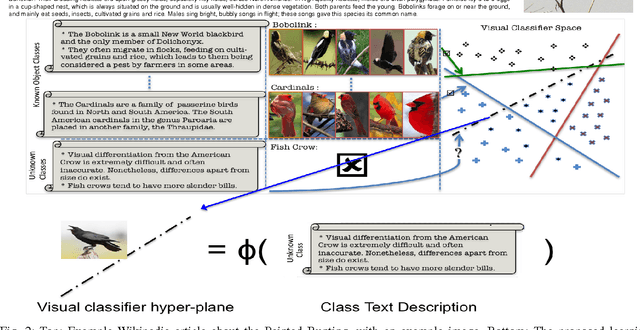
People typically learn through exposure to visual concepts associated with linguistic descriptions. For instance, teaching visual object categories to children is often accompanied by descriptions in text or speech. In a machine learning context, these observations motivates us to ask whether this learning process could be computationally modeled to learn visual classifiers. More specifically, the main question of this work is how to utilize purely textual description of visual classes with no training images, to learn explicit visual classifiers for them. We propose and investigate two baseline formulations, based on regression and domain transfer, that predict a linear classifier. Then, we propose a new constrained optimization formulation that combines a regression function and a knowledge transfer function with additional constraints to predict the parameters of a linear classifier. We also propose a generic kernelized models where a kernel classifier is predicted in the form defined by the representer theorem. The kernelized models allow defining and utilizing any two RKHS (Reproducing Kernel Hilbert Space) kernel functions in the visual space and text space, respectively. We finally propose a kernel function between unstructured text descriptions that builds on distributional semantics, which shows an advantage in our setting and could be useful for other applications. We applied all the studied models to predict visual classifiers on two fine-grained and challenging categorization datasets (CU Birds and Flower Datasets), and the results indicate successful predictions of our final model over several baselines that we designed.
The Role of Typicality in Object Classification: Improving The Generalization Capacity of Convolutional Neural Networks
Feb 09, 2016


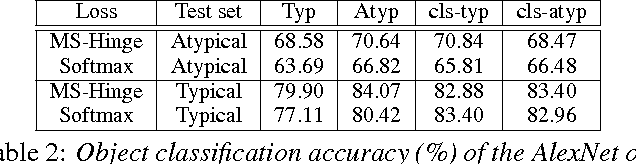
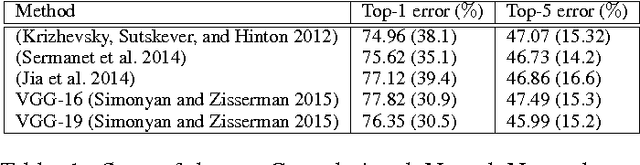
Deep artificial neural networks have made remarkable progress in different tasks in the field of computer vision. However, the empirical analysis of these models and investigation of their failure cases has received attention recently. In this work, we show that deep learning models cannot generalize to atypical images that are substantially different from training images. This is in contrast to the superior generalization ability of the visual system in the human brain. We focus on Convolutional Neural Networks (CNN) as the state-of-the-art models in object recognition and classification; investigate this problem in more detail, and hypothesize that training CNN models suffer from unstructured loss minimization. We propose computational models to improve the generalization capacity of CNNs by considering how typical a training image looks like. By conducting an extensive set of experiments we show that involving a typicality measure can improve the classification results on a new set of images by a large margin. More importantly, this significant improvement is achieved without fine-tuning the CNN model on the target image set.
Toward a Taxonomy and Computational Models of Abnormalities in Images
Dec 04, 2015


The human visual system can spot an abnormal image, and reason about what makes it strange. This task has not received enough attention in computer vision. In this paper we study various types of atypicalities in images in a more comprehensive way than has been done before. We propose a new dataset of abnormal images showing a wide range of atypicalities. We design human subject experiments to discover a coarse taxonomy of the reasons for abnormality. Our experiments reveal three major categories of abnormality: object-centric, scene-centric, and contextual. Based on this taxonomy, we propose a comprehensive computational model that can predict all different types of abnormality in images and outperform prior arts in abnormality recognition.
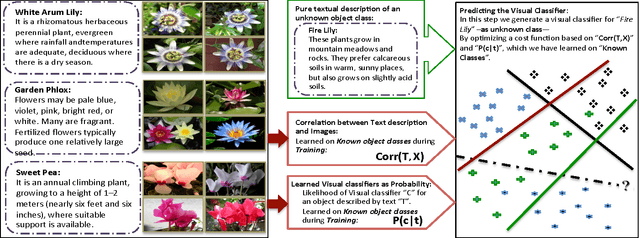
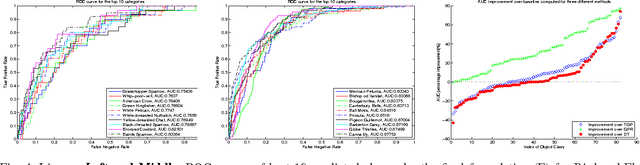
Tell and Predict: Kernel Classifier Prediction for Unseen Visual Classes from Unstructured Text Descriptions
Jun 29, 2015
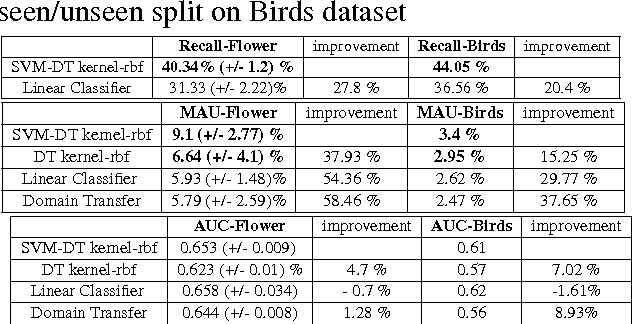
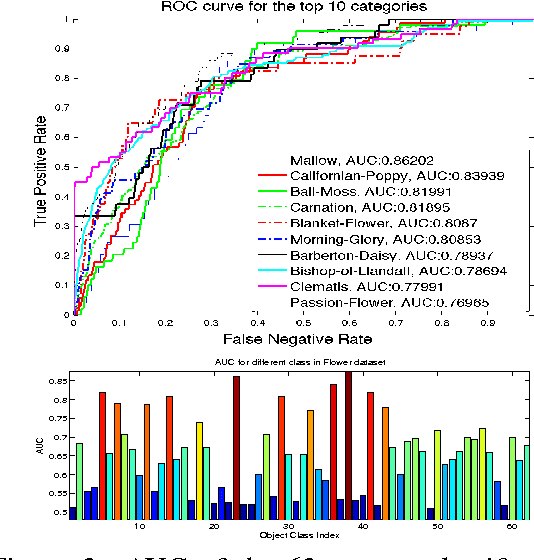

In this paper we propose a framework for predicting kernelized classifiers in the visual domain for categories with no training images where the knowledge comes from textual description about these categories. Through our optimization framework, the proposed approach is capable of embedding the class-level knowledge from the text domain as kernel classifiers in the visual domain. We also proposed a distributional semantic kernel between text descriptions which is shown to be effective in our setting. The proposed framework is not restricted to textual descriptions, and can also be applied to other forms knowledge representations. Our approach was applied for the challenging task of zero-shot learning of fine-grained categories from text descriptions of these categories.
Quantifying Creativity in Art Networks
Jun 02, 2015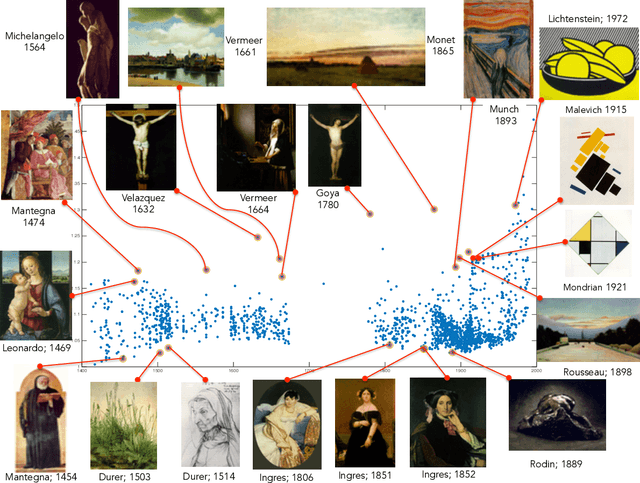
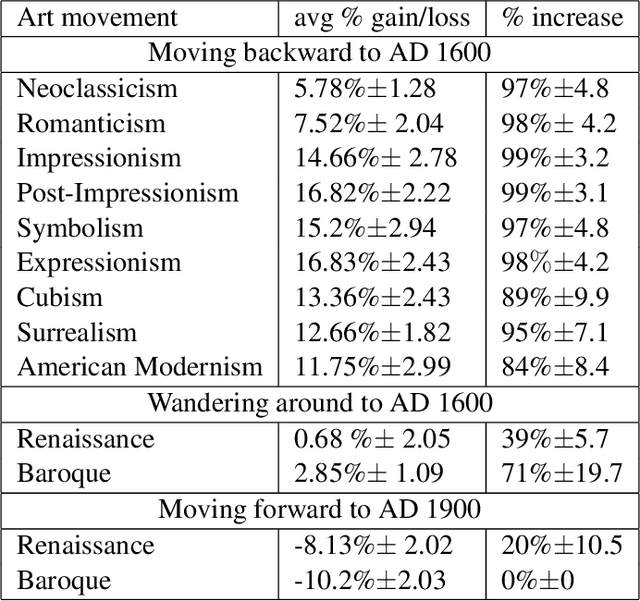
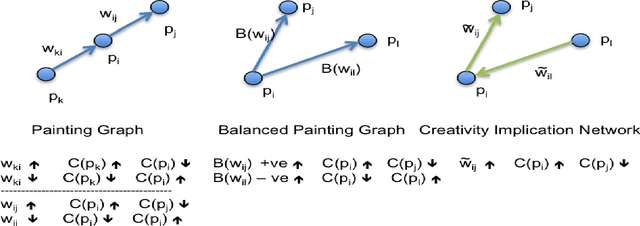
Can we develop a computer algorithm that assesses the creativity of a painting given its context within art history? This paper proposes a novel computational framework for assessing the creativity of creative products, such as paintings, sculptures, poetry, etc. We use the most common definition of creativity, which emphasizes the originality of the product and its influential value. The proposed computational framework is based on constructing a network between creative products and using this network to infer about the originality and influence of its nodes. Through a series of transformations, we construct a Creativity Implication Network. We show that inference about creativity in this network reduces to a variant of network centrality problems which can be solved efficiently. We apply the proposed framework to the task of quantifying creativity of paintings (and sculptures). We experimented on two datasets with over 62K paintings to illustrate the behavior of the proposed framework. We also propose a methodology for quantitatively validating the results of the proposed algorithm, which we call the "time machine experiment".
Learning Style Similarity for Searching Infographics
May 05, 2015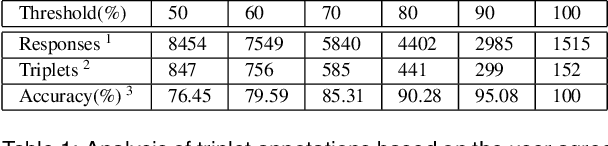

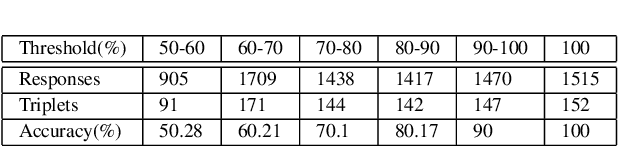
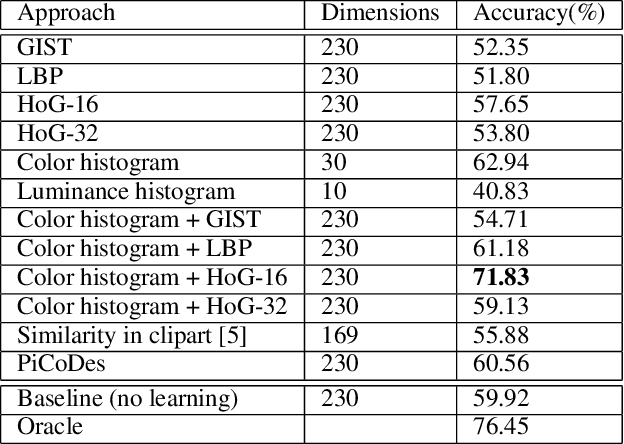
Infographics are complex graphic designs integrating text, images, charts and sketches. Despite the increasing popularity of infographics and the rapid growth of online design portfolios, little research investigates how we can take advantage of these design resources. In this paper we present a method for measuring the style similarity between infographics. Based on human perception data collected from crowdsourced experiments, we use computer vision and machine learning algorithms to learn a style similarity metric for infographic designs. We evaluate different visual features and learning algorithms and find that a combination of color histograms and Histograms-of-Gradients (HoG) features is most effective in characterizing the style of infographics. We demonstrate our similarity metric on a preliminary image retrieval test.
Large-scale Classification of Fine-Art Paintings: Learning The Right Metric on The Right Feature
May 05, 2015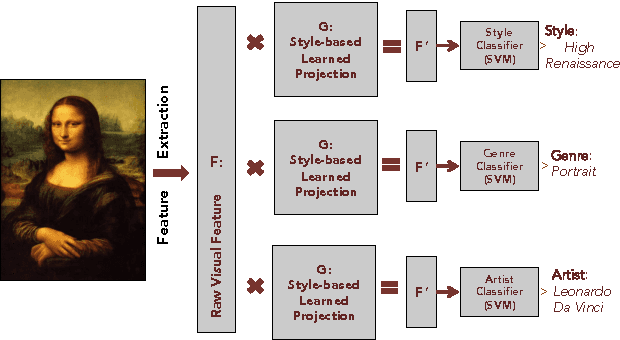
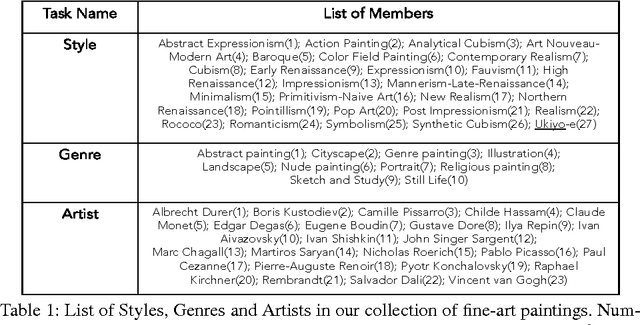
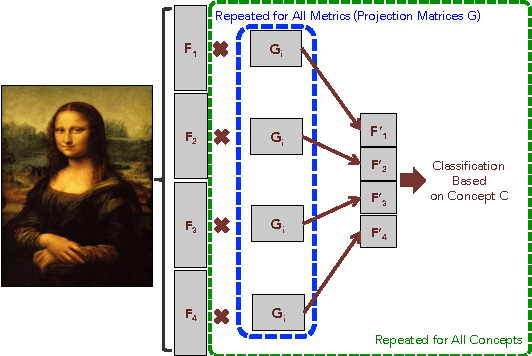
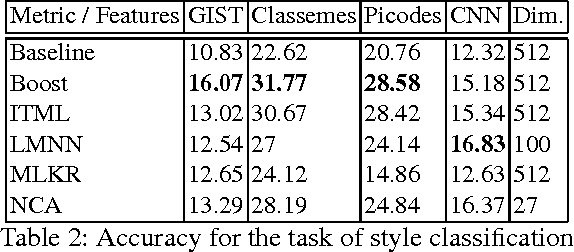
In the past few years, the number of fine-art collections that are digitized and publicly available has been growing rapidly. With the availability of such large collections of digitized artworks comes the need to develop multimedia systems to archive and retrieve this pool of data. Measuring the visual similarity between artistic items is an essential step for such multimedia systems, which can benefit more high-level multimedia tasks. In order to model this similarity between paintings, we should extract the appropriate visual features for paintings and find out the best approach to learn the similarity metric based on these features. We investigate a comprehensive list of visual features and metric learning approaches to learn an optimized similarity measure between paintings. We develop a machine that is able to make aesthetic-related semantic-level judgments, such as predicting a painting's style, genre, and artist, as well as providing similarity measures optimized based on the knowledge available in the domain of art historical interpretation. Our experiments show the value of using this similarity measure for the aforementioned prediction tasks.
Abnormal Object Recognition: A Comprehensive Study
Nov 09, 2014
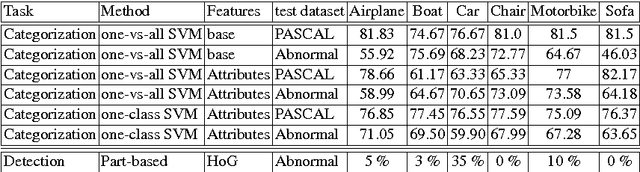

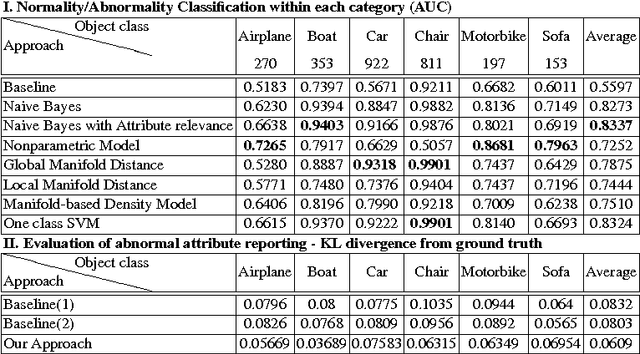
When describing images, humans tend not to talk about the obvious, but rather mention what they find interesting. We argue that abnormalities and deviations from typicalities are among the most important components that form what is worth mentioning. In this paper we introduce the abnormality detection as a recognition problem and show how to model typicalities and, consequently, meaningful deviations from prototypical properties of categories. Our model can recognize abnormalities and report the main reasons of any recognized abnormality. We introduce the abnormality detection dataset and show interesting results on how to reason about abnormalities.
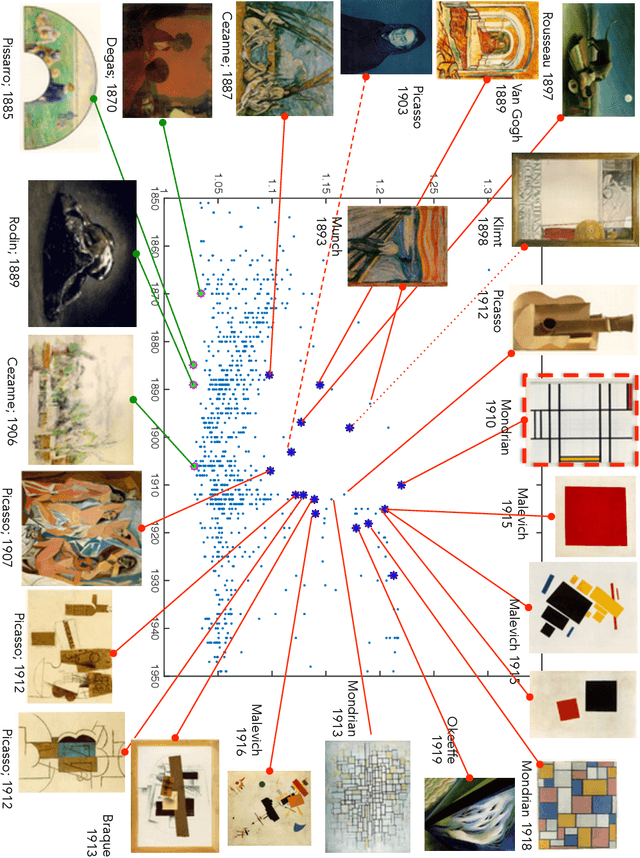
Toward Automated Discovery of Artistic Influence
Aug 14, 2014
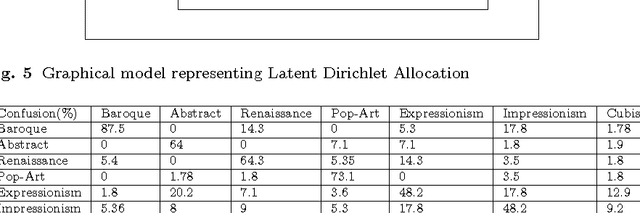

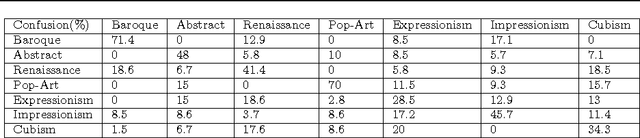
Considering the huge amount of art pieces that exist, there is valuable information to be discovered. Examining a painting, an expert can determine its style, genre, and the time period that the painting belongs. One important task for art historians is to find influences and connections between artists. Is influence a task that a computer can measure? The contribution of this paper is in exploring the problem of computer-automated suggestion of influences between artists, a problem that was not addressed before in a general setting. We first present a comparative study of different classification methodologies for the task of fine-art style classification. A two-level comparative study is performed for this classification problem. The first level reviews the performance of discriminative vs. generative models, while the second level touches the features aspect of the paintings and compares semantic-level features vs. low-level and intermediate-level features present in the painting. Then, we investigate the question "Who influenced this artist?" by looking at his masterpieces and comparing them to others. We pose this interesting question as a knowledge discovery problem. For this purpose, we investigated several painting-similarity and artist-similarity measures. As a result, we provide a visualization of artists (Map of Artists) based on the similarity between their works