 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTell and Predict: Kernel Classifier Prediction for Unseen Visual Classes from Unstructured Text Descriptions
Paper and Code
Jun 29, 2015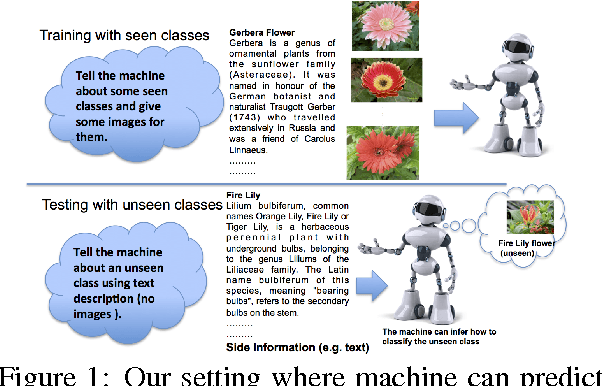
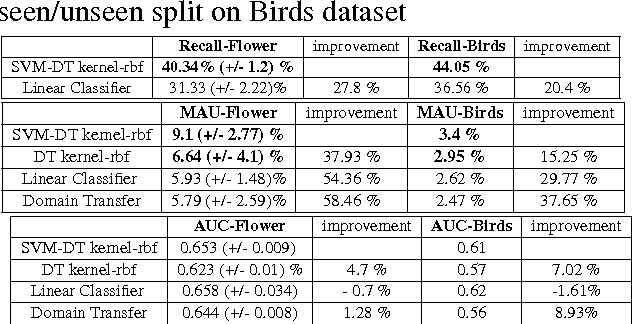
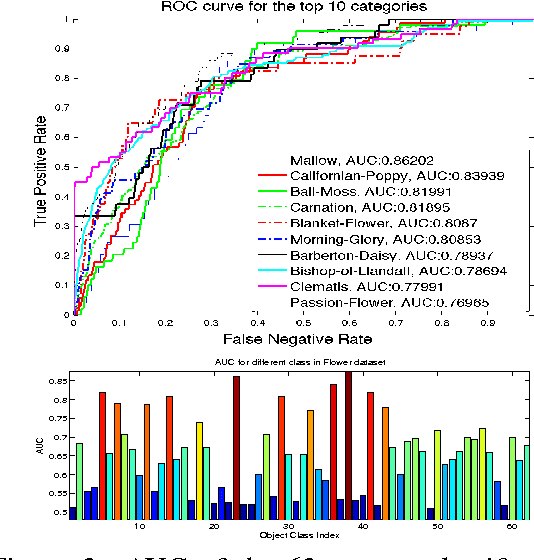

In this paper we propose a framework for predicting kernelized classifiers in the visual domain for categories with no training images where the knowledge comes from textual description about these categories. Through our optimization framework, the proposed approach is capable of embedding the class-level knowledge from the text domain as kernel classifiers in the visual domain. We also proposed a distributional semantic kernel between text descriptions which is shown to be effective in our setting. The proposed framework is not restricted to textual descriptions, and can also be applied to other forms knowledge representations. Our approach was applied for the challenging task of zero-shot learning of fine-grained categories from text descriptions of these categories.