 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWrite a Classifier: Predicting Visual Classifiers from Unstructured Text
Paper and Code
Dec 28, 2016
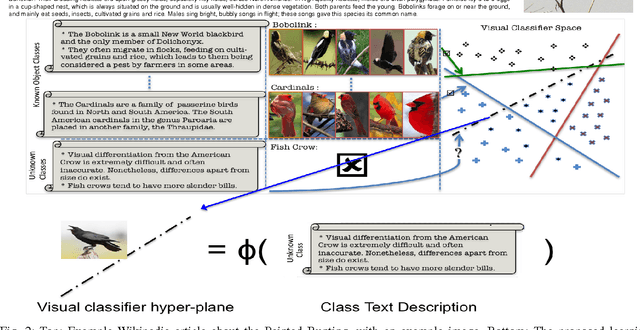
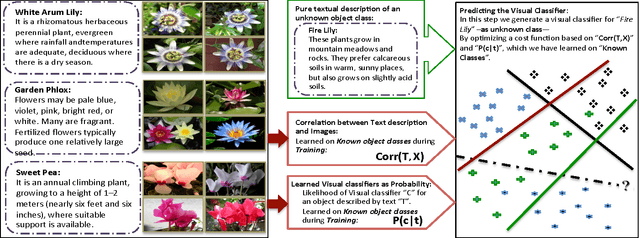
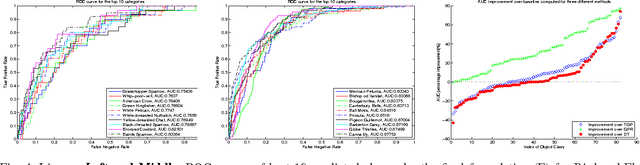
People typically learn through exposure to visual concepts associated with linguistic descriptions. For instance, teaching visual object categories to children is often accompanied by descriptions in text or speech. In a machine learning context, these observations motivates us to ask whether this learning process could be computationally modeled to learn visual classifiers. More specifically, the main question of this work is how to utilize purely textual description of visual classes with no training images, to learn explicit visual classifiers for them. We propose and investigate two baseline formulations, based on regression and domain transfer, that predict a linear classifier. Then, we propose a new constrained optimization formulation that combines a regression function and a knowledge transfer function with additional constraints to predict the parameters of a linear classifier. We also propose a generic kernelized models where a kernel classifier is predicted in the form defined by the representer theorem. The kernelized models allow defining and utilizing any two RKHS (Reproducing Kernel Hilbert Space) kernel functions in the visual space and text space, respectively. We finally propose a kernel function between unstructured text descriptions that builds on distributional semantics, which shows an advantage in our setting and could be useful for other applications. We applied all the studied models to predict visual classifiers on two fine-grained and challenging categorization datasets (CU Birds and Flower Datasets), and the results indicate successful predictions of our final model over several baselines that we designed.