 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe state of the art in kidney and kidney tumor segmentation in contrast-enhanced CT imaging: Results of the KiTS19 Challenge
Dec 02, 2019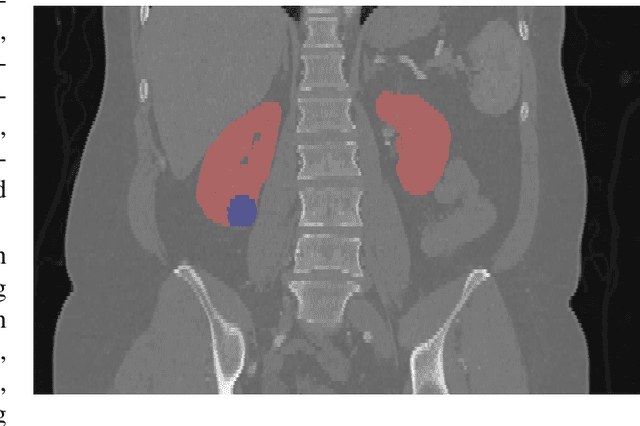
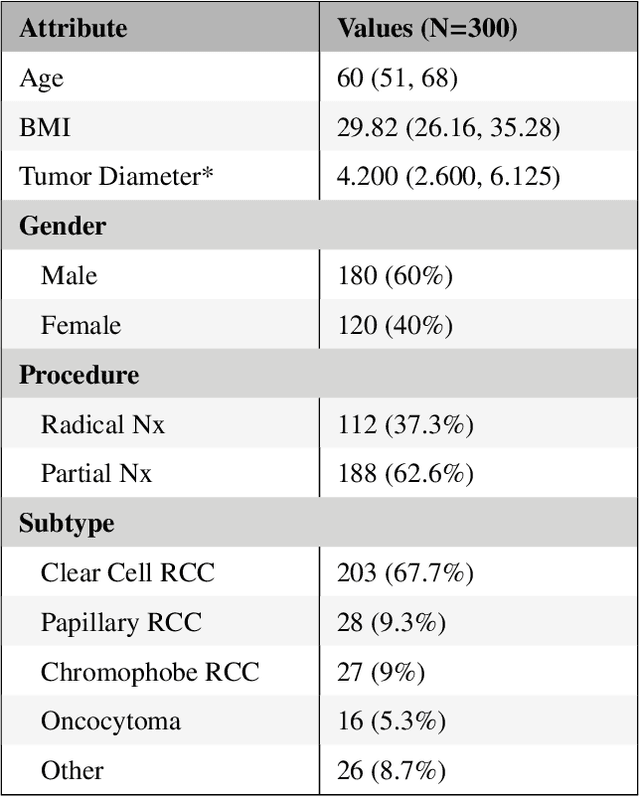
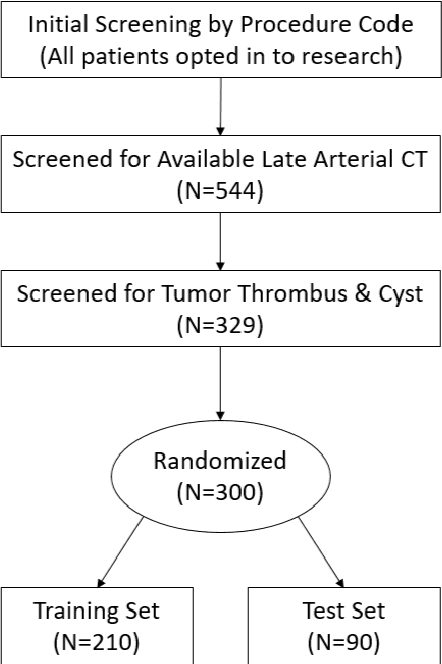
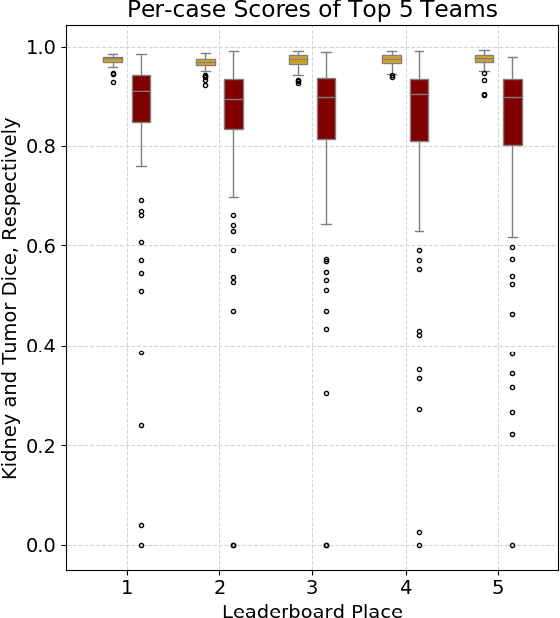
There is a large body of literature linking anatomic and geometric characteristics of kidney tumors to perioperative and oncologic outcomes. Semantic segmentation of these tumors and their host kidneys is a promising tool for quantitatively characterizing these lesions, but its adoption is limited due to the manual effort required to produce high-quality 3D segmentations of these structures. Recently, methods based on deep learning have shown excellent results in automatic 3D segmentation, but they require large datasets for training, and there remains little consensus on which methods perform best. The 2019 Kidney and Kidney Tumor Segmentation challenge (KiTS19) was a competition held in conjunction with the 2019 International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI) which sought to address these issues and stimulate progress on this automatic segmentation problem. A training set of 210 cross sectional CT images with kidney tumors was publicly released with corresponding semantic segmentation masks. 106 teams from five continents used this data to develop automated systems to predict the true segmentation masks on a test set of 90 CT images for which the corresponding ground truth segmentations were kept private. These predictions were scored and ranked according to their average So rensen-Dice coefficient between the kidney and tumor across all 90 cases. The winning team achieved a Dice of 0.974 for kidney and 0.851 for tumor, approaching the inter-annotator performance on kidney (0.983) but falling short on tumor (0.923). This challenge has now entered an "open leaderboard" phase where it serves as a challenging benchmark in 3D semantic segmentation.
The Role of Publicly Available Data in MICCAI Papers from 2014 to 2018
Aug 12, 2019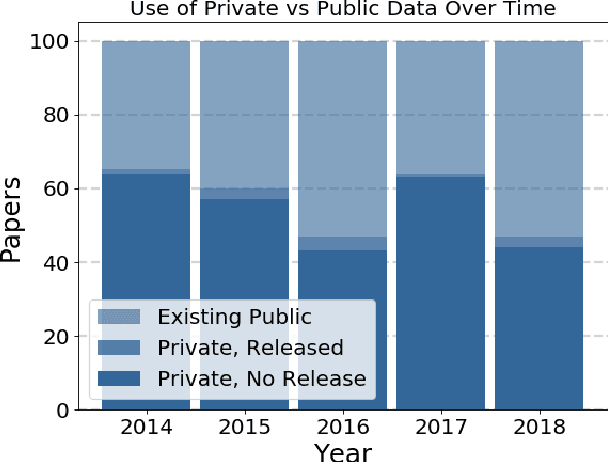
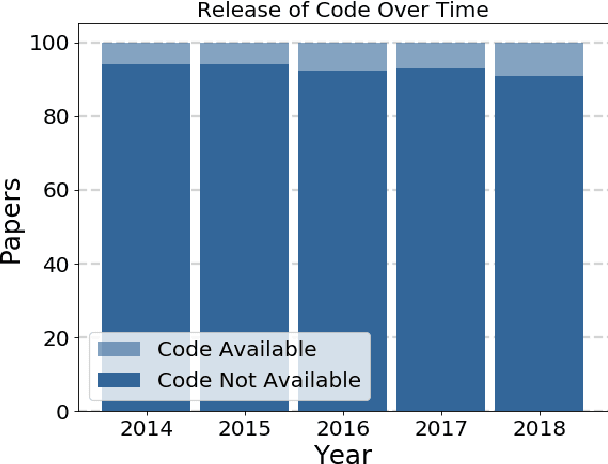
Widely-used public benchmarks are of huge importance to computer vision and machine learning research, especially with the computational resources required to reproduce state of the art results quickly becoming untenable. In medical image computing, the wide variety of image modalities and problem formulations yields a huge task-space for benchmarks to cover, and thus the widespread adoption of standard benchmarks has been slow, and barriers to releasing medical data exacerbate this issue. In this paper, we examine the role that publicly available data has played in MICCAI papers from the past five years. We find that more than half of these papers are based on private data alone, although this proportion seems to be decreasing over time. Additionally, we observed that after controlling for open access publication and the release of code, papers based on public data were cited over 60% more per year than their private-data counterparts. Further, we found that more than 20% of papers using public data did not provide a citation to the dataset or associated manuscript, highlighting the "second-rate" status that data contributions often take compared to theoretical ones. We conclude by making recommendations for MICCAI policies which could help to better incentivise data sharing and move the field toward more efficient and reproducible science.