 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Role of Publicly Available Data in MICCAI Papers from 2014 to 2018
Paper and Code
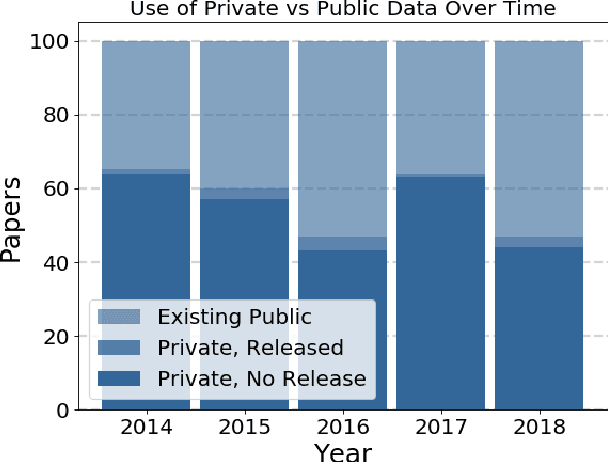
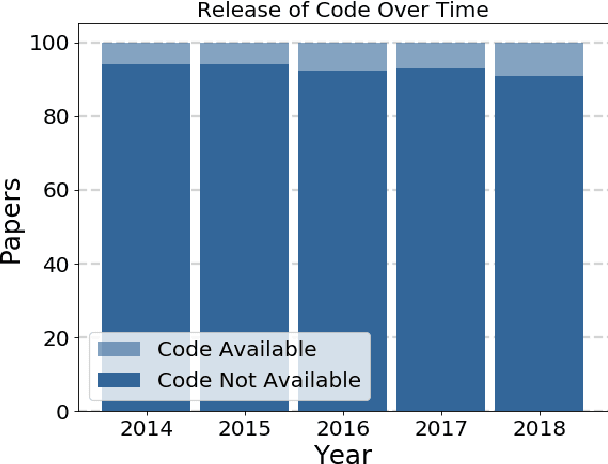
Widely-used public benchmarks are of huge importance to computer vision and machine learning research, especially with the computational resources required to reproduce state of the art results quickly becoming untenable. In medical image computing, the wide variety of image modalities and problem formulations yields a huge task-space for benchmarks to cover, and thus the widespread adoption of standard benchmarks has been slow, and barriers to releasing medical data exacerbate this issue. In this paper, we examine the role that publicly available data has played in MICCAI papers from the past five years. We find that more than half of these papers are based on private data alone, although this proportion seems to be decreasing over time. Additionally, we observed that after controlling for open access publication and the release of code, papers based on public data were cited over 60% more per year than their private-data counterparts. Further, we found that more than 20% of papers using public data did not provide a citation to the dataset or associated manuscript, highlighting the "second-rate" status that data contributions often take compared to theoretical ones. We conclude by making recommendations for MICCAI policies which could help to better incentivise data sharing and move the field toward more efficient and reproducible science.