 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrete Gene Crossover Accelerates Solution Discovery in Quality-Diversity Algorithms
Feb 14, 2026Quality-Diversity (QD) algorithms aim to discover diverse, high-performing solutions across behavioral niches. However, QD search often stagnates as incremental variation operators struggle to propagate building blocks across large populations. Existing mutation operators rely on gradual variation to solutions, limiting their ability to efficiently explore regions of the search space distant from parent solutions or to spread beneficial genetic material through the population. We propose a mutation operator which augments variation-based operators with discrete, gene-level crossover, enabling rapid recombination of elite genetic material. This crossover mechanism mirrors the biological principle of meiosis and facilitates both the direct transfer of genetic material and the exploration of novel genotype configurations beyond the existing elite hypervolume. We evaluate operators on three locomotion environments, demonstrating improvements in QD score, coverage, and max fitness, with particularly strong performance in later stages of optimization once building blocks have been established in the archive. These results show that the addition of a discrete crossover mutation provides a complementary exploration mechanism that sustains quality-diversity growth beyond the performance demonstrated by existing operators.
Interpretability by Design for Efficient Multi-Objective Reinforcement Learning
Jun 04, 2025Multi-objective reinforcement learning (MORL) aims at optimising several, often conflicting goals in order to improve flexibility and reliability of RL in practical tasks. This can be achieved by finding diverse policies that are optimal for some objective preferences and non-dominated by optimal policies for other preferences so that they form a Pareto front in the multi-objective performance space. The relation between the multi-objective performance space and the parameter space that represents the policies is generally non-unique. Using a training scheme that is based on a locally linear map between the parameter space and the performance space, we show that an approximate Pareto front can provide an interpretation of the current parameter vectors in terms of the objectives which enables an effective search within contiguous solution domains. Experiments are conducted with and without retraining across different domains, and the comparison with previous methods demonstrates the efficiency of our approach.
Evolutionary Selective Imitation: Interpretable Agents by Imitation Learning Without a Demonstrator
Sep 17, 2020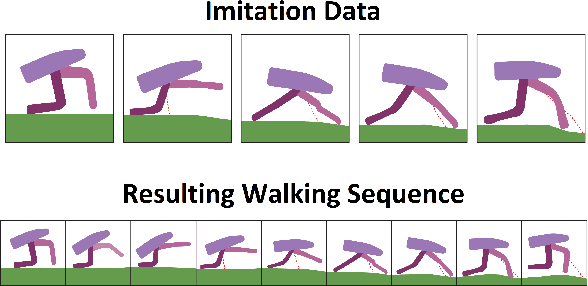
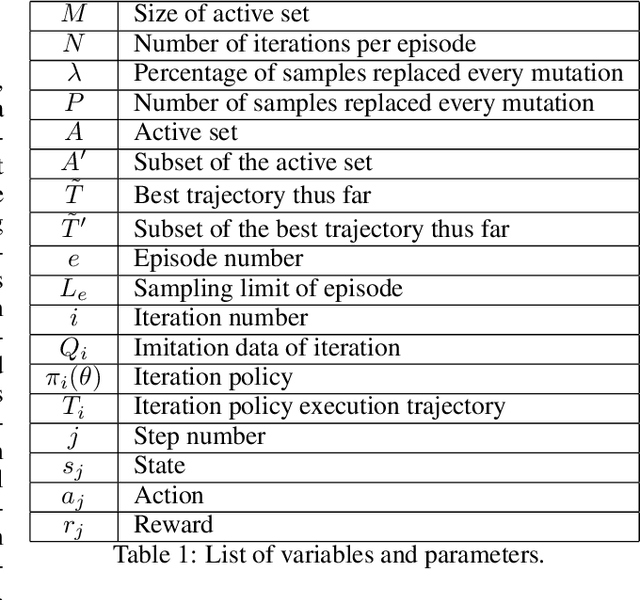
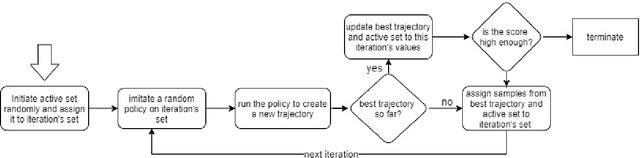
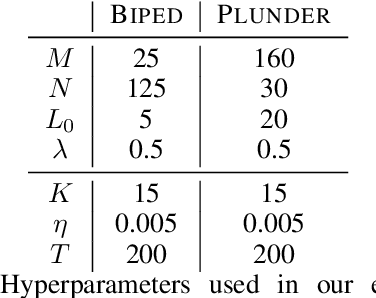
We propose a new method for training an agent via an evolutionary strategy (ES), in which we iteratively improve a set of samples to imitate: Starting with a random set, in every iteration we replace a subset of the samples with samples from the best trajectories discovered so far. The evaluation procedure for this set is to train, via supervised learning, a randomly initialised neural network (NN) to imitate the set and then execute the acquired policy against the environment. Our method is thus an ES based on a fitness function that expresses the effectiveness of imitating an evolving data subset. This is in contrast to other ES techniques that iterate over the weights of the policy directly. By observing the samples that the agent selects for learning, it is possible to interpret and evaluate the evolving strategy of the agent more explicitly than in NN learning. In our experiments, we trained an agent to solve the OpenAI Gym environment Bipedalwalker-v3 by imitating an evolutionarily selected set of only 25 samples with a NN with only a few thousand parameters. We further test our method on the Procgen game Plunder and show here as well that the proposed method is an interpretable, small, robust and effective alternative to other ES or policy gradient methods.
Lagged correlation-based deep learning for directional trend change prediction in financial time series
Nov 29, 2018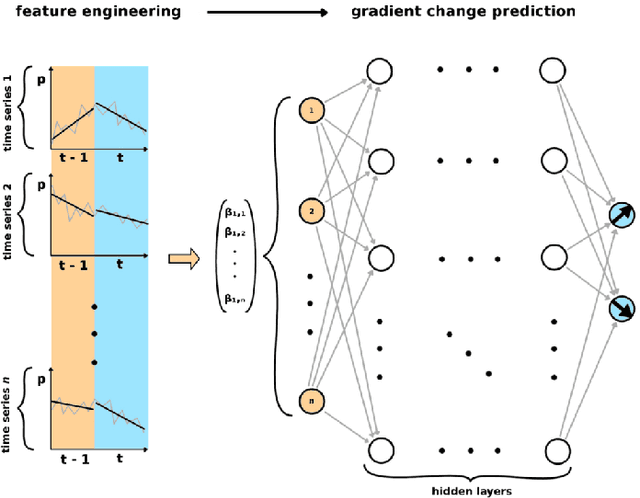
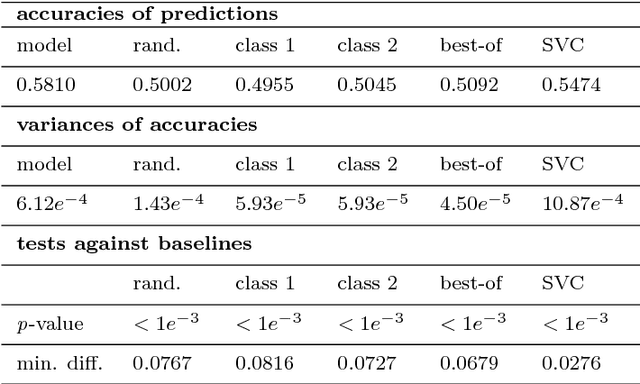
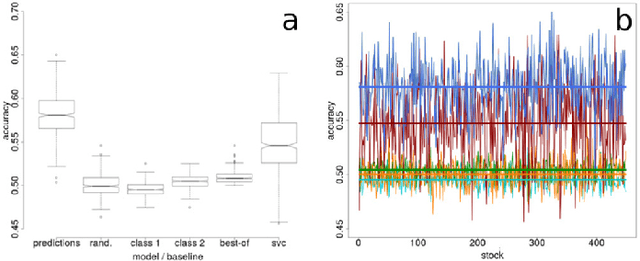
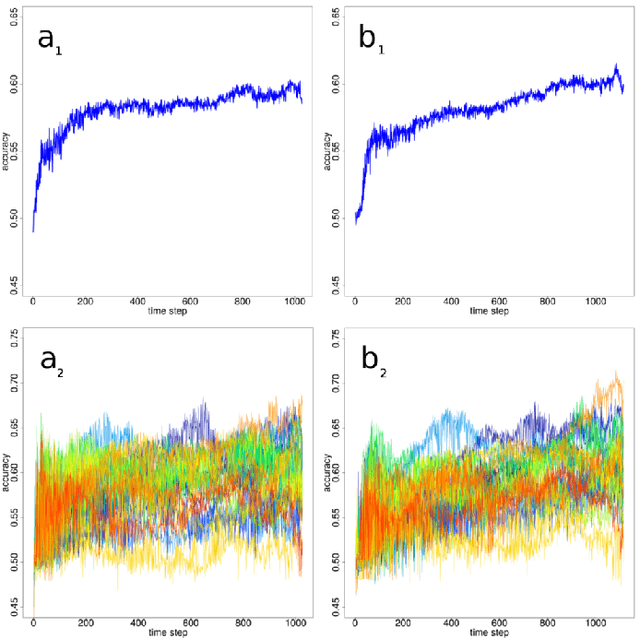
Trend change prediction in complex systems with a large number of noisy time series is a problem with many applications for real-world phenomena, with stock markets as a notoriously difficult to predict example of such systems. We approach predictions of directional trend changes via complex lagged correlations between them, excluding any information about the target series from the respective inputs to achieve predictions purely based on such correlations with other series. We propose the use of deep neural networks that employ step-wise linear regressions with exponential smoothing in the preparatory feature engineering for this task, with regression slopes as trend strength indicators for a given time interval. We apply this method to historical stock market data from 2011 to 2016 as a use case example of lagged correlations between large numbers of time series that are heavily influenced by externally arising new information as a random factor. The results demonstrate the viability of the proposed approach, with state-of-the-art accuracies and accounting for the statistical significance of the results for additional validation, as well as important implications for modern financial economics.
* 11 pages, 4 figures
The Voynich Manuscript is Written in Natural Language: The Pahlavi Hypothesis
Oct 06, 2017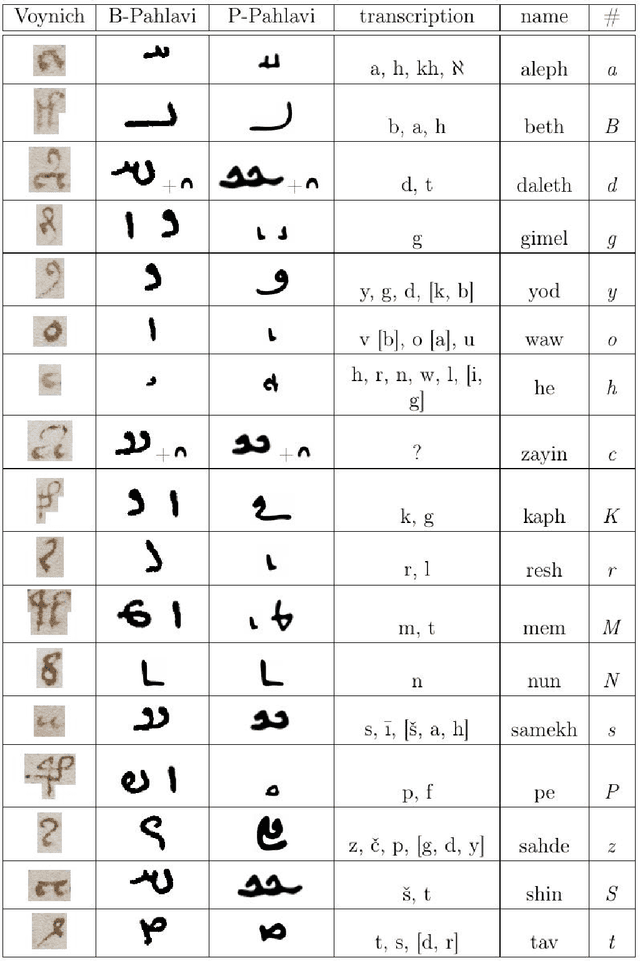

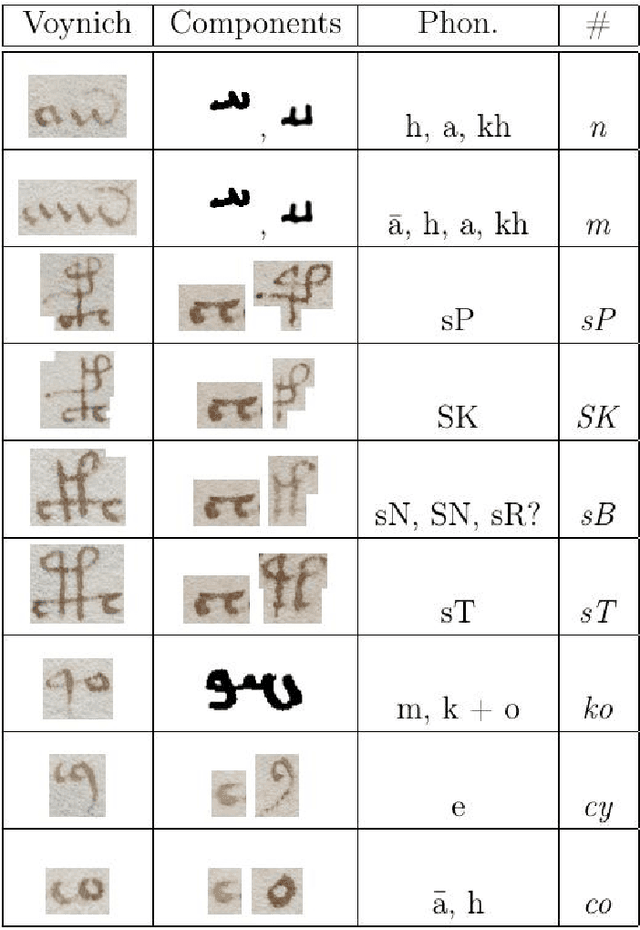
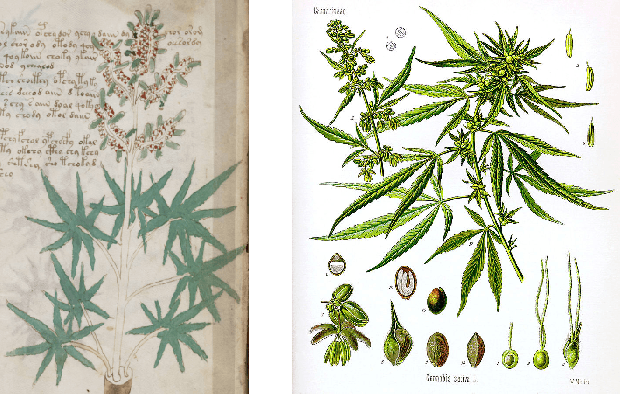
The late medieval Voynich Manuscript (VM) has resisted decryption and was considered a meaningless hoax or an unsolvable cipher. Here, we provide evidence that the VM is written in natural language by establishing a relation of the Voynich alphabet and the Iranian Pahlavi script. Many of the Voynich characters are upside-down versions of their Pahlavi counterparts, which may be an effect of different writing directions. Other Voynich letters can be explained as ligatures or departures from Pahlavi with the intent to cope with known problems due to the stupendous ambiguity of Pahlavi text. While a translation of the VM text is not attempted here, we can confirm the Voynich-Pahlavi relation at the character level by the transcription of many words from the VM illustrations and from parts of the main text. Many of the transcribed words can be identified as terms from Zoroastrian cosmology which is in line with the use of Pahlavi script in Zoroastrian communities from medieval times.
Critical Parameters in Particle Swarm Optimisation
Nov 19, 2015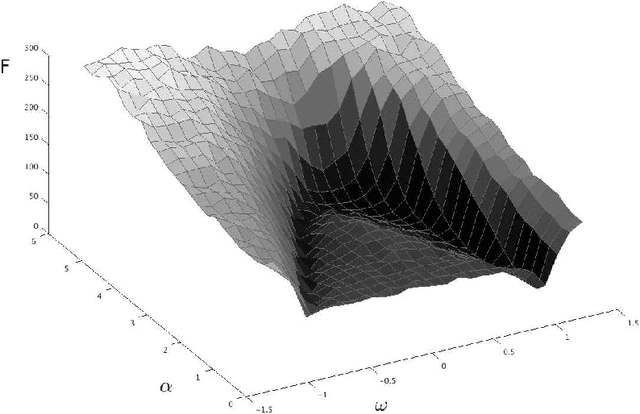
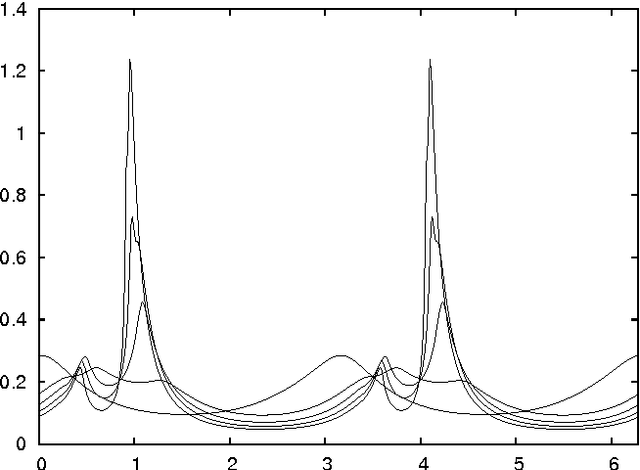
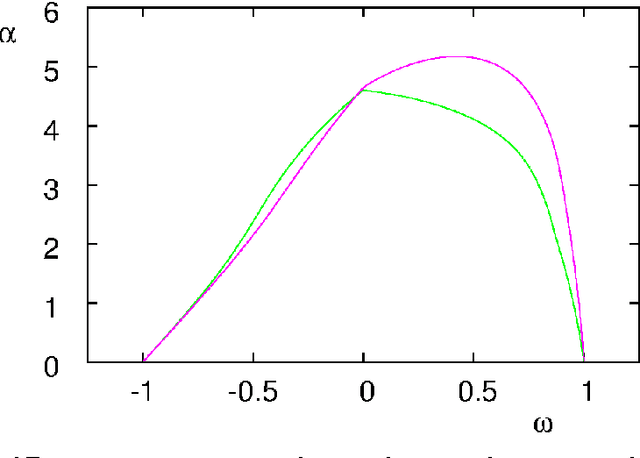
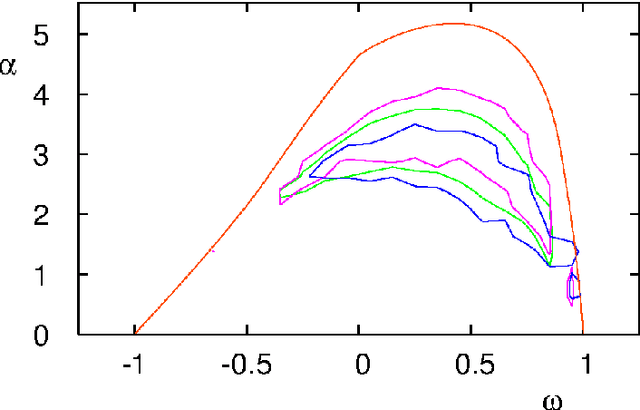
Particle swarm optimisation is a metaheuristic algorithm which finds reasonable solutions in a wide range of applied problems if suitable parameters are used. We study the properties of the algorithm in the framework of random dynamical systems which, due to the quasi-linear swarm dynamics, yields analytical results for the stability properties of the particles. Such considerations predict a relationship between the parameters of the algorithm that marks the edge between convergent and divergent behaviours. Comparison with simulations indicates that the algorithm performs best near this margin of instability.