 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Plans that Predict Themselves
Feb 14, 2018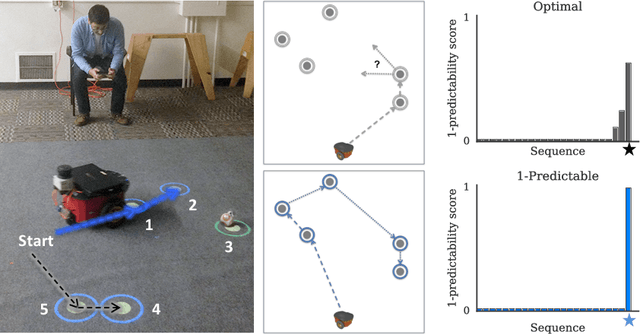
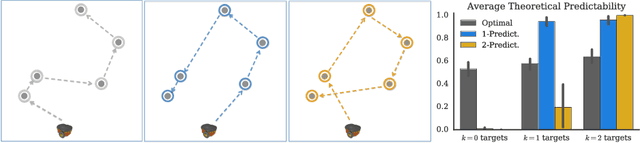
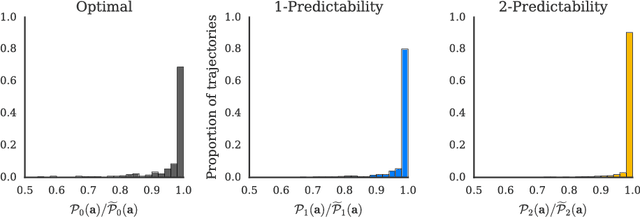
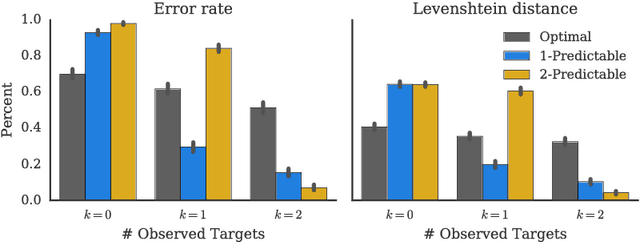
Collaboration requires coordination, and we coordinate by anticipating our teammates' future actions and adapting to their plan. In some cases, our teammates' actions early on can give us a clear idea of what the remainder of their plan is, i.e. what action sequence we should expect. In others, they might leave us less confident, or even lead us to the wrong conclusion. Our goal is for robot actions to fall in the first category: we want to enable robots to select their actions in such a way that human collaborators can easily use them to correctly anticipate what will follow. While previous work has focused on finding initial plans that convey a set goal, here we focus on finding two portions of a plan such that the initial portion conveys the final one. We introduce $t$-\ACty{}: a measure that quantifies the accuracy and confidence with which human observers can predict the remaining robot plan from the overall task goal and the observed initial $t$ actions in the plan. We contribute a method for generating $t$-predictable plans: we search for a full plan that accomplishes the task, but in which the first $t$ actions make it as easy as possible to infer the remaining ones. The result is often different from the most efficient plan, in which the initial actions might leave a lot of ambiguity as to how the task will be completed. Through an online experiment and an in-person user study with physical robots, we find that our approach outperforms a traditional efficiency-based planner in objective and subjective collaboration metrics.
* Published at the Workshop on Algorithmic Foundations of Robotics (WAFR 2016)
Goal Inference Improves Objective and Perceived Performance in Human-Robot Collaboration
Feb 06, 2018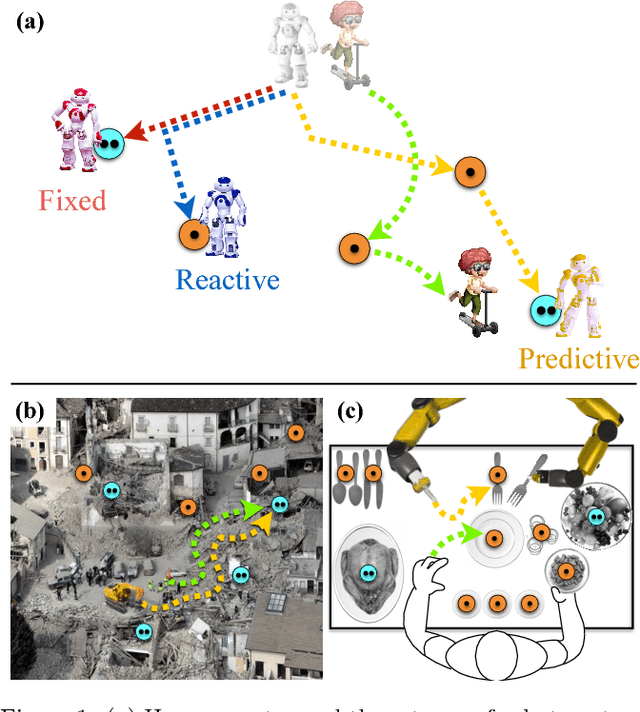
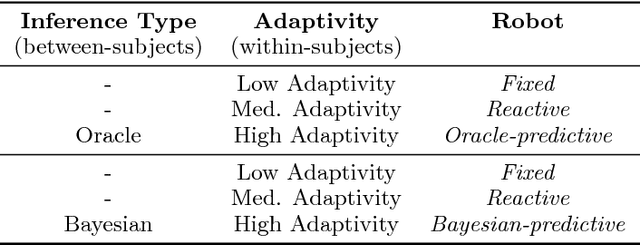
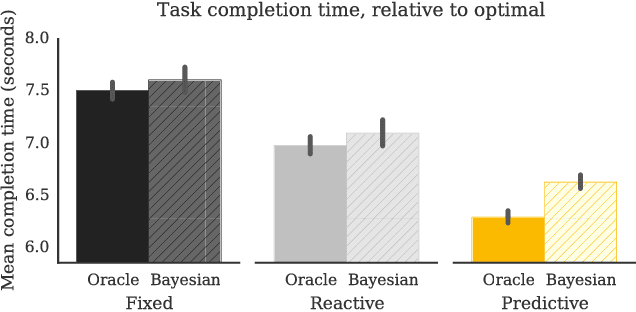
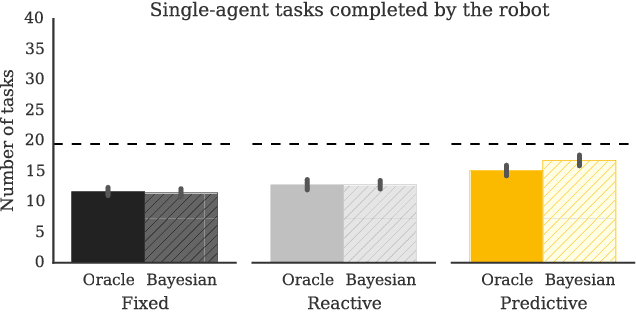
The study of human-robot interaction is fundamental to the design and use of robotics in real-world applications. Robots will need to predict and adapt to the actions of human collaborators in order to achieve good performance and improve safety and end-user adoption. This paper evaluates a human-robot collaboration scheme that combines the task allocation and motion levels of reasoning: the robotic agent uses Bayesian inference to predict the next goal of its human partner from his or her ongoing motion, and re-plans its own actions in real time. This anticipative adaptation is desirable in many practical scenarios, where humans are unable or unwilling to take on the cognitive overhead required to explicitly communicate their intent to the robot. A behavioral experiment indicates that the combination of goal inference and dynamic task planning significantly improves both objective and perceived performance of the human-robot team. Participants were highly sensitive to the differences between robot behaviors, preferring to work with a robot that adapted to their actions over one that did not.
* Published at the International Conference on Autonomous Agents and Multiagent Systems (AAMAS 2016)
Feature Analysis and Selection for Training an End-to-End Autonomous Vehicle Controller Using the Deep Learning Approach
Mar 28, 2017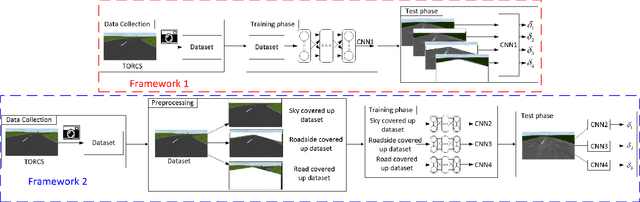
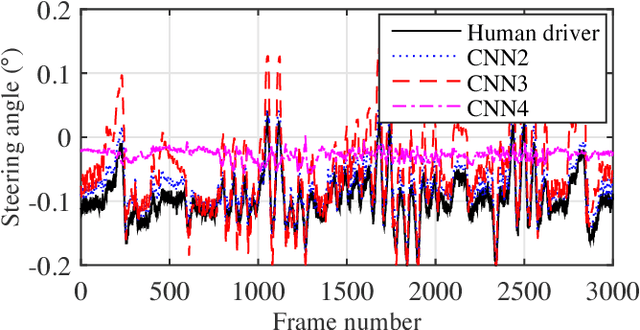


Deep learning-based approaches have been widely used for training controllers for autonomous vehicles due to their powerful ability to approximate nonlinear functions or policies. However, the training process usually requires large labeled data sets and takes a lot of time. In this paper, we analyze the influences of features on the performance of controllers trained using the convolutional neural networks (CNNs), which gives a guideline of feature selection to reduce computation cost. We collect a large set of data using The Open Racing Car Simulator (TORCS) and classify the image features into three categories (sky-related, roadside-related, and road-related features).We then design two experimental frameworks to investigate the importance of each single feature for training a CNN controller.The first framework uses the training data with all three features included to train a controller, which is then tested with data that has one feature removed to evaluate the feature's effects. The second framework is trained with the data that has one feature excluded, while all three features are included in the test data. Different driving scenarios are selected to test and analyze the trained controllers using the two experimental frameworks. The experiment results show that (1) the road-related features are indispensable for training the controller, (2) the roadside-related features are useful to improve the generalizability of the controller to scenarios with complicated roadside information, and (3) the sky-related features have limited contribution to train an end-to-end autonomous vehicle controller.