 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA User-Guided Bayesian Framework for Ensemble Feature Selection in Life Science Applications
May 28, 2021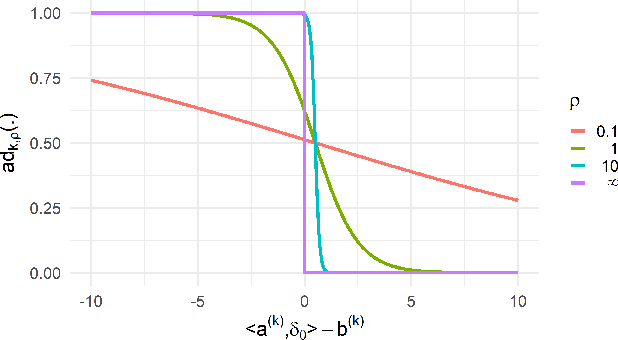
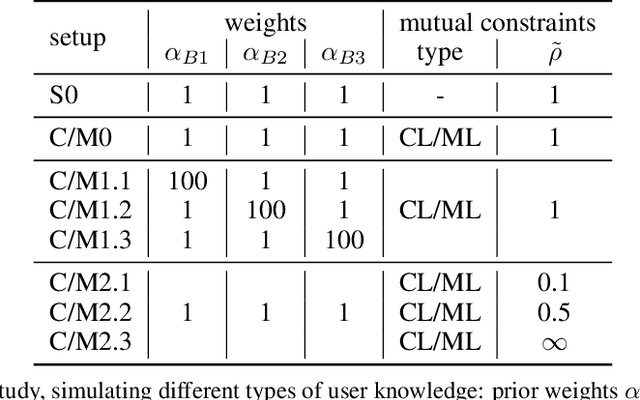
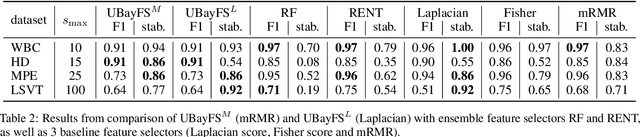
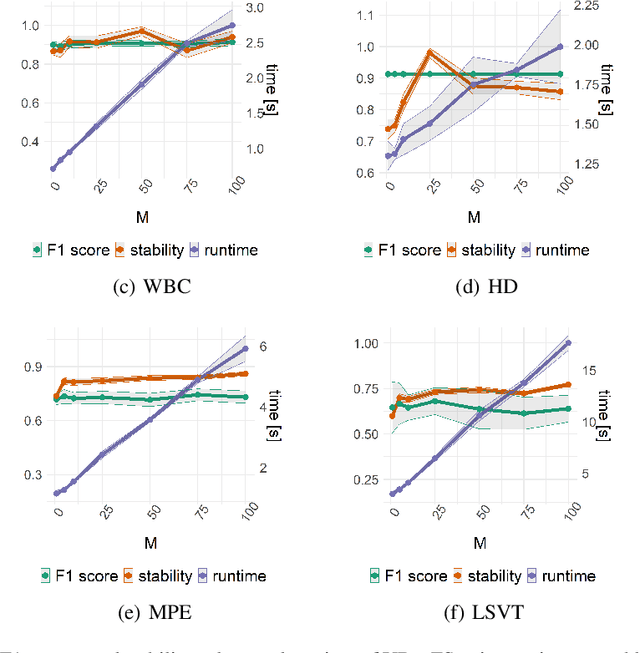
Training machine learning models on high-dimensional datasets is a challenging task and requires measures to prevent overfitting and to keep model complexity low. Feature selection, which represents such a measure, plays a key role in data preprocessing and may provide insights into the systematic variation in the data. The latter aspect is crucial in domains that rely on model interpretability, such as life sciences. We propose UBayFS, an ensemble feature selection technique, embedded in a Bayesian statistical framework. Our approach considers two sources of information: data and domain knowledge. We build an ensemble of elementary feature selectors that extract information from empirical data and aggregate this information to form a meta-model, which compensates for inconsistencies between elementary feature selectors. The user guides UBayFS by weighting features and penalizing specific feature blocks or combinations. The framework builds on a multinomial likelihood and a novel version of constrained Dirichlet-type prior distribution, involving initial feature weights and side constraints. In a quantitative evaluation, we demonstrate that the presented framework allows for a balanced trade-off between user knowledge and data observations. A comparison with standard feature selectors underlines that UBayFS achieves competitive performance, while providing additional flexibility to incorporate domain knowledge.
From a Point Cloud to a Simulation Model: Bayesian Segmentation and Entropy based Uncertainty Estimation for 3D Modelling
Feb 04, 2021

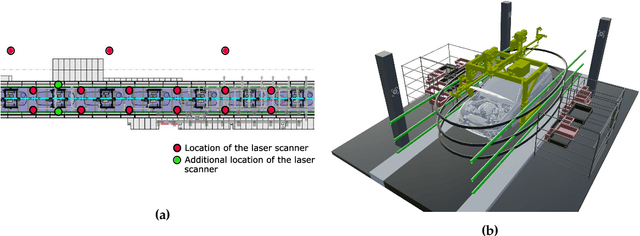

The 3D modelling of indoor environments and the generation of process simulations play an important role in factory and assembly planning. In brownfield planning cases existing data are often outdated and incomplete especially for older plants, which were mostly planned in 2D. Thus, current environment models cannot be generated directly on the basis of existing data and a holistic approach on how to build such a factory model in a highly automated fashion is mostly non-existent. Major steps in generating an environment model in a production plant include data collection and pre-processing, object identification as well as pose estimation. In this work, we elaborate a methodical workflow, which starts with the digitalization of large-scale indoor environments and ends with the generation of a static environment or simulation model. The object identification step is realized using a Bayesian neural network capable of point cloud segmentation. We elaborate how the information on network uncertainty generated by a Bayesian segmentation framework can be used in order to build up a more accurate environment model. The steps of data collection and point cloud segmentation as well as the resulting model accuracy are evaluated on a real-world data set collected at the assembly line of a large-scale automotive production plant. The segmentation network is further evaluated on the publicly available Stanford Large-Scale 3D Indoor Spaces data set. The Bayesian segmentation network clearly surpasses the performance of the frequentist baseline and allows us to increase the accuracy of the model placement in a simulation scene considerably.
A Bayesian Approach for Predicting Food and Beverage Sales in Staff Canteens and Restaurants
May 26, 2020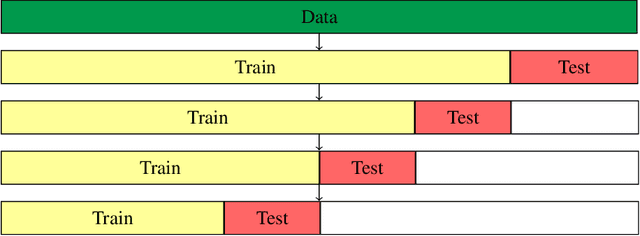
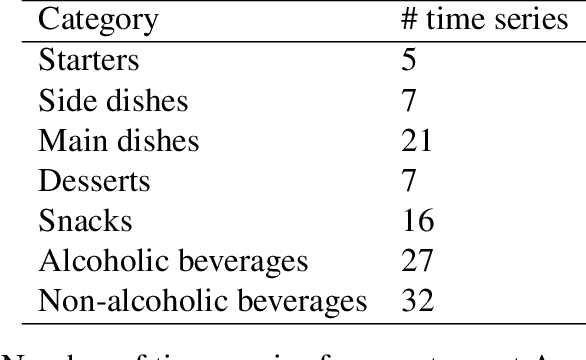
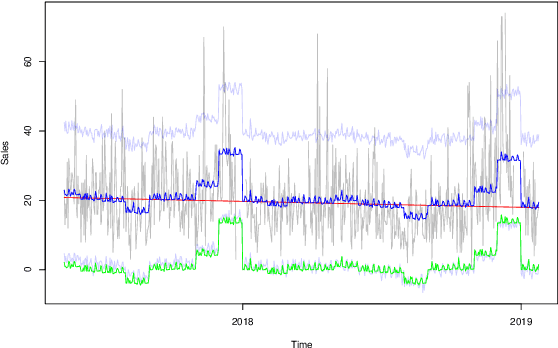
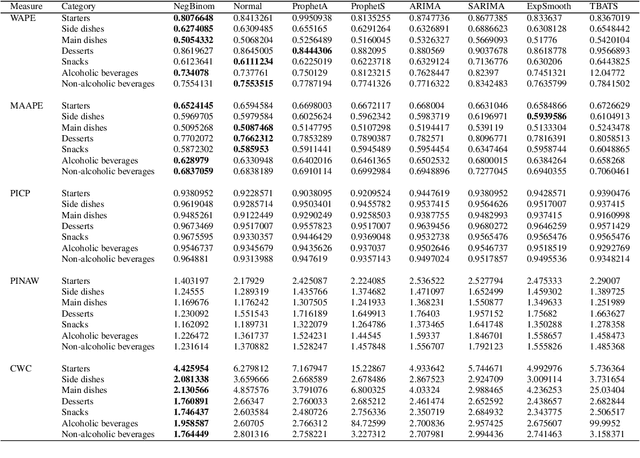
Accurate demand forecasting is one of the key aspects for successfully managing restaurants and staff canteens. In particular, properly predicting future sales of menu items allows a precise ordering of food stock. From an environmental point of view, this ensures maintaining a low level of pre-consumer food waste, while from the managerial point of view, this is critical to guarantee the profitability of the restaurant. Hence, we are interested in predicting future values of the daily sold quantities of given menu items. The corresponding time series show multiple strong seasonalities, trend changes, data gaps, and outliers. We propose a forecasting approach that is solely based on the data retrieved from Point of Sales systems and allows for a straightforward human interpretation. Therefore, we propose two generalized additive models for predicting the future sales. In an extensive evaluation, we consider two data sets collected at a casual restaurant and a large staff canteen consisting of multiple time series, that cover a period of 20 months, respectively. We show that the proposed models fit the features of the considered restaurant data. Moreover, we compare the predictive performance of our method against the performance of other well-established forecasting approaches.
Correlated Parameters to Accurately Measure Uncertainty in Deep Neural Networks
Apr 02, 2019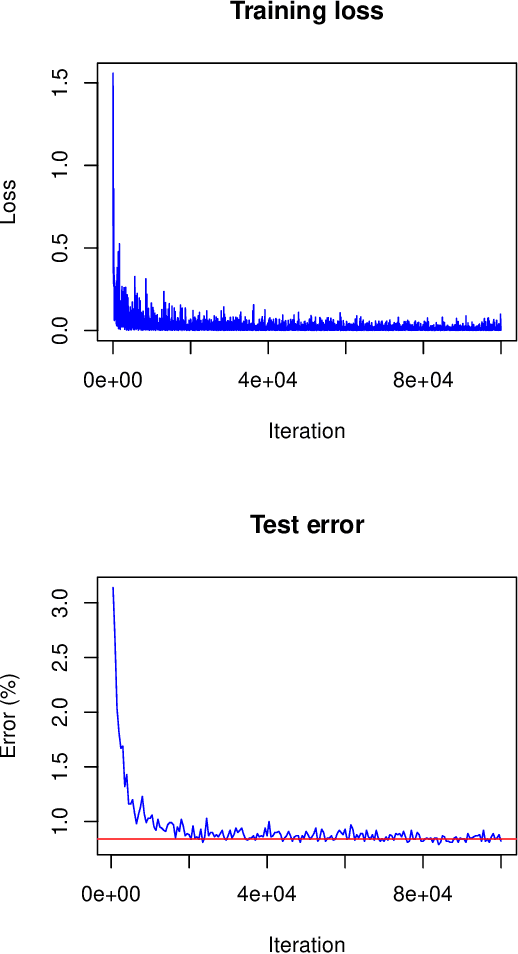
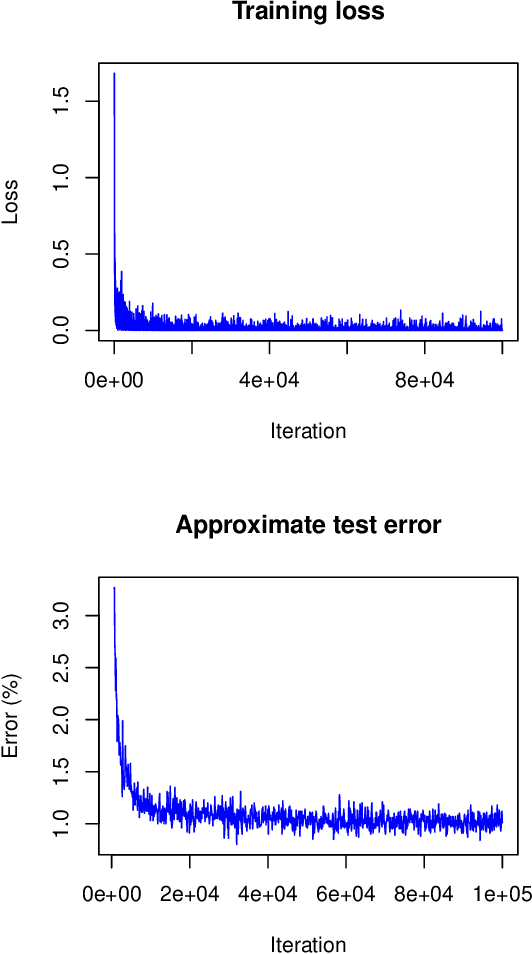
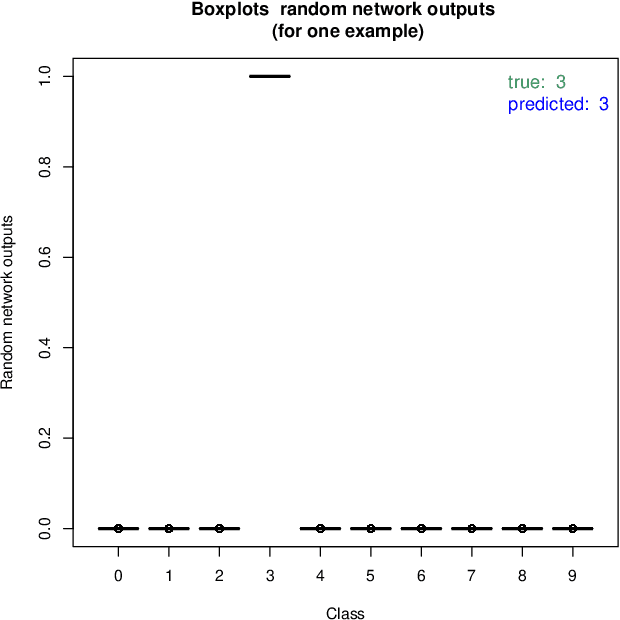
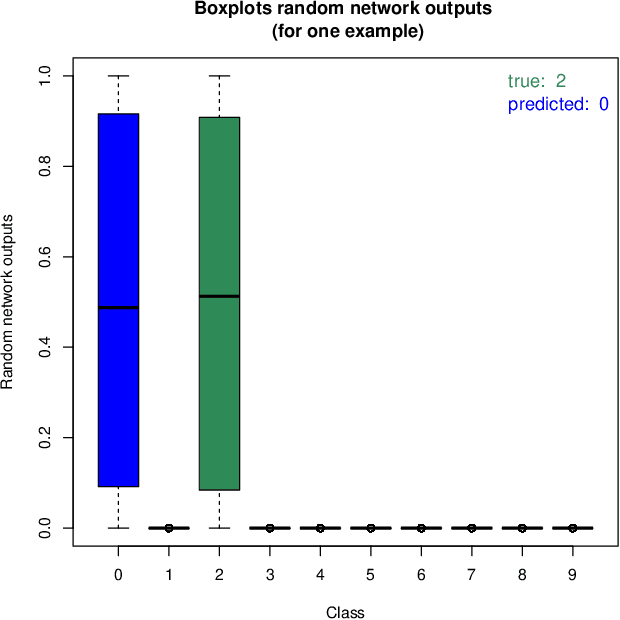
In this article a novel approach for training deep neural networks using Bayesian techniques is presented. The Bayesian methodology allows for an easy evaluation of model uncertainty and additionally is robust to overfitting. These are commonly the two main problems classical, i.e. non-Bayesian, architectures have to struggle with. The proposed approach applies variational inference in order to approximate the intractable posterior distribution. In particular, the variational distribution is defined as product of multiple multivariate normal distributions with tridiagonal covariance matrices. Each single normal distribution belongs either to the weights, or to the biases corresponding to one network layer. The layer-wise a posteriori variances are defined based on the corresponding expectation values and further the correlations are assumed to be identical. Therefore, only a few additional parameters need to be optimized compared to non-Bayesian settings. The novel approach is successfully evaluated on basis of the popular benchmark datasets MNIST and CIFAR-10.
Variational Inference to Measure Model Uncertainty in Deep Neural Networks
Mar 08, 2019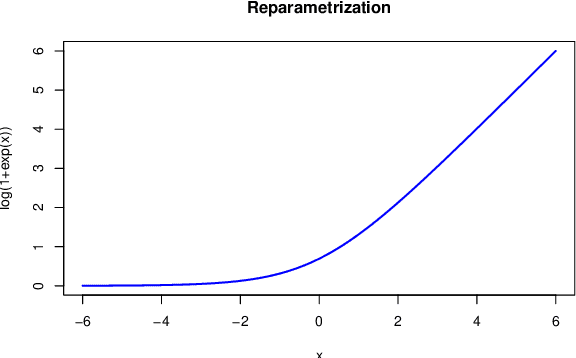

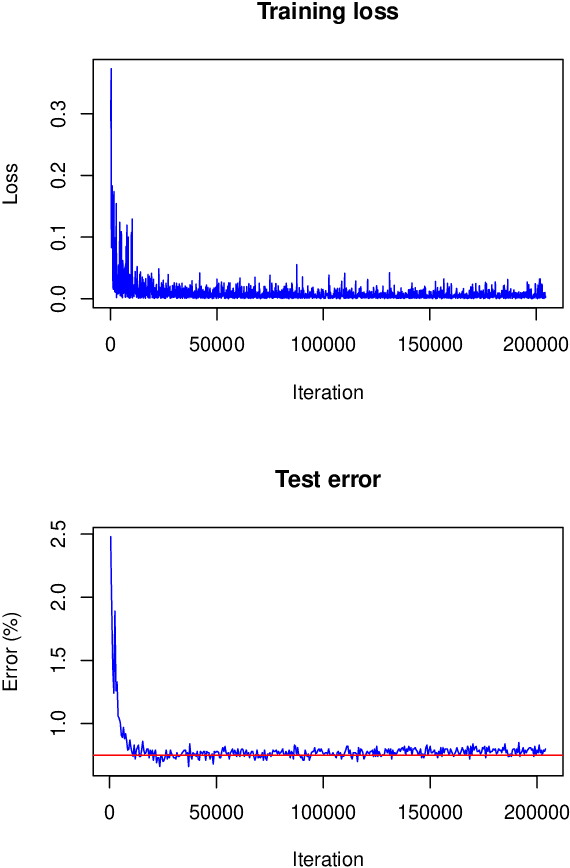
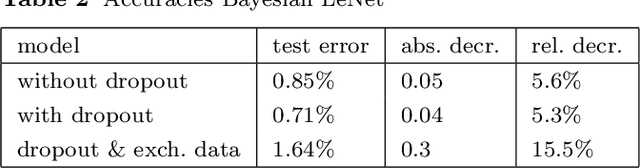
We present a novel approach for training deep neural networks in a Bayesian way. Classical, i.e. non-Bayesian, deep learning has two major drawbacks both originating from the fact that network parameters are considered to be deterministic. First, model uncertainty cannot be measured thus limiting the use of deep learning in many fields of application and second, training of deep neural networks is often hampered by overfitting. The proposed approach uses variational inference to approximate the intractable a posteriori distribution on basis of a normal prior. The variational density is designed in such a way that the a posteriori uncertainty of the network parameters is represented per network layer and depending on the estimated parameter expectation values. This way, only a few additional parameters need to be optimized compared to a non-Bayesian network. We apply this Bayesian approach to train and test the LeNet architecture on the MNIST dataset. Compared to classical deep learning, the test error is reduced by 15%. In addition, the trained model contains information about the parameter uncertainty in each layer. We show that this information can be used to calculate credible intervals for the prediction and to optimize the network architecture for a given training data set.