 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Understanding the Survival of Patients with High-Grade Gastroenteropancreatic Neuroendocrine Neoplasms: An Investigation of Ensemble Feature Selection in the Prediction of Overall Survival
Feb 20, 2023Determining the most informative features for predicting the overall survival of patients diagnosed with high-grade gastroenteropancreatic neuroendocrine neoplasms is crucial to improve individual treatment plans for patients, as well as the biological understanding of the disease. Recently developed ensemble feature selectors like the Repeated Elastic Net Technique for Feature Selection (RENT) and the User-Guided Bayesian Framework for Feature Selection (UBayFS) allow the user to identify such features in datasets with low sample sizes. While RENT is purely data-driven, UBayFS is capable of integrating expert knowledge a priori in the feature selection process. In this work we compare both feature selectors on a dataset comprising of 63 patients and 134 features from multiple sources, including basic patient characteristics, baseline blood values, tumor histology, imaging, and treatment information. Our experiments involve data-driven and expert-driven setups, as well as combinations of both. We use findings from clinical literature as a source of expert knowledge. Our results demonstrate that both feature selectors allow accurate predictions, and that expert knowledge has a stabilizing effect on the feature set, while the impact on predictive performance is limited. The features WHO Performance Status, Albumin, Platelets, Ki-67, Tumor Morphology, Total MTV, Total TLG, and SUVmax are the most stable and predictive features in our study.
Multiblock-Networks: A Neural Network Analog to Component Based Methods for Multi-Source Data
Sep 21, 2021

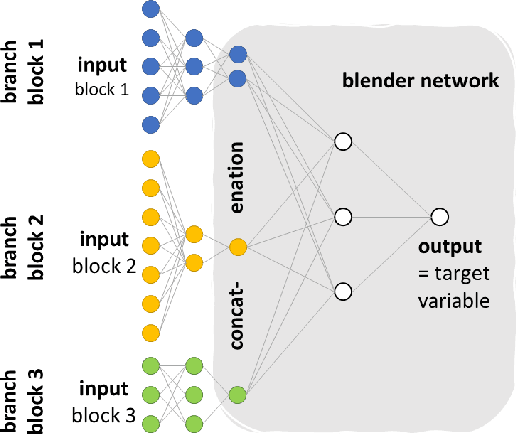
Training predictive models on datasets from multiple sources is a common, yet challenging setup in applied machine learning. Even though model interpretation has attracted more attention in recent years, many modeling approaches still focus mainly on performance. To further improve the interpretability of machine learning models, we suggest the adoption of concepts and tools from the well-established framework of component based multiblock analysis, also known as chemometrics. Nevertheless, artificial neural networks provide greater flexibility in model architecture and thus, often deliver superior predictive performance. In this study, we propose a setup to transfer the concepts of component based statistical models, including multiblock variants of principal component regression and partial least squares regression, to neural network architectures. Thereby, we combine the flexibility of neural networks with the concepts for interpreting block relevance in multiblock methods. In two use cases we demonstrate how the concept can be implemented in practice, and compare it to both common feed-forward neural networks without blocks, as well as statistical component based multiblock methods. Our results underline that multiblock networks allow for basic model interpretation while matching the performance of ordinary feed-forward neural networks.
A User-Guided Bayesian Framework for Ensemble Feature Selection in Life Science Applications
May 28, 2021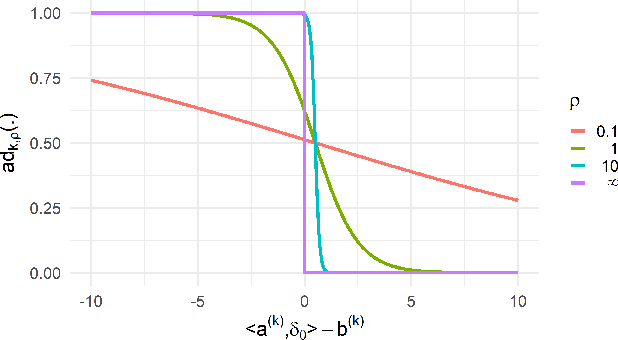
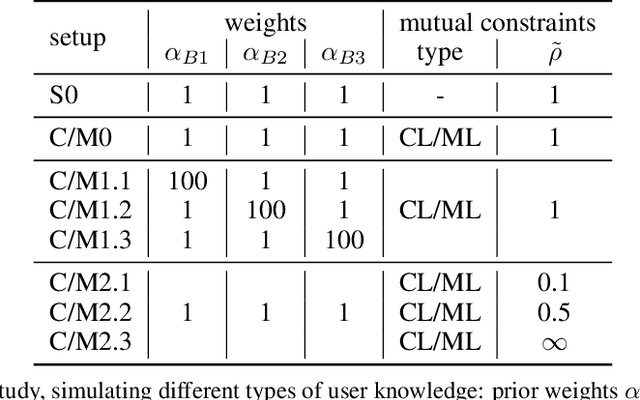
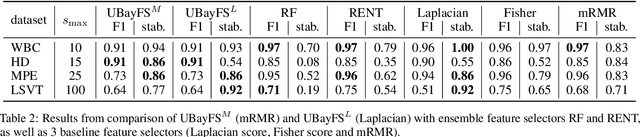
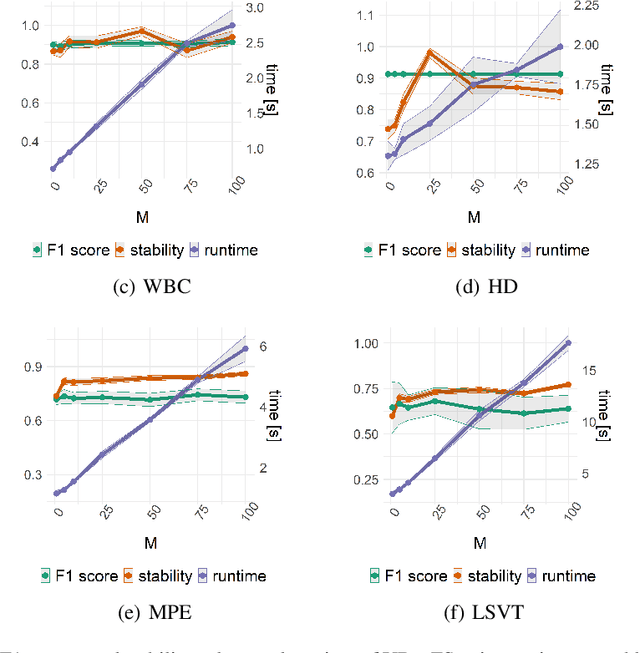
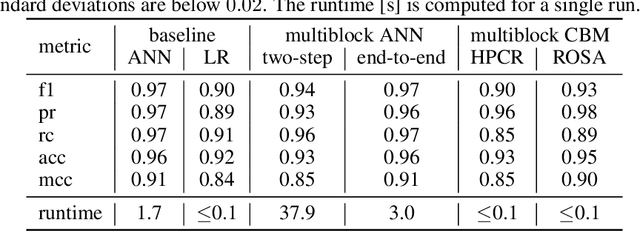
Training machine learning models on high-dimensional datasets is a challenging task and requires measures to prevent overfitting and to keep model complexity low. Feature selection, which represents such a measure, plays a key role in data preprocessing and may provide insights into the systematic variation in the data. The latter aspect is crucial in domains that rely on model interpretability, such as life sciences. We propose UBayFS, an ensemble feature selection technique, embedded in a Bayesian statistical framework. Our approach considers two sources of information: data and domain knowledge. We build an ensemble of elementary feature selectors that extract information from empirical data and aggregate this information to form a meta-model, which compensates for inconsistencies between elementary feature selectors. The user guides UBayFS by weighting features and penalizing specific feature blocks or combinations. The framework builds on a multinomial likelihood and a novel version of constrained Dirichlet-type prior distribution, involving initial feature weights and side constraints. In a quantitative evaluation, we demonstrate that the presented framework allows for a balanced trade-off between user knowledge and data observations. A comparison with standard feature selectors underlines that UBayFS achieves competitive performance, while providing additional flexibility to incorporate domain knowledge.
Machine Learning based Indicators to Enhance Process Monitoring by Pattern Recognition
Mar 24, 2021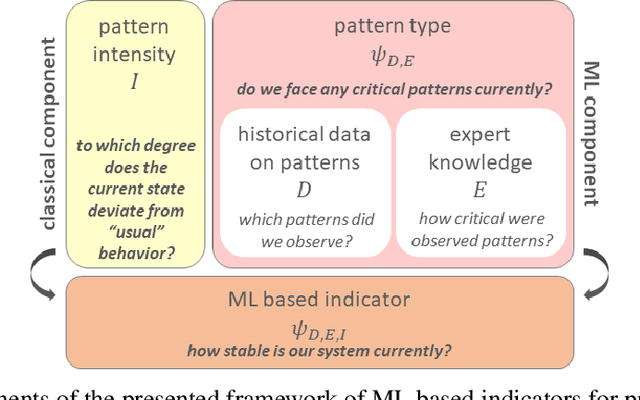
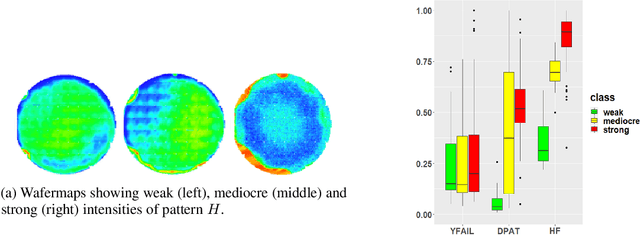
In industrial manufacturing, modern high-tech equipment delivers an increasing volume of data, which exceeds the capacities of human observers. Complex data formats like images make the detection of critical events difficult and require pattern recognition, which is beyond the scope of state-of-the-art process monitoring systems. Approaches that bridge the gap between conventional statistical tools and novel machine learning (ML) algorithms are required, but insufficiently studied. We propose a novel framework for ML based indicators combining both concepts by two components: pattern type and intensity. Conventional tools implement the intensity component, while the pattern type accounts for error modes and tailors the indicator to the production environment. In a case-study from semiconductor industry, our framework goes beyond conventional process control and achieves high quality experimental results. Thus, the suggested concept contributes to the integration of ML in real-world process monitoring problems and paves the way to automated decision support in manufacturing.
Principal component-based image segmentation: a new approach to outline in vitro cell colonies
Mar 10, 2021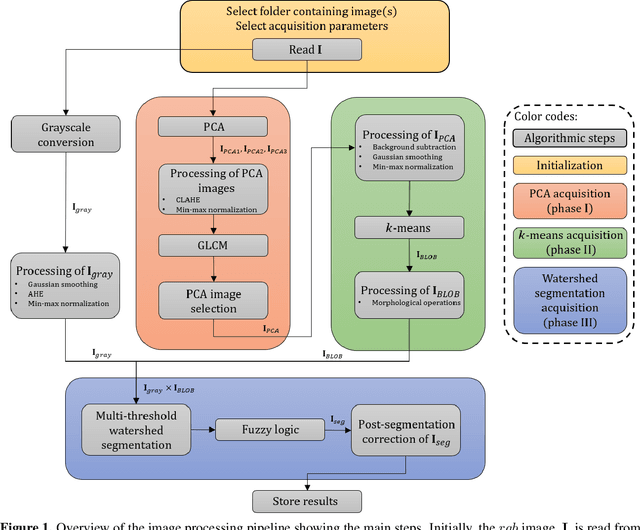
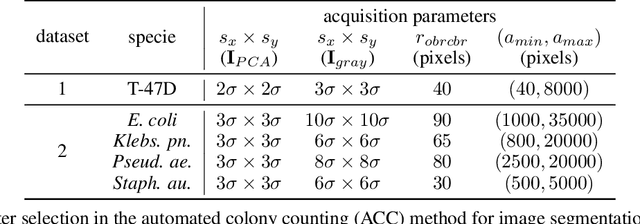

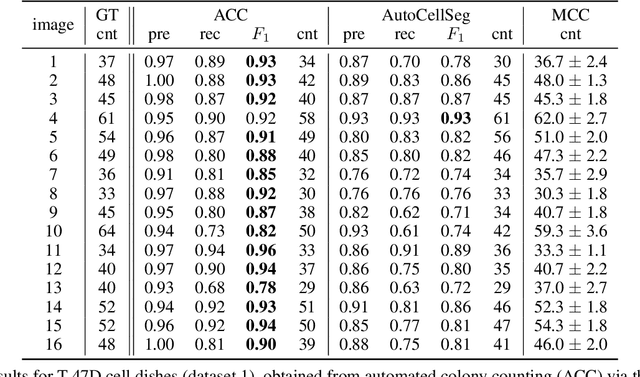
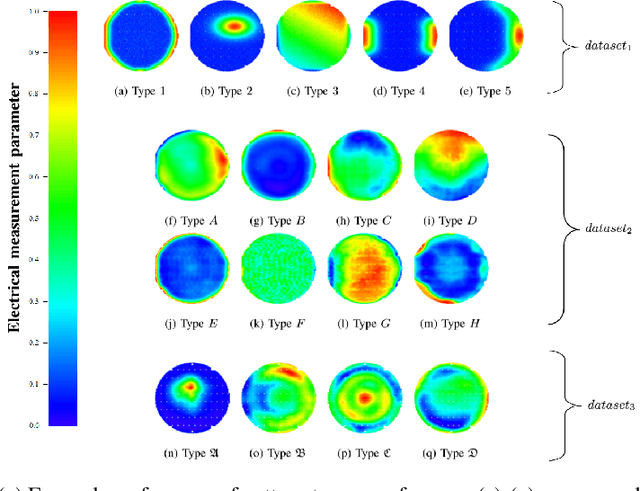
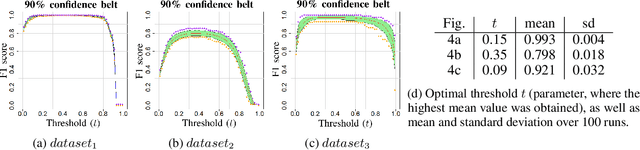
The in vitro clonogenic assay is a technique to study the ability of a cell to form a colony in a culture dish. By optical imaging, dishes with stained colonies can be scanned and assessed digitally. Identification, segmentation and counting of stained colonies play a vital part in high-throughput screening and quantitative assessment of biological assays. Image processing of such pictured/scanned assays can be affected by image/scan acquisition artifacts like background noise and spatially varying illumination, and contaminants in the suspension medium. Although existing approaches tackle these issues, the segmentation quality requires further improvement, particularly on noisy and low contrast images. In this work, we present an objective and versatile machine learning procedure to amend these issues by characterizing, extracting and segmenting inquired colonies using principal component analysis, k-means clustering and a modified watershed segmentation algorithm. The intention is to automatically identify visible colonies through spatial texture assessment and accordingly discriminate them from background in preparation for successive segmentation. The proposed segmentation algorithm yielded a similar quality as manual counting by human observers. High F1 scores (>0.9) and low root-mean-square errors (around 14%) underlined good agreement with ground truth data. Moreover, it outperformed a recent state-of-the-art method. The methodology will be an important tool in future cancer research applications.
RENT -- Repeated Elastic Net Technique for Feature Selection
Sep 27, 2020


In this study we present the RENT feature selection method for binary classification and regression problems. We compare the performance of RENT to a number of other state-of-the-art feature selection methods on eight datasets (six for binary classification and two for regression) to illustrate RENT's performance with regard to prediction and reduction of total number of features. At its core RENT trains an ensemble of unique models using regularized elastic net to select features. Each model in the ensemble is trained with a unique and randomly selected subset from the full training data. From these models one can acquire weight distributions for each feature that contain rich information on the stability of feature selection and from which several adjustable classification criteria may be defined. Moreover, we acquire distributions of class predictions for each sample across many models in the ensemble. Analysis of these distributions may provide useful insight into which samples are more difficult to classify correctly than others. Overall, results from the tested datasets show that RENT not only can compete on-par with the best performing feature selection methods in this study, but also provides valuable insights into the stability of feature selection and sample classification.