 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRENT -- Repeated Elastic Net Technique for Feature Selection
Sep 27, 2020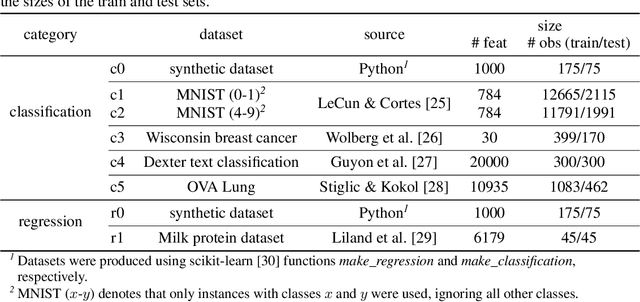


In this study we present the RENT feature selection method for binary classification and regression problems. We compare the performance of RENT to a number of other state-of-the-art feature selection methods on eight datasets (six for binary classification and two for regression) to illustrate RENT's performance with regard to prediction and reduction of total number of features. At its core RENT trains an ensemble of unique models using regularized elastic net to select features. Each model in the ensemble is trained with a unique and randomly selected subset from the full training data. From these models one can acquire weight distributions for each feature that contain rich information on the stability of feature selection and from which several adjustable classification criteria may be defined. Moreover, we acquire distributions of class predictions for each sample across many models in the ensemble. Analysis of these distributions may provide useful insight into which samples are more difficult to classify correctly than others. Overall, results from the tested datasets show that RENT not only can compete on-par with the best performing feature selection methods in this study, but also provides valuable insights into the stability of feature selection and sample classification.
Addressing Overfitting on Pointcloud Classification using Atrous XCRF
Feb 08, 2019



Advances in techniques for automated classification of pointcloud data introduce great opportunities for many new and existing applications. However, with a limited number of labeled points, automated classification by a machine learning model is prone to overfitting and poor generalization. The present paper addresses this problem by inducing controlled noise (on a trained model) generated by invoking conditional random field similarity penalties using nearby features. The method is called Atrous XCRF and works by forcing a trained model to respect the similarity penalties provided by unlabeled data. In a benchmark study carried out using the ISPRS 3D labeling dataset, our technique achieves 84.97% in term of overall accuracy, and 71.05% in term of F1 score. The result is on par with the current best model for the benchmark dataset and has the highest value in term of F1 score.