 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Sustainable Universal Deepfake Detection with Frequency-Domain Masking
Dec 08, 2025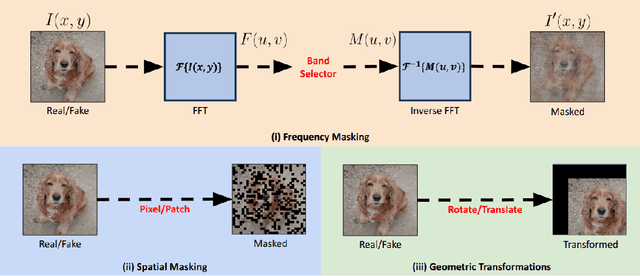
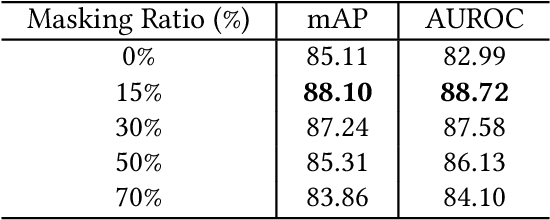
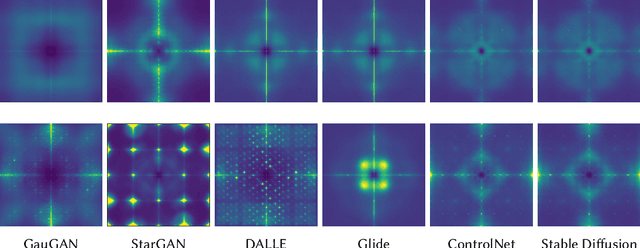
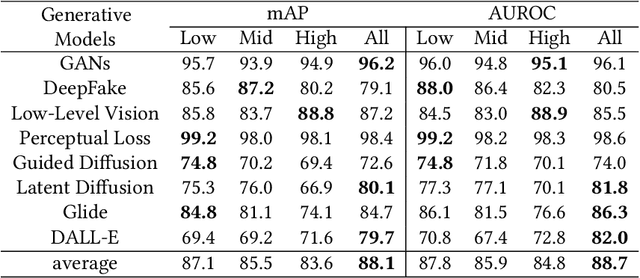
Universal deepfake detection aims to identify AI-generated images across a broad range of generative models, including unseen ones. This requires robust generalization to new and unseen deepfakes, which emerge frequently, while minimizing computational overhead to enable large-scale deepfake screening, a critical objective in the era of Green AI. In this work, we explore frequency-domain masking as a training strategy for deepfake detectors. Unlike traditional methods that rely heavily on spatial features or large-scale pretrained models, our approach introduces random masking and geometric transformations, with a focus on frequency masking due to its superior generalization properties. We demonstrate that frequency masking not only enhances detection accuracy across diverse generators but also maintains performance under significant model pruning, offering a scalable and resource-conscious solution. Our method achieves state-of-the-art generalization on GAN- and diffusion-generated image datasets and exhibits consistent robustness under structured pruning. These results highlight the potential of frequency-based masking as a practical step toward sustainable and generalizable deepfake detection. Code and models are available at: [https://github.com/chandlerbing65nm/FakeImageDetection](https://github.com/chandlerbing65nm/FakeImageDetection).
Multiblock-Networks: A Neural Network Analog to Component Based Methods for Multi-Source Data
Sep 21, 2021

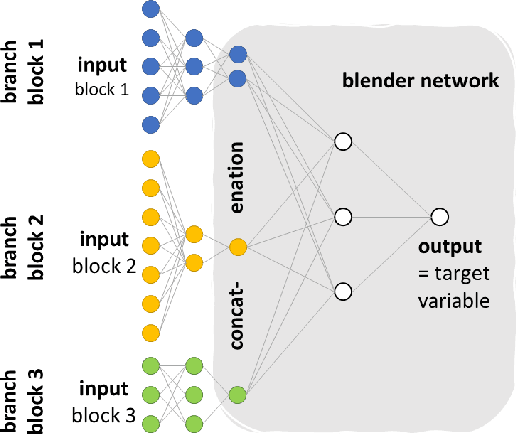
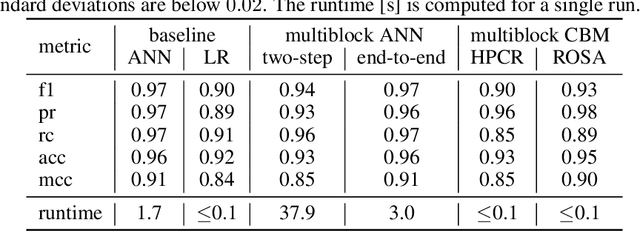
Training predictive models on datasets from multiple sources is a common, yet challenging setup in applied machine learning. Even though model interpretation has attracted more attention in recent years, many modeling approaches still focus mainly on performance. To further improve the interpretability of machine learning models, we suggest the adoption of concepts and tools from the well-established framework of component based multiblock analysis, also known as chemometrics. Nevertheless, artificial neural networks provide greater flexibility in model architecture and thus, often deliver superior predictive performance. In this study, we propose a setup to transfer the concepts of component based statistical models, including multiblock variants of principal component regression and partial least squares regression, to neural network architectures. Thereby, we combine the flexibility of neural networks with the concepts for interpreting block relevance in multiblock methods. In two use cases we demonstrate how the concept can be implemented in practice, and compare it to both common feed-forward neural networks without blocks, as well as statistical component based multiblock methods. Our results underline that multiblock networks allow for basic model interpretation while matching the performance of ordinary feed-forward neural networks.
RENT -- Repeated Elastic Net Technique for Feature Selection
Sep 27, 2020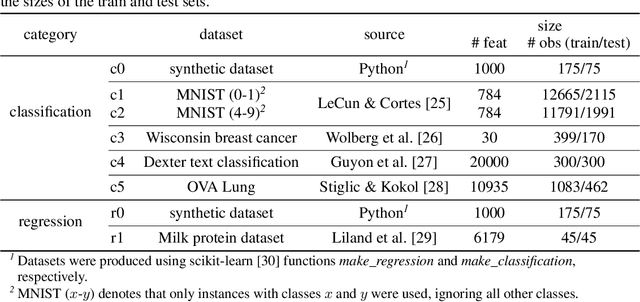


In this study we present the RENT feature selection method for binary classification and regression problems. We compare the performance of RENT to a number of other state-of-the-art feature selection methods on eight datasets (six for binary classification and two for regression) to illustrate RENT's performance with regard to prediction and reduction of total number of features. At its core RENT trains an ensemble of unique models using regularized elastic net to select features. Each model in the ensemble is trained with a unique and randomly selected subset from the full training data. From these models one can acquire weight distributions for each feature that contain rich information on the stability of feature selection and from which several adjustable classification criteria may be defined. Moreover, we acquire distributions of class predictions for each sample across many models in the ensemble. Analysis of these distributions may provide useful insight into which samples are more difficult to classify correctly than others. Overall, results from the tested datasets show that RENT not only can compete on-par with the best performing feature selection methods in this study, but also provides valuable insights into the stability of feature selection and sample classification.