 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Inference to Measure Model Uncertainty in Deep Neural Networks
Paper and Code
Mar 08, 2019

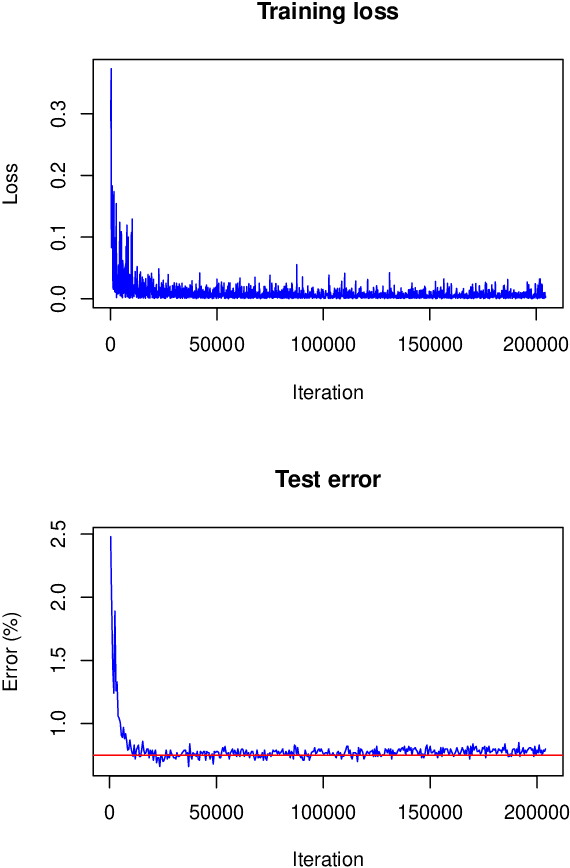
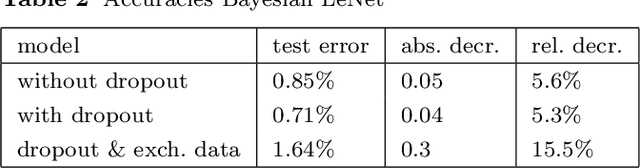
We present a novel approach for training deep neural networks in a Bayesian way. Classical, i.e. non-Bayesian, deep learning has two major drawbacks both originating from the fact that network parameters are considered to be deterministic. First, model uncertainty cannot be measured thus limiting the use of deep learning in many fields of application and second, training of deep neural networks is often hampered by overfitting. The proposed approach uses variational inference to approximate the intractable a posteriori distribution on basis of a normal prior. The variational density is designed in such a way that the a posteriori uncertainty of the network parameters is represented per network layer and depending on the estimated parameter expectation values. This way, only a few additional parameters need to be optimized compared to a non-Bayesian network. We apply this Bayesian approach to train and test the LeNet architecture on the MNIST dataset. Compared to classical deep learning, the test error is reduced by 15%. In addition, the trained model contains information about the parameter uncertainty in each layer. We show that this information can be used to calculate credible intervals for the prediction and to optimize the network architecture for a given training data set.