 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMorality is Contextual: Learning Interpretable Moral Contexts from Human Data with Probabilistic Clustering and Large Language Models
Dec 24, 2025Moral actions are judged not only by their outcomes but by the context in which they occur. We present COMETH (Contextual Organization of Moral Evaluation from Textual Human inputs), a framework that integrates a probabilistic context learner with LLM-based semantic abstraction and human moral evaluations to model how context shapes the acceptability of ambiguous actions. We curate an empirically grounded dataset of 300 scenarios across six core actions (violating Do not kill, Do not deceive, and Do not break the law) and collect ternary judgments (Blame/Neutral/Support) from N=101 participants. A preprocessing pipeline standardizes actions via an LLM filter and MiniLM embeddings with K-means, producing robust, reproducible core-action clusters. COMETH then learns action-specific moral contexts by clustering scenarios online from human judgment distributions using principled divergence criteria. To generalize and explain predictions, a Generalization module extracts concise, non-evaluative binary contextual features and learns feature weights in a transparent likelihood-based model. Empirically, COMETH roughly doubles alignment with majority human judgments relative to end-to-end LLM prompting (approx. 60% vs. approx. 30% on average), while revealing which contextual features drive its predictions. The contributions are: (i) an empirically grounded moral-context dataset, (ii) a reproducible pipeline combining human judgments with model-based context learning and LLM semantics, and (iii) an interpretable alternative to end-to-end LLMs for context-sensitive moral prediction and explanation.
High-fidelity social learning via shared episodic memories enhances collaborative foraging through mnemonic convergence
Dec 28, 2024Social learning, a cornerstone of cultural evolution, enables individuals to acquire knowledge by observing and imitating others. At the heart of its efficacy lies episodic memory, which encodes specific behavioral sequences to facilitate learning and decision-making. This study explores the interrelation between episodic memory and social learning in collective foraging. Using Sequential Episodic Control (SEC) agents capable of sharing complete behavioral sequences stored in episodic memory, we investigate how variations in the frequency and fidelity of social learning influence collaborative foraging performance. Furthermore, we analyze the effects of social learning on the content and distribution of episodic memories across the group. High-fidelity social learning is shown to consistently enhance resource collection efficiency and distribution, with benefits sustained across memory lengths. In contrast, low-fidelity learning fails to outperform nonsocial learning, spreading diverse but ineffective mnemonic patterns. Novel analyses using mnemonic metrics reveal that high-fidelity social learning also fosters mnemonic group alignment and equitable resource distribution, while low-fidelity conditions increase mnemonic diversity without translating to performance gains. Additionally, we identify an optimal range for episodic memory length in this task, beyond which performance plateaus. These findings underscore the critical effects of social learning on mnemonic group alignment and distribution and highlight the potential of neurocomputational models to probe the cognitive mechanisms driving cultural evolution.
Discretization of continuous input spaces in the hippocampal autoencoder
May 23, 2024The hippocampus has been associated with both spatial cognition and episodic memory formation, but integrating these functions into a unified framework remains challenging. Here, we demonstrate that forming discrete memories of visual events in sparse autoencoder neurons can produce spatial tuning similar to hippocampal place cells. We then show that the resulting very high-dimensional code enables neurons to discretize and tile the underlying image space with minimal overlap. Additionally, we extend our results to the auditory domain, showing that neurons similarly tile the frequency space in an experience-dependent manner. Lastly, we show that reinforcement learning agents can effectively perform various visuo-spatial cognitive tasks using these sparse, very high-dimensional representations.
Sequential Episodic Control
Dec 29, 2021
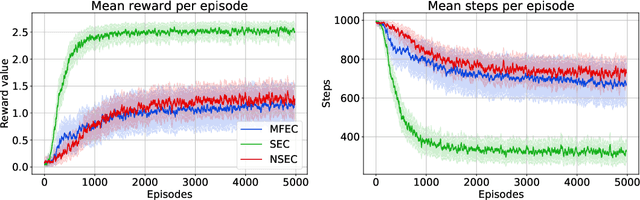
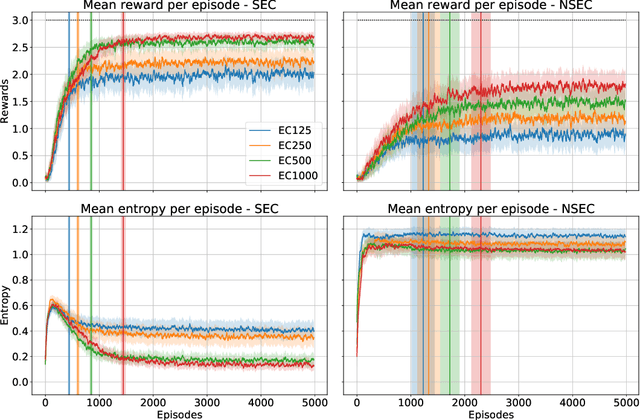
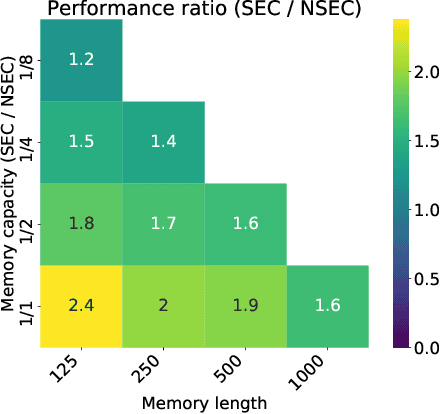
State of the art deep reinforcement learning algorithms are sample inefficient due to the large number of episodes they require to achieve asymptotic performance. Episodic Reinforcement Learning (ERL) algorithms, inspired by the mammalian hippocampus, typically use extended memory systems to bootstrap learning from past events to overcome this sample-inefficiency problem. However, such memory augmentations are often used as mere buffers, from which isolated past experiences are drawn to learn from in an offline fashion (e.g., replay). Here, we demonstrate that including a bias in the acquired memory content derived from the order of episodic sampling improves both the sample and memory efficiency of an episodic control algorithm. We test our Sequential Episodic Control (SEC) model in a foraging task to show that storing and using integrated episodes as event sequences leads to faster learning with fewer memory requirements as opposed to a standard ERL benchmark, Model-Free Episodic Control, that buffers isolated events only. We also study the effect of memory constraints and forgetting on the sequential and non-sequential version of the SEC algorithm. Furthermore, we discuss how a hippocampal-like fast memory system could bootstrap slow cortical and subcortical learning subserving habit formation in the mammalian brain.
Towards sample-efficient episodic control with DAC-ML
Dec 26, 2020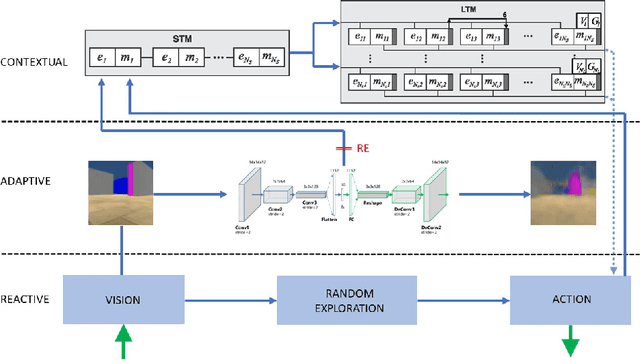

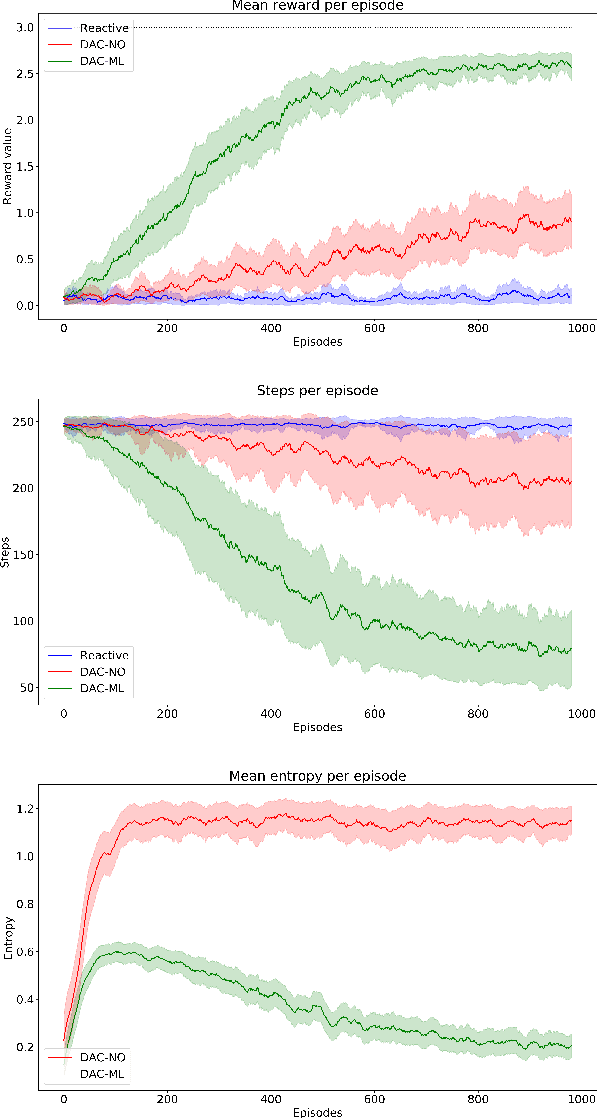
The sample-inefficiency problem in Artificial Intelligence refers to the inability of current Deep Reinforcement Learning models to optimize action policies within a small number of episodes. Recent studies have tried to overcome this limitation by adding memory systems and architectural biases to improve learning speed, such as in Episodic Reinforcement Learning. However, despite achieving incremental improvements, their performance is still not comparable to how humans learn behavioral policies. In this paper, we capitalize on the design principles of the Distributed Adaptive Control (DAC) theory of mind and brain to build a novel cognitive architecture (DAC-ML) that, by incorporating a hippocampus-inspired sequential memory system, can rapidly converge to effective action policies that maximize reward acquisition in a challenging foraging task.
Modeling Theory of Mind in Multi-Agent Games Using Adaptive Feedback Control
May 29, 2019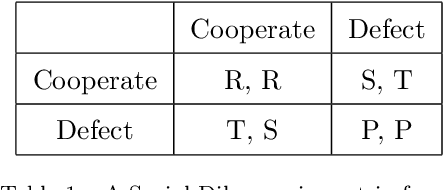
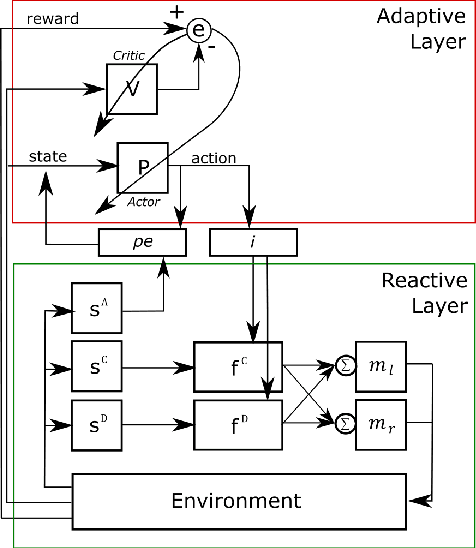
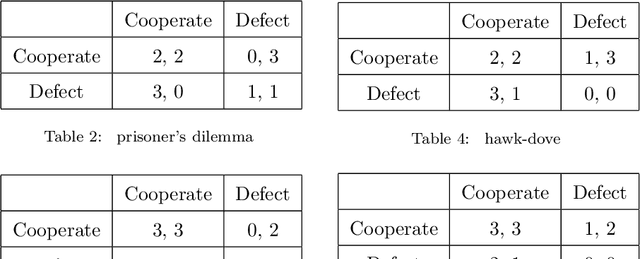
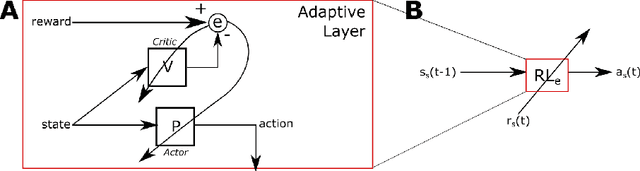
A major challenge in cognitive science and AI has been to understand how autonomous agents might acquire and predict behavioral and mental states of other agents in the course of complex social interactions. How does such an agent model the goals, beliefs, and actions of other agents it interacts with? What are the computational principles to model a Theory of Mind (ToM)? Deep learning approaches to address these questions fall short of a better understanding of the problem. In part, this is due to the black-box nature of deep networks, wherein computational mechanisms of ToM are not readily revealed. Here, we consider alternative hypotheses seeking to model how the brain might realize a ToM. In particular, we propose embodied and situated agent models based on distributed adaptive control theory to predict actions of other agents in five different game theoretic tasks (Harmony Game, Hawk-Dove, Stag-Hunt, Prisoner's Dilemma and Battle of the Exes). Our multi-layer control models implement top-down predictions from adaptive to reactive layers of control and bottom-up error feedback from reactive to adaptive layers. We test cooperative and competitive strategies among seven different agent models (cooperative, greedy, tit-for-tat, reinforcement-based, rational, predictive and other's-model agents). We show that, compared to pure reinforcement-based strategies, probabilistic learning agents modeled on rational, predictive and other's-model phenotypes perform better in game-theoretic metrics across tasks. Our autonomous multi-agent models capture systems-level processes underlying a ToM and highlight architectural principles of ToM from a control-theoretic perspective.
Modeling the Formation of Social Conventions in Multi-Agent Populations
Feb 16, 2018

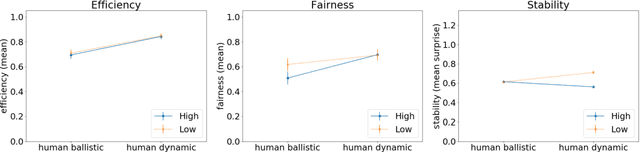

In order to understand the formation of social conventions we need to know the specific role of control and learning in multi-agent systems. To advance in this direction, we propose, within the framework of the Distributed Adaptive Control (DAC) theory, a novel Control-based Reinforcement Learning architecture (CRL) that can account for the acquisition of social conventions in multi-agent populations that are solving a benchmark social decision-making problem. Our new CRL architecture, as a concrete realization of DAC multi-agent theory, implements a low-level sensorimotor control loop handling the agent's reactive behaviors (pre-wired reflexes), along with a layer based on model-free reinforcement learning that maximizes long-term reward. We apply CRL in a multi-agent game-theoretic task in which coordination must be achieved in order to find an optimal solution. We show that our CRL architecture is able to both find optimal solutions in discrete and continuous time and reproduce human experimental data on standard game-theoretic metrics such as efficiency in acquiring rewards, fairness in reward distribution and stability of convention formation.