 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards sample-efficient episodic control with DAC-ML
Paper and Code
Dec 26, 2020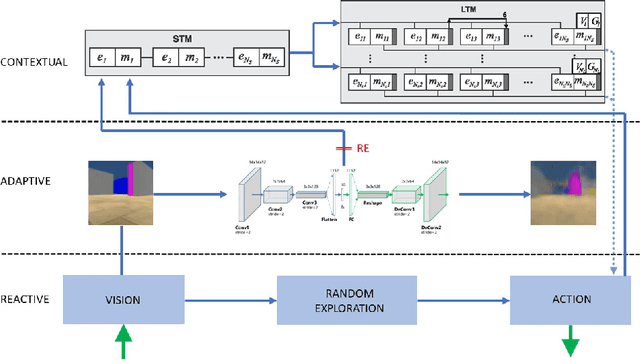

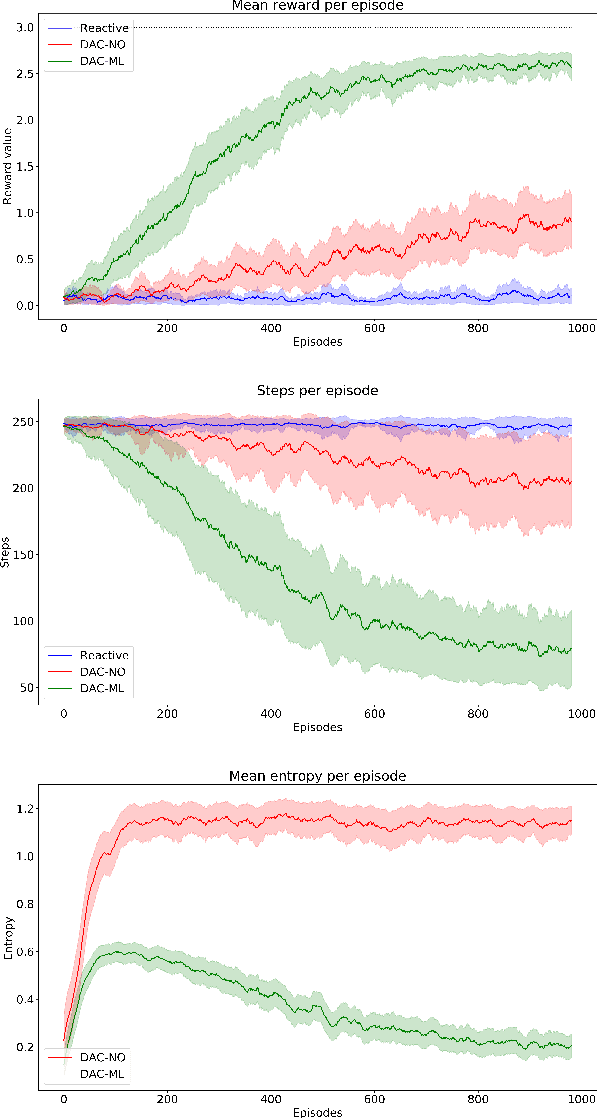
The sample-inefficiency problem in Artificial Intelligence refers to the inability of current Deep Reinforcement Learning models to optimize action policies within a small number of episodes. Recent studies have tried to overcome this limitation by adding memory systems and architectural biases to improve learning speed, such as in Episodic Reinforcement Learning. However, despite achieving incremental improvements, their performance is still not comparable to how humans learn behavioral policies. In this paper, we capitalize on the design principles of the Distributed Adaptive Control (DAC) theory of mind and brain to build a novel cognitive architecture (DAC-ML) that, by incorporating a hippocampus-inspired sequential memory system, can rapidly converge to effective action policies that maximize reward acquisition in a challenging foraging task.