 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Episodic Control
Dec 29, 2021
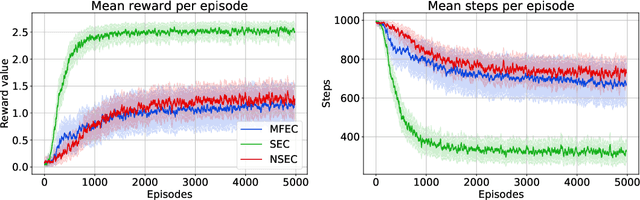
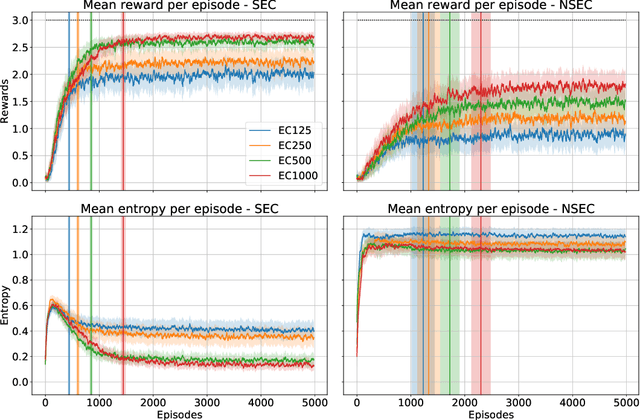
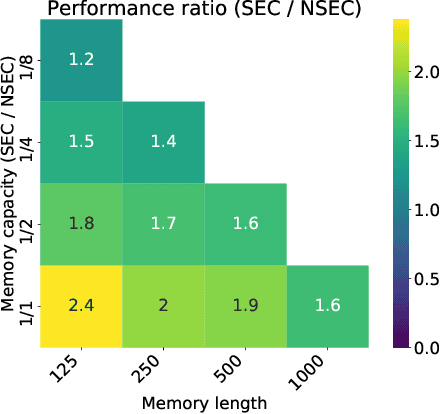
State of the art deep reinforcement learning algorithms are sample inefficient due to the large number of episodes they require to achieve asymptotic performance. Episodic Reinforcement Learning (ERL) algorithms, inspired by the mammalian hippocampus, typically use extended memory systems to bootstrap learning from past events to overcome this sample-inefficiency problem. However, such memory augmentations are often used as mere buffers, from which isolated past experiences are drawn to learn from in an offline fashion (e.g., replay). Here, we demonstrate that including a bias in the acquired memory content derived from the order of episodic sampling improves both the sample and memory efficiency of an episodic control algorithm. We test our Sequential Episodic Control (SEC) model in a foraging task to show that storing and using integrated episodes as event sequences leads to faster learning with fewer memory requirements as opposed to a standard ERL benchmark, Model-Free Episodic Control, that buffers isolated events only. We also study the effect of memory constraints and forgetting on the sequential and non-sequential version of the SEC algorithm. Furthermore, we discuss how a hippocampal-like fast memory system could bootstrap slow cortical and subcortical learning subserving habit formation in the mammalian brain.
Towards sample-efficient episodic control with DAC-ML
Dec 26, 2020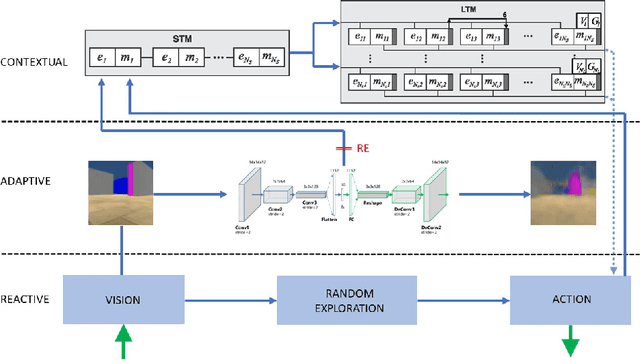

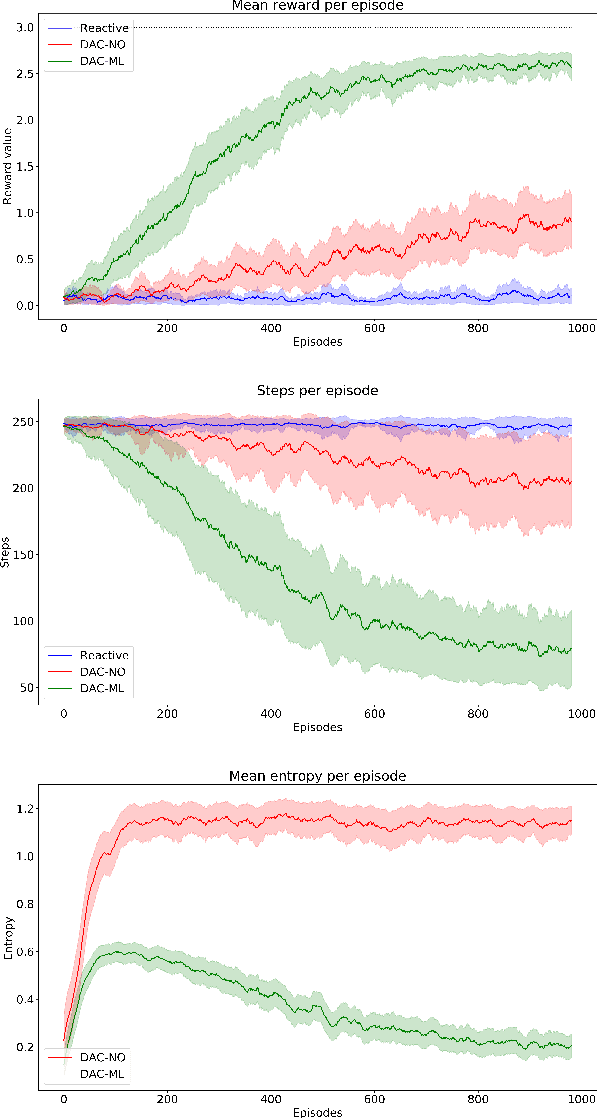
The sample-inefficiency problem in Artificial Intelligence refers to the inability of current Deep Reinforcement Learning models to optimize action policies within a small number of episodes. Recent studies have tried to overcome this limitation by adding memory systems and architectural biases to improve learning speed, such as in Episodic Reinforcement Learning. However, despite achieving incremental improvements, their performance is still not comparable to how humans learn behavioral policies. In this paper, we capitalize on the design principles of the Distributed Adaptive Control (DAC) theory of mind and brain to build a novel cognitive architecture (DAC-ML) that, by incorporating a hippocampus-inspired sequential memory system, can rapidly converge to effective action policies that maximize reward acquisition in a challenging foraging task.